







第一问:请介绍BOM有哪些对象
第一次被问到时,只知道window和navigator
- window:BOM的核心对象是window对象,它表示浏览器的一个实例。
- avigator:navigator 对象包含有关访问者浏览器的信息。
<div id="example">div>
<script>
txt = "浏览器代号: "
+ navigator.appCodeName + "";
txt+= "浏览器名称: "
+ navigator.appName + "";
txt+= "浏览器版本: "
+ navigator.appVersion + "";
txt+= "启用Cookies: "
+ navigator.cookieEnabled + "";
txt+= "硬件平台: "
+ navigator.platform + "";
txt+= "用户代理: "
+ navigator.userAgent + "";
txt+= "用户代理语言: "
+ navigator.systemLanguage + "";document.getElementById("example").innerHTML=txt;script>
- window.screen 对象包含有关用户屏幕的信息。
<body>
<h3>你的屏幕:h3>
<script>document.write("总宽度/高度: ");document.write(screen.width + "*" + screen.height);document.write("
");document.write("可用宽度/高度: ");document.write(screen.availWidth + "*" + screen.availHeight);document.write("
");document.write("色彩深度: ");document.write(screen.colorDepth);document.write("
");document.write("色彩分辨率: ");document.write(screen.pixelDepth);script>
body>
- location:对象用于获得当前页面的地址 (URL),并把浏览器重定向到新的页面。
一些实例:
location.hostname 返回 web 主机的域名
location.pathname 返回当前页面的路径和文件名
location.port 返回 web 主机的端口 (80 或 443)
location.protocol 返回所使用的 web 协议(http: 或 https:)
location.assign(url) : 加载 URL 指定的新的 HTML 文档。 就相当于一个链接,跳转到指定的url,当前页面会转为新页面内容,可以点击后退返回上一个页面。
location.replace(url) : 通过加载 URL 指定的文档来替换当前文档 ,这个方法是替换当前窗口页面,前后两个页面共用一个窗口,所以是没有后退返回上一页的
- history 对象包含浏览器的历史。
history.go(0); // go() 里面的参数为0,表示刷新页面
history.go(-1); // go() 里面的参数表示跳转页面的个数 例如 history.go(-1) 表示后退一个页面
history.go(1); // go() 里面的参数表示跳转页面的个数 例如 history.go(1) 表示前进一个页面
history.back() //方法加载历史列表中的前一个 URL。
history.forward() //方法加载历史列表中的下一个 URL。
第二问:以下代码都会输出什么呢?
var age = 29;
window.color = "red";
delete window.age;
delete window.color;
alert(window.name)
alert(window.age)
alert(window.color)
答案:
var age = 29;
window.color = "red";
// 在IE<9时抛出错误,在其他所有浏览器中都返回false
delete window.age;
// 在IE<9时抛出错误,在其他所有浏览器中都返回true
delete window.color;
alert(window.name) // ''
alert(window.age) //29
alert(window.color) //undefined
使用var语句添加的window属性有一个名为[[configurable]]的特性,这个特性的值被设置为false,因此这样定义的属性不可以通过delete操作符删除. window对象中本身就有个name属性,window.name 表示当前window的名称 age没被删除,所以输出29,而color被删除了。
第三问:你知道间接调用和超时调用吗?
javascript是单线程语言,但它允许通过设置超时值setTimeout和间歇时间值setInterval来调度代码在特定的时刻执行。前者是在指定的时间过后执行代码,而后者则是每隔指定的时间就执行一次代码。
- 超时调用使用window对象的setTimeout()方法,它接受两个参数:要执行的代码 和 以毫秒表示的时间。第一个参数可以是包含javascript语句的字符串(不推荐使用),也可以是函数。调用setTimeout()之后,该方法会返回一个数值ID,表示超时调用。
// 推荐
setTimeout(function(){
alert("Hello");
},1000);
// 不推荐
setTimeout("alert('Hello')",1000);
- 间歇调用与超时调用类似,只不过它会按照指定的时间间隔重复执行代码,直至间歇调用被取消或者页面被卸载。设置间歇调用的方法是setInterval(),它会接受的参数与setTimeout()相同:因为在不加干涉的情况下,间歇调用将会一直执行到页面卸载。(ps:建议少用setInterval(),可以用setIimeout()代替)
第四问 你刚刚说建议少用setInterval(),可以用setIimeout()代替,为什么呢?
对于这道题,要有 事件循环机制的只是储备,建议先看看:这一次,彻底弄懂 JavaScript 执行机制(别还不知道什么是宏任务,什么是微任务)
之所以说要替换,是因为setInterval的缺点
再次强调,定时器指定的时间间隔,表示的是何时将定时器的代码添加到消息队列,而不是何时执行代码。所以真正何时执行代码的时间是不能保证的,取决于何时被主线程的事件循环取到,并执行。
setInterval(function, N)
//即:每隔N秒把function事件推到消息队列中
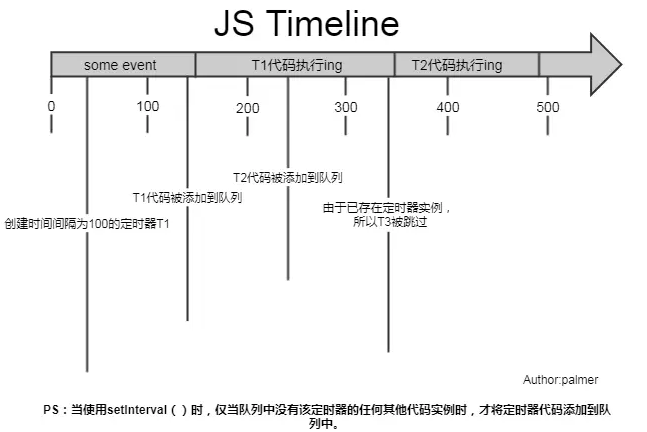
上图可见,setInterval每隔100ms往队列中添加一个事件;100ms后,添加T1定时器代码至队列中,主线程中还有任务在执行,所以等待,some event执行结束后执行T1定时器代码;又过了100ms,T2定时器被添加到队列中,主线程还在执行T1代码,所以等待;又过了100ms,理论上又要往队列里推一个定时器代码,但由于此时T2还在队列中,所以T3不会被添加,结果就是此时被跳过;这里我们还可以看到,T1定时器执行结束后马上执行了T2代码,所以并没有达到定时器的效果。
综上所述,setInterval有两个缺点:
- 使用setInterval时,某些间隔会被跳过;
- 可能多个定时器会连续执行;可以这么理解:每个setTimeout产生的任务会直接push到任务队列中;而setInterval在每次把任务push到任务队列前,都要进行一下判断(看上次的任务是否仍在队列中)。
因而我们一般用setTimeout模拟setInterval,来规避掉上面的缺点。
第五问:既然如此那该怎么用setTimeout模拟setInterval呢
setTimeout模拟setInterval,也可理解为链式的setTimeout。
setTimeout(function () {
// 任务
setTimeout(arguments.callee, interval);
}, interval)
上述函数每次执行的时候都会创建一个新的定时器,第二个setTimeout使用了arguments.callee()获取当前函数的引用,并且为其设置另一个定时器。好处:
- 在前一个定时器执行完前,不会向队列插入新的定时器(解决缺点一)
- 保证定时器间隔(解决缺点二)
警告:在严格模式下,第5版 ECMAScript (ES5) 禁止使用 arguments.callee()。当一个函数必须调用自身的时候, 避免使用 arguments.callee(), 通过要么给函数表达式一个名字,要么使用一个函数声明.
第六问:上面既然提到了hash和history,那就谈下两者的区别
hash
即地址栏 URL 中的 # 符号 hash 虽然出现在 URL 中,但不会被包括在 HTTP 请求中,对后端完全没有影响,因此改变 hash 不会重新加载页面。
history
利用了 HTML5 History Interface 中新增的 pushState() 和 replaceState() 方法 它们执行修改时,虽然改变了当前的 URL,但浏览器不会立即向后端发送请求。通过history api,我们丢掉了丑陋的#,但是它也有个问题:不怕前进,不怕后退,就怕刷新,f5,(如果后端没有准备的话),因为刷新是实实在在地去请求服务器的。在hash模式下,前端路由修改的是#中的信息,而浏览器请求时不会将 # 后面的数据发送到后台,所以没有问题。但是在history下,你可以自由的修改path,当刷新时,如果服务器中没有相应的响应或者资源,则会刷新出来404页面。
关于此模块较少,后续补充。。。















 1467
1467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









