





这里介绍了一种称为特征区分对齐(FD-Align)的微调方法。该方法旨在通过在微调过程中保持虚假特征的一致性来增强模型的通用性。实验结果验证了该方法对于 ID 和 OOD 任务的有效性。经过微调后,该模型可以与现有方法无缝集成,从而提高性能(非常抱歉,本文简介错误),缩减类别空间以增强半监督学习中的置信度
大佬发表了 "Shrinking Class Space for Enhanced Certainty in Semi-Supervised Learning"。在本工作中,我们通过自适应地缩减类别空间、排除混淆类别,使得模型对于原本不确定的样本变得确定,以增加无标签图像的利用率以及更安全地学习较为noisy的不确定样本。
文章链接:https://arxiv.org/abs/2308.06777
代码链接:https://github.com/LiheYoung/ShrinkMatch
半监督学习希望从部分的有标签图像和较多的无标签图像上学得更好的表征,核心在于对无标签图像的利用。最近的工作仍然follow经典的FixMatch系列的做法,即模型在较为干净的无标签图像上预测出伪标签,然后再对该图像进行更强的数据扰动后学习对应的伪标签。
动机
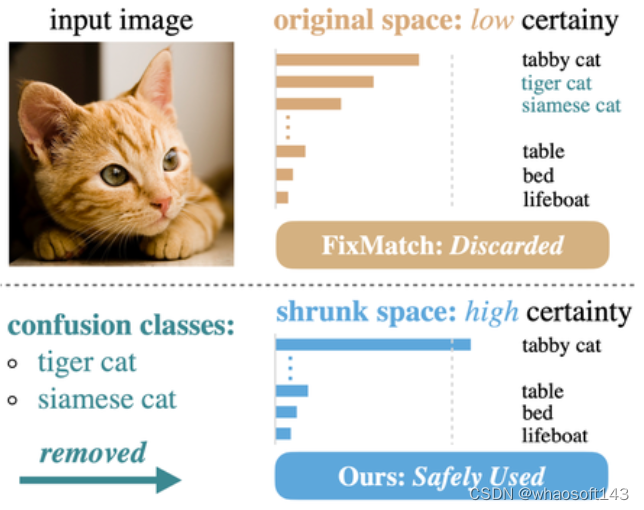
Our Motivation
为了学习尽可能可靠的伪标签,FixMatch会根据无标签图像的置信度(i.e., softmax输出的最大值)做一个筛选,低于预设阈值(e.g., 0.95)的样本会被丢弃,即在loss计算中会被忽略。
尽管此方法确保了无标签样本的可靠性,但同时也严重降低了无标签的利用率,我们发现在CIFAR-100数据集上,有大约20%的无标签样本没有得到利用,因此我们希望更加安全的利用这些可能比较noisy的无标签样本。
进一步观察这些置信度低的样本,模型往往会对少数的几个类别混淆,如上图所示,模型会不确定该图像是具体属于tabby cat、tiger cat还是siamese cat。换句话说,正是这种在top类别上的混淆导致了模型的低置信度。但从另一方面看,虽然模型不确定该图像属于具体哪一种猫,但很确定不属于table、bed、lifeboad等类别。于是,我们想到为模型排除掉容易混淆的类别(上述的tiger cat和siamese cat),只保留最确定属于的类别(上述的tabby cat)以及很确定不属于的类别(上述的table、bed、lifeboat等)。当部分混淆类别被移除后,在新的缩减后的空间中,模型会变得确定这个图像属于tabby cat,而非其他不相关的类别。于是,我们可以要求模型在这个新的空间里“安全地”学习该图像属于tabby cat。
方法
Main Pipeline
有了上述的motivation后,具体的实现其实是很简单的。baseline方法FixMatch是在初始的C类空间里是要求强增广的图像和弱增广的图像的预测结果一致,用的损失函数是hard cross entropy loss。而我们会对置信度低的无标签图像自适应检测需要移除哪些混淆类别,移除了N类后,在(C-N)类空间里约束强增广和弱增广图像的预测结果一致,用的仍然是hard CE loss。因为我们保留了最大的类别,这里新类别空间的伪标签其实和原始空间是同一个类别,只是参与训练的类别变少了。下面是我们方法的pipeline:
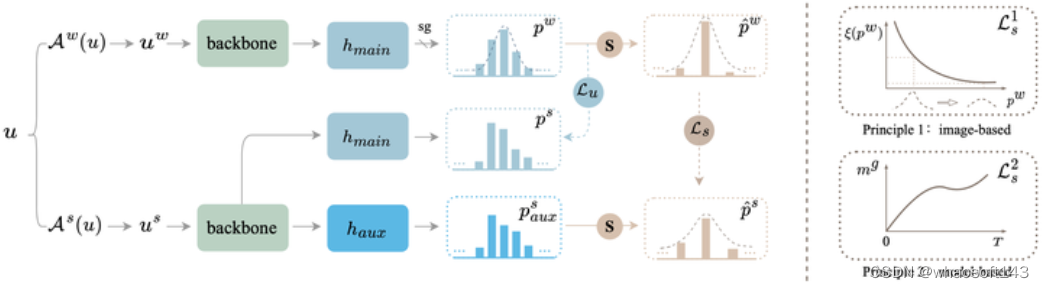
ShrinkMatch示意图,S表示shrinking class space。
如何确定需要移除的类别: 对于每一个不确定样本,我们从第二大的类别logits开始尝试移除,当移除后,在(C-1)类上重新计算softmax,如果此时置信度已经超过预设的阈值,则移动停止,只移除第二大的类别即可;如果仍然没有超过阈值,则继续移除第三大的类别logits.... 直至重新计算的置信度能够超过阈值。
Auxiliary classifier to learn uncertain samples

Re-weighting the uncertain loss
我们观察到模型在训练初期对于第一大类的判断是很noisy的,因此我们给uncertain loss额外加了一个考虑到模型状态的权重。直观来看,初期这个权重应该比较小,后期应该比较大,最简单的做法就是做一个线性的scheduling。然而实际上,模型的状态并不是线性提升的,一般开始时提升很快,后面转为慢慢稳步的提升。为了更好的刻画模型状态的改变,我们用batch-wise certain samples的比例作为一个指标。简单来说,如果一个batch中总共有B个样本,而模型认为其中K个是certain的,那么这时候模型的状态指数就是K/B,我们将这个量作为uncertain loss的权重。
此外,不同uncertain sample的可靠程度也不一样。比如不确定样本a的置信度是0.9,而不确定样本b的置信度是0.6,虽然都不确定,但样本a应该被赋予更大的权重去学习。因此,我们也给uncertain loss加入了置信度这个权重,这是image-wise的权重,而上面模型状态是作为iteration(batch)-wise的权重。
FAQ
Q1: 这和不丢弃直接按照最大的类来学有什么区别?
A1: 如果直接按照概率最大的类别来学,hard CE loss会把其他类别的概率都朝着0去优化。然而,对于这种很容易混淆的样本,可能第二大类、甚至第三大类才是对的,这种情况下会引入很大的noise,而我们通过移除掉这些潜在的正确类别,不往任何方向(最小概率0或最大概率1)优化反而可以避免这种noise。
Q2: 那为什么不直接用soft label来学?
A2: Soft label仍然会抑制除最大类外的其他类,而如果正确的类别没有出现在最大类上,那这个学习也是noisy的。此外,我们在实验中展示了用soft label甚至没有直接丢弃这些uncertain samples(FixMatch的做法)的效果好。
Q3: 那这些比较混淆的类怎么学呢,不就学不到了吗?
A3: 这些类别会在其他一些图像上出现在top-1 class的位置上,因此也可以获得学习。
Q4: 如果最大的类别是错的呢?那把它的概率往1的方向优化岂不是也是noisy的?
A4: 最大类当然可能是错的,特别是对于这些置信度很低的样本,然而我们在文章有展示,即使这个类是错的,他也以很大的概率会和GT class属于同一个superclass,因此学习这个类别也是有收益的。需要注意的是,我们并不尝试修正最大的类别。
Q5: 不断的移除混淆类别直至模型不混淆,那这还有什么信息量呢,模型还有什么可学的呢?
A5: 我们判断是否属于混淆类别是在弱增广图像的预测结果上做的,然而我们最后学习的时候会对图像施加很重的强增广,模型会重新有一些混淆的难以判断的类别,因此这种学习也是有益的。
Experiments
小数据集:CIFAR-100, and toy examples: CIFAR-10, STL-10, SVHN
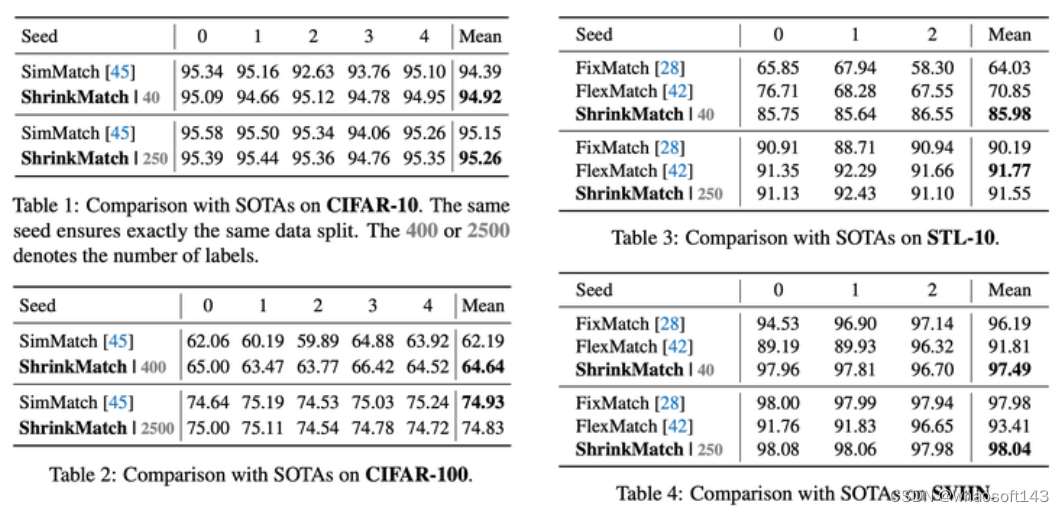
Results on CIFAR-10, CIFAR-100, STL-10, and SVHN
可以看到,我们的方法在CIFAR-100这种类别空间较大的数据集上的增益是比较大的,在400 labels上可以比SimMatch提升2.5%左右。
较大数据集: ImageNet-1K
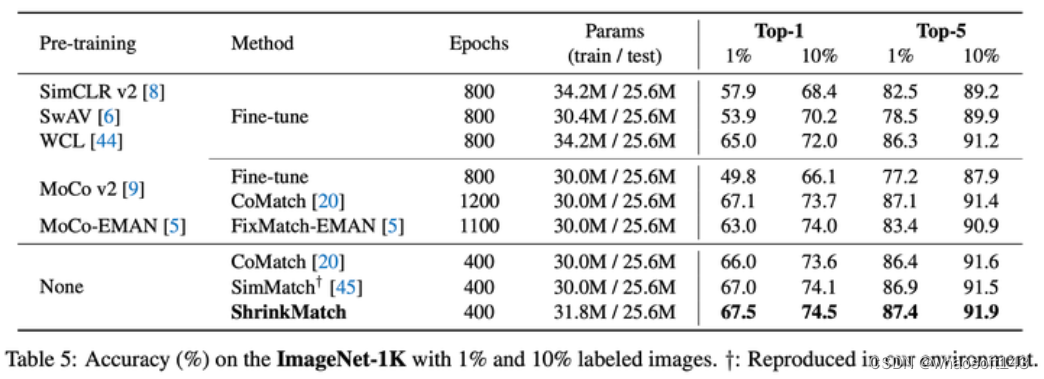
Results on ImageNet
在ImageNet上我们的baseline是SimMatch,提升没有我们想象的那么大,猜测的重要原因之一是,受资源和时间所限(8xA100(80G)需要训练7.5天),这个实验我们只跑了一次,没有调整任何SimMatch的超参数,也直接把我们的uncertain loss加在了原有的losses上。
一些统计量的可视化

在CIFAR-100上移除的混淆类别的数量(图(a)),不同loss的大小(图(b)),不确定样本的比例(图(c))
如果需要复现方法,作者提供了文章中所有表格的数据对应的实验https://github.com/LiheYoung/ShrinkMatch/tree/main/training-logs
最后感谢大佬















 229
229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









