








简介
题目:《Shrinking Class Space for Enhanced Certainty in Semi-Supervised Learning》,ICCV 2023
缩小类空间以提高半监督学习的确定性
日期:2023.8.13
单位:香港大学、南京大学、上海AI Lab、悉尼大学、东南大学
论文地址:https://arxiv.org/abs/2308.06777
GitHub:https://github.com/LiheYoung/ShrinkMatch
- 作者
Lihe Yang

个人主页:https://liheyoung.github.io/

高引用:
《Pascal:ST++: 让 Self-Training 更好地用于半监督语义分割》 (CVPR’22)
简介:在半监督语义分割领域重新思考了传统的多阶段自训练(self-training)范式,并提出两点关键的改进策略
《UniMatch: 重新审视半监督语义分割中的强弱一致性》(CVRP’23)
简介:重新审视了半监督语义分割中的“强弱一致性”方法。我们首先发现,最基本的约束强弱一致性的方法FixMatch即可取得与当前SOTA相当的性能。受此启发,我们进一步拓展了FixMatch的扰动空间,以及利用双路扰动更充分地探索原扰动空间。
其他作者:
赵振,个人主页:http://zhaozhen.me/

祁磊,个人主页:http://palm.seu.edu.cn/qilei/

乔宇
通讯作者:
史颖欢,个人主页:https://cs.nju.edu.cn/shiyh/index.htm
Hengshuang Zhao

- 摘要
半监督学习由于其在组合未标记数据方面的成功而引起了人们的广泛关注。为了减少潜在的不正确伪标签,最近的框架大多设置了一个固定的置信阈值来丢弃不确定的样本。这种做法确保了高质量的伪标签,但导致整个未标记集的利用率相对较低。在这项工作中,我们的关键见解是,只要检测并删除top1类的混淆类,这些不确定的样本就可以变成特定的样本。基于此,我们提出了一种新的方法ShrinkMatch来学习不确定样本。对于每个不确定的样本,它自适应地寻找一个缩小的类空间,该类空间仅包含原始的前1类以及剩余的不太可能的类。由于在该空间中去除了混淆的置信度,因此重新计算的top-1置信度可以满足预定义的阈值。然后,我们在收缩空间中的一对强和弱增广样本之间施加一致性正则化,以争取判别表示。此外,考虑到不确定样本之间的可靠性变化以及训练过程中模型的逐步改进,我们相应地为我们的不确定损失设计了两个重新加权原则。我们的方法在广泛采用的基准上表现出令人印象深刻的性能。
之前的工作中,通常简单地设置了一个固定的置信阈值来丢弃潜在的不可靠样本。这种简单的策略有效地保留了高质量的伪标签,然而,它也导致整个未标记集的利用率较低。
ShrinkMatch希望以一种信息丰富但又安全的方式充分利用以前不确定的样本。
提出,对于每个不确定的样本,检测并删除top1类的混淆类,自适应地寻找一个缩小的类空间,该类空间仅包含原始的前1类以及剩余的不太可能的类。由于去除了混淆的置信度,新计算的top-1置信度可以满足预定义的阈值
然后,在收缩空间中的一对强和弱增广样本之间施加一致性正则化

Fig1:说明我们的动机。由于前1类的混淆类,确定性无法达到预定义的阈值(灰色虚线)。FixMatch丢弃这种不确定的样本。然而,我们的方法检测并删除混淆类以增强确定性,然后充分安全地利用所有未标记的图像。
即使预测的top 1类与groundtruth标签不完全一致,它们也大多属于同一个超类

Fig2:具有400个标签的CIFAR-100上的伪标签精度。我们强调,即使对于不确定的样本,它们的前1预测在超类空间(20个类)中也具有高精度。这种精度甚至可以与原始类空间中精心选择的某些样本相媲美。
工作重点
-
我们首先指出,低确定性通常是由一小部分混淆类引起的。为了增强确定性,我们建议通过自适应地检测和去除前1类的混淆类来缩小原始类空间,以使其在新空间中变得确定。
-
我们设法从两个角度重新评估了不确定损失:不同不确定样本之间基于图像的不同可靠性,以及随着训练的进行,基于模型的状态逐渐改善。
-
我们提出的ShrinkMatch在公认的基准上建立了新的最先进的结果。
方法

Fig3:我们提出的ShrinkMatch概述。我们的动机是充分利用最初不确定的样本。“S”表示缩小类空间。以完全自动和实例自适应的方式检测和去除前1类的混淆类,以构建前1类确定的收缩空间。Lu是原始的确定损失,而Ls计算的是收缩类空间中的不确定损失。我们添加了一个辅助头haux来学习新的空间。
在右边,我们基于两个原则进一步改写了L。原则1(基于图像):可靠性更高的图像预测更受重视。原则2(基于模型的):我们在训练期间跟踪模型状态以进行重新加权。
无监督的损失:

其中Bu是未标记图像的批量大小,τ是预定义的阈值。ξ(pwk)通过ξ(·) = max(σ(·))计算logits pwk的置信度,其中σ是softmax函数。H表示两个分布之间的一致性正则化。它通常是交叉熵损失。此外,利用规则的交叉熵损失来学习标记图像,以获得监督损失Lx。
总损失为:

- 寻找缩小的类空间
(不受人类任何先验知识的影响,例如类关系,也不需要任何额外的超参数)
选择继承预定义的置信阈值作为标准。具体来说,我们首先按降序对预测的logits进行排序,以获得类的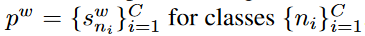 ,其中
,其中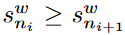 。在缩小的空间中,保留最初的top1类,然后找到一组可能性较小的类
。在缩小的空间中,保留最初的top1类,然后找到一组可能性较小的类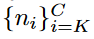 ,通过对K执行两个约束:
,通过对K执行两个约束: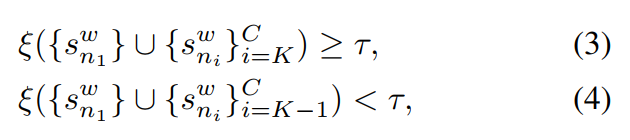
- 在缩小类空间中学习
遵循了从弱到强一致性正则化的流行做法。对强增强图像的相应收缩的预测被强制以匹配对弱增强图像的预测
采用了与hmain共享骨干的辅助MLP头haux来处理这个辅助优化目标,^ ps从haux的预测中收集的(^ pw仍然来自hmain)。这种修改使我们的特征提取器能够获得更具鉴别力的表示,同时不影响主头部的预测。(haux仅用于训练,不会给测试阶段带来负担)
- 重新加权不确定损失
尽管上述不确定损失有效,但仍存在两个主要缺点。
(1) 一方面,它忽略了前1类在不同的不确定图像中的不同可靠性。例如,假设在原始空间中具有softmax预测[0.8,0.1,0.1]和[0.5,0.3,0.2]的两个不确定图像u1和u2,它们在收缩空间中不应该被同等对待。top-1置信度为0.8的u1比u2更有可能是真的,因此应该更加关注。
(2)另一方面,它忽略了随着训练的进行,模型性能逐渐提高。具体地说,在训练一开始,预测就非常嘈杂,甚至是随机的。然后在以后的阶段,预测变得越来越可靠。因此,不应平等对待不同训练阶段的不确定预测。
因此,我们针对这两个问题进一步设计了两个重新加权原则
- 基于图像的各种可靠性的重新加权:ξ(pwk)
- 基于模型的逐步改善状态的重新加权:mg
ξ(pwk):直接用每个不确定图像在原始类空间中的top1置信度ξ(pwk)重新加权其不确定损失
mg: 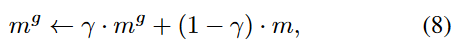
全局特定比率mg被初始化为0,并在每次训练迭代中通过以上方式累积,
使用未标记集的特定比率作为模型状态的指标。在每次迭代时跟踪特定的比率,并以指数移动平均(EMA)方式全局累积。形式上,单个小批量中的特定比例由下式给出: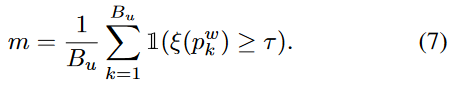
- 缩小类空间的Loss:

训练
-
基线
使用**FixMatch+分布比对(distribution alignment, DA)**作为除ImageNet和SVHN之外的所有数据集的基线。
在ImageNet上,在SimMatch上构建;在SVHN上,丢弃了DA。 -
超参数。
根据现有技术,Wide ResNet-282、WRN-28-8、WRN-37-2和WRN-28-2分别用于CIFAR-10、CIFAR-100、STL-10和SVHN。ResNet-50用于ImageNet。不确定样本的辅助头是一个3层MLP。
在ImageNet上,设置Bu=64×5;其他数据集,Bu=64 x 7。所有数据集的标记批次大小均为64。在ImageNet上,训练了400个epoch,在其他数据集上,训练了220次迭代。
对于具有余弦调度器的所有数据集,初始学习率被设置为0.03。特别在ImageNet上,预热了5个epoch。在STL-10和SVHN上,Lu中的一致性正则化H是硬交叉熵(CE)损失;在CIFAR-10/100和ImageNet上,继SimMatch和CoMatch之后,它被修改为软交叉熵损失。
在提出的Ls中的^H只是硬CE损失。两个无监督损失的权重λu在ImageNet上设置为10,在其他情况下设置为1。
置信阈值τ在ImageNet上为0.7,在其他情况下为0.95。我们的全局特定比率 mg和教师参数之间的共享动量系数γ为0.999。按照惯例,教师模式只在最后评估时保留。
实验
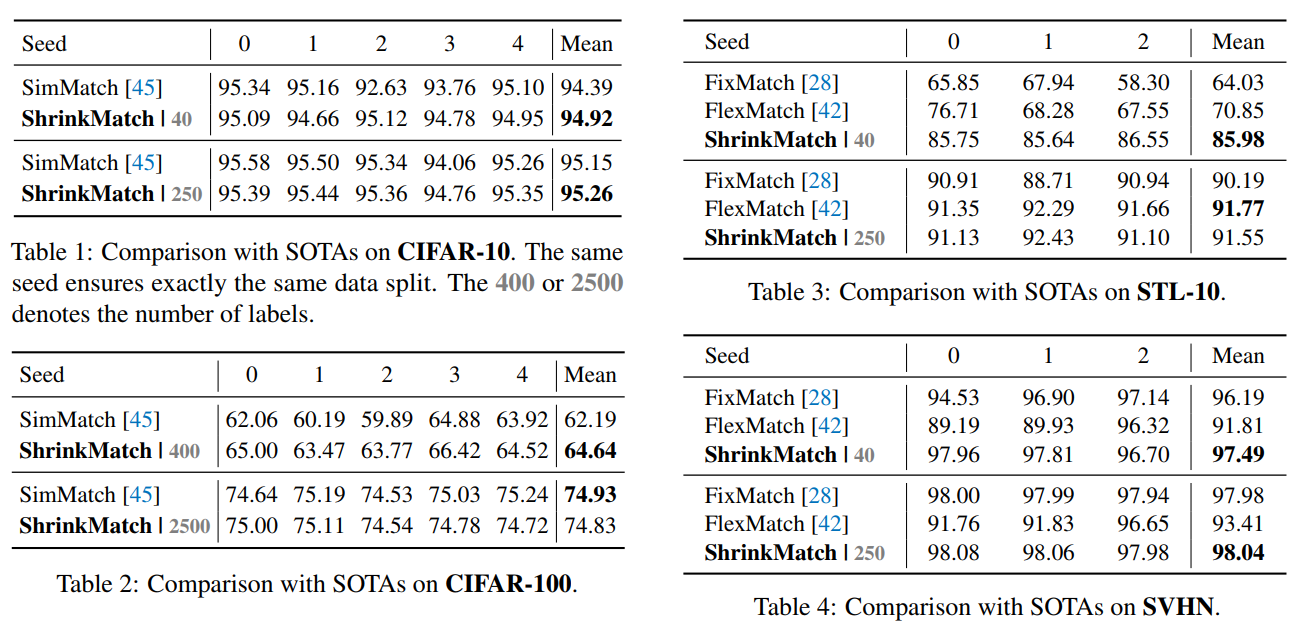
Tab1/2/3/4:与CIFAR-10/STL-10/CIFAR-100/SVHN数据集上与SOTA的比较。相同的seed确保完全相同的数据分割。400或2500表示标签的数量。
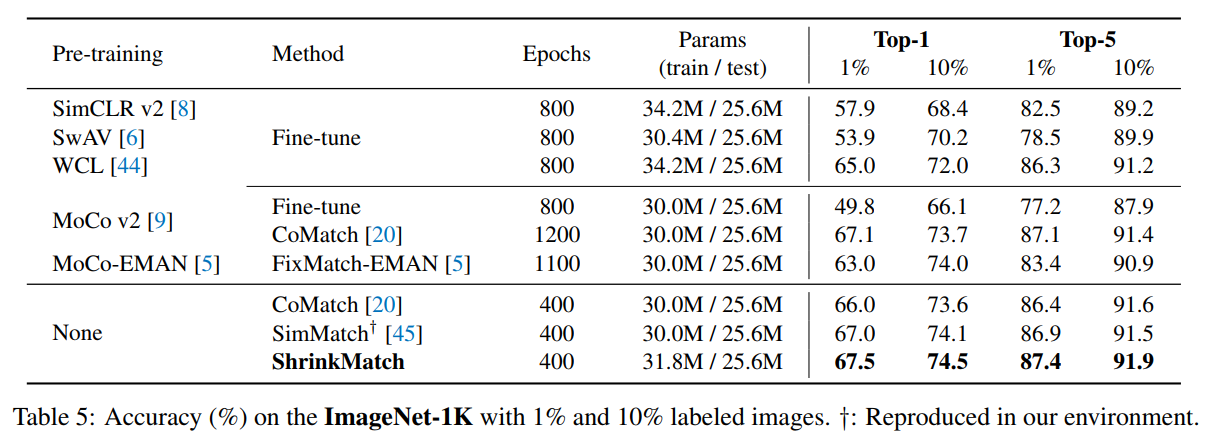
Tab5:ImageNet-1K上1%和10%标记图像的准确度(%)。†:在我们的环境中复制。
Ablation

Tab6/7:ShrinkMatch在CIFAR-100/STL-0上的消融实验

Tab8:消融研究两个重新加权原则的有效性。由于随机性,“均值”结果更有说服力。LS是线性调度的缩写,它线性地增加了损失权重。

Tab9:消融研究的不同选择学习不确定样本。(1) 是否缩小类空间(shrink),(2)是否使用辅助磁头(Aux head),以及(3)使用硬标签(H)或软标签(S)。实验1是我们在不使用不确定图像的情况下的基线。实验8和9是直接学习不确定样本的实验,这些样本非常嘈杂。

Tab10置信阈值的消融实验。
- 可视化
(这篇文章没有图片结果可视化展示,也没给代码)
Fig4a:随着训练的进行,需要移除的混淆类要少得多,以形成一个自信的缩小类空间。
Fig4b:重新加权后,不确定损失与确定损失的大小相似,这可以避免在早期训练阶段主导梯度
Fig4c:显示了每个小批量中不确定样本的比例。可以看出,即使在整个训练过程的中间,ImageNet和CIFAR100上仍分别有40%和30%左右的不确定样本。因此,利用这些样本的适当方法是必要的,而且肯定是有益的。
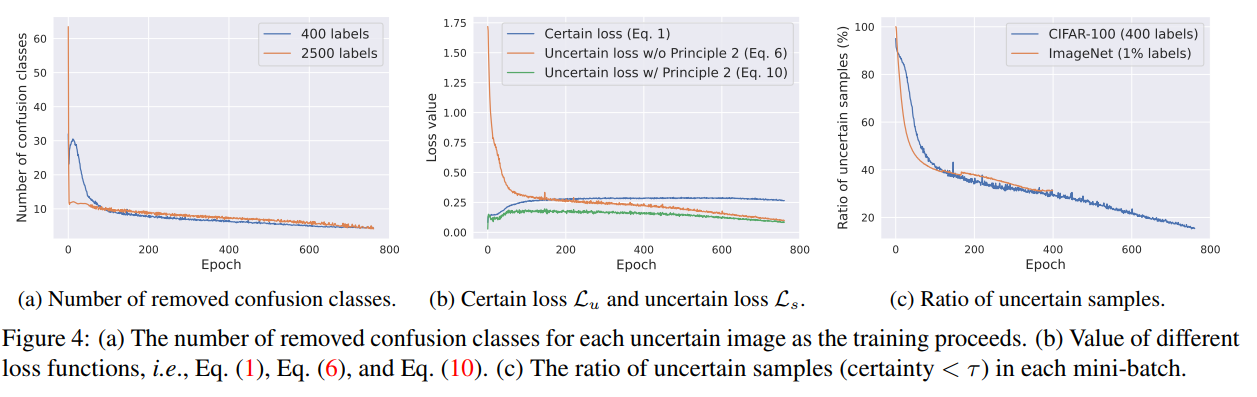
Fig4:(a) 随着训练的进行,每个不确定图像的消除混淆类的数量。(b) 不同损失函数的值,即方程(1)、方程(6)和方程(10)。(c) 每个小批量中不确定样本的比例(确定度<τ)。

Fig5:全局特定比率mg的可视化。
- 总结(conclution)
在这项工作中,我们的目标是在半监督学习中充分利用不确定样本。我们指出,低确定性通常是由一小部分混淆类引起的。在此基础上,我们提出了一种称为ShrinkMatch的新方法来自动检测和删除混淆类,以构建一个缩小的类空间,其中前1个类是确定的。在置信新空间中强制执行弱到强一致性正则化。此外,根据不同不确定样本的可靠性和模型的逐步改进状态,我们设计了两个辅助不确定损失的重新加权原则。因此,我们的方法在公认的基准上建立了新的最先进的结果。














 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









