






概述
搭建mha无非就是为了做高可用,所以我们搭建完肯定要测试一下故障时是否能够自动切换~
下面简单介绍一下故障切换过程。
1、模拟故障
在 master 节点关闭 mysql 服务,模拟主节点数据崩溃
systemctl stop mysqld
其实第一次测试没必要跟我一样干掉数据文件,要不恢复起来还是挺麻烦。

2、在 manger 节点查看日志 tail -200 /etc/mha_master/app1/app1.logmasterha_check_status -conf=/etc/mha_master/app1.conf
……
app1: MySQL Master failover 172.16.20.161(172.16.20.161:3306) to 172.16.20.176(172.16.20.176:3306) succeeded
表示 manager 检测到172.16.20.161节点故障, 而后自动执行故障转移, 将172.16.20.176提升为主节点。
注意,故障转移完成后, manager将会自动停止, 此时使用 masterha_check_status 命令检测将会遇到错误提示:mha is stopped(2:NOT_RUNNING).

ps:注意了,在故障发生的时候一定要盯着MHA的日志,看一下这时候MHA究竟在做什么,这样大家可以更清晰理解MHA切换的原理,这里我就不写了,只提意见。。。
3、VIP漂移
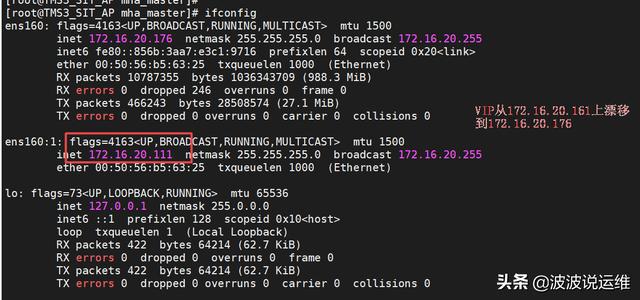
4、观察配置文件app1.conf
其实第2、3、4都是在故障的时候MHA切换时我们需要去留意的,观察就可以了。
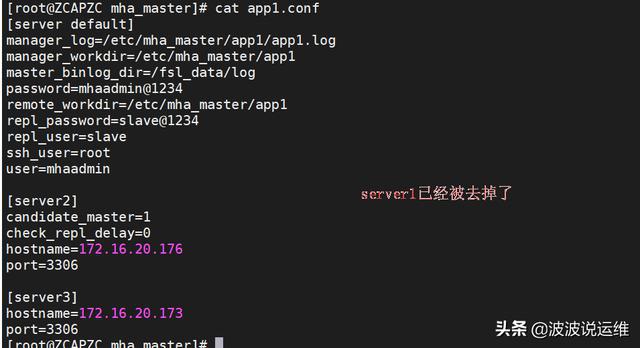
5、提供新的从节点以修复复制集群
原有 master 节点故障后,需要重新准备好一个新的 MySQL 节点。基于来自于master 节点的备份恢复数据后,将其配置为新的 master 的从节点即可。注意,新加入的节点如果为新增节点,其 IP 地址要配置为原来 master 节点的 IP,否则,还需要修改 mha.cnf 中相应的 ip 地址。随后再次启动 manager ,并再次检测其状态。这里以刚刚关闭的那台主作为新添加的机器,来进行数据库的恢复。
如果是GTID整体过程还是差不多的,不过一些配置还是要注意。
systemctl start mysqldstop slave;change master to master_host='172.16.20.176', \master_user='slave', master_password='slave@1234',\master_log_file='mysql-bin.000003',master_log_pos=1832;start slave;show slave status\G;
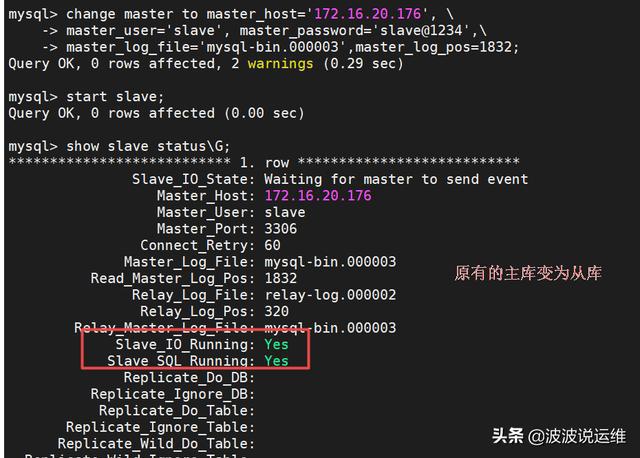
6、修改app1.conf配置文件
修改server部分,IP调整后重新做检测
[server default]#设置manager的工作目录manager_workdir=/etc/mha_master/app1#设置manager的日志manager_log=/etc/mha_master/app1/app1.log#设置master保存binlog的位置,以便MHA可以找到master的日志master_binlog_dir=/fsl_data/log#mha管理用户user=mhaadmin#mha管理密码password=mhaadmin@1234#设置远端mysql在发生切换时binlog的保存位置remote_workdir=/tmp#设置复制用户的密码repl_password=slave@1234#设置复制环境中的复制用户名repl_user=slave#设置ssh的登录用户名ssh_user=root[server1]hostname=172.16.20.176port=3306[server2]hostname=172.16.20.161port=3306#设置为候选master,如果设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中事件最新的slavecandidate_master=1#默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的mastercheck_repl_delay=0[server3]hostname=172.16.20.173port=3306 7、新节点提供后再次执行检查操作
到这里就完成了整个MHA故障切换工作了!
masterha_check_repl -conf=/etc/mha_master/app1.confmasterha_check_status -conf=/etc/mha_master/app1.conf--如果报错,则再次授权,若没有问题,则启动 managermasterha_manager --conf=/etc/mha_master/app1.conf --remove_dead_master_conf \--ignore_last_failover --ignore_binlog_server_error>/etc/mha_master/app1/app1.log 2>&1&--再次检查masterha_check_status -conf=/etc/mha_master/app1.conf
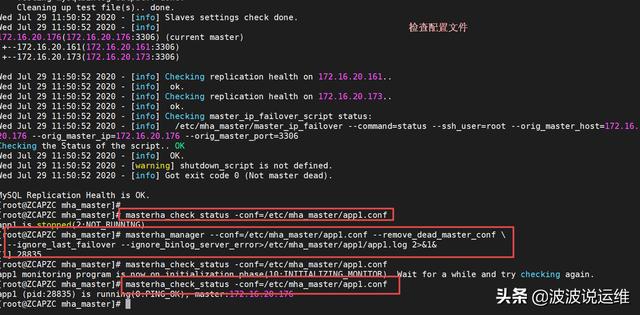
以上就是MHA相关内容了,大家按上面走基本都可以入门了。
后面会分享更多devops和DBA方面内容,感兴趣的朋友可以关注一下~















 122
122











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









