






MemSQL 自称是最快的内存数据库。目前已发布了2.5版本。
MemSQL 具有以下特点
1 高效的并行,尤其是分布式的MemSQL.
2 高效的并发,采用lock-free的内存数据结构skip list 和hash.支持MVCC.
3 查询执行计划编译成C++的形式,可以高效执行并且可以重用
4 支持数据的冗余存储,提高可用性
5 支持重放事物日志的复制
6 支持JSON格式的数据处理
下面来看看Memsql的share-nothing分布式架构
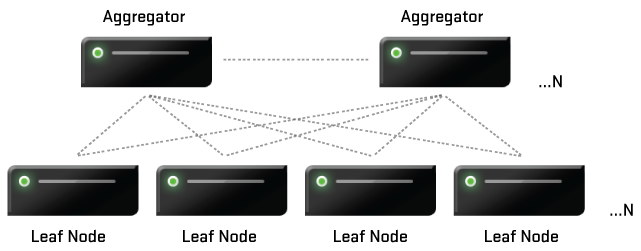
两层架构:分为aggregator 和 leaf
Aggregator 存储元数据,负责分发sql给leaf,然后综合leaf的查询结果。aggregator可以有多个,其中有一个为主aggregator。主aggregator 还可以执行DDL和负责Leaf的auto-failover.其它普通aggregator 则不行。当主aggregator 失效,可以从其它普通aggregator 选择一个通过sql命令设置为主aggregator 。
Leaf上存储真正的数据,数据通过主键hash存储到各个leaf节点,leaf之间的数据均匀分布不会倾斜。目前还不支持范围分区。在建库时指定分区数,分区数应该为leaf节点的整数倍,一般设为8倍。每个leaf都是一个分库,分取数据存储在分库的表中。表只持二级索引,同时支持以主键为前缀的唯一索引。
两种表类型:
参照表(reference table): 数据分布在主aggregator和每个leaf节点。每个节点的数据都是完整的(没有分区)。参照表同过复制从主aggregator向每个leaf节点同步数据。另外参照表的写只能在主aggregator进行。
分布表 (sharded table):数据通过hash分片存储在每个leaf节点,每个leaf节点只有部分数据。
数据冗余:
可用组(availability group),每个组是一些leaf的集合。组与组之间是冗余存储的。目前最多支持两个组。以两个组为例,每个组都包含完整数据,每个分区表在两个组都有一分copy.可以基于电力和网络条件进行分组。
扩展性:
支持动态增删Leaf节点,但需要执行rebalance partitions命令来重新分布分区数据。rebalance 操作都是在线进行的,即操作过程中不影响数据正常访问。rebalance操作的单位是库,最小粒度是 partition.
下面是leaf节点状态变化图

MemSQL兼容mysql协议。支持mysql的ODBC,JDBC及其它语言接口。
一些思考:
1 支持mysql 协议,使的memsql学习成本较低,同时mysql的ODBC,JDBC可以直接拿来使用,提高了可用性,同时也减少了MemSQL自身的开发成本。
2 redundancy_level目前最高支持2.集群中出现两个Leaf节点同时故障的可能性不是很低。后需应该支持3及以上的level;在redundancy_level为2的情况下,如果一个leaf节点出现故障,对应的冗余节点负载一般会提升一倍,负载不均衡,很可能造成新的故障。
3 availability group是一个很好的分组方式,可以将不同的组放在不同的机房,提高可用性。
4 对于reblance table 操作,可以做到在线的方式进行,感觉难度比较大,但文档中没有看到更详细的实现说明。
参考:















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









