






目前,海量数据处理主要存在二个问题:大规模计算(cpu+mem)、海量数据存储(disk),而Hadoop被专门设计用来针对海量数据的处理,它通过分布式文件系统解决海量数据的存储问题,组织成千上万个计算节点来共同完成一个任务解决了大规模计算问题。Hadoop的核心是MapReduce,而不是分布式文件系统HDFS,这是因为MapRduce所依赖的存储系统并不依赖于任何一个文件系统,甚至是分布式文件系统。MapReduce设计的核心思想map-reduce计算模型,即将任何作业的处理分为两个阶段——map阶段和reduce阶段,在每一个阶段都由若干个机器节点(普通PC)共同协作完成,每一个机器节点只负责整个任务的一部分,这样做就使的任务的处理时间随着工作节点数量的增加而呈线性减少。这中间在很多情况下会存在这样的问题,就是单个计算节点往往无法一次性就把它所需要的数据加载进内存,也就是我们通常所说的内存瓶颈。解决内存瓶颈问题一般都是采用“分割-合并”的策略,而Hadoop在内部正是通过排序器、组合器、合并器来实现这一策略的。可以这么说,map-reduce计算模型是Hadoop解决海量数据处理的战略布局,排序器/组合器/合并器是Hadoop解决计算节点性能的战术实现。
在本文,我将给大家详细的阐述Hadoop的大牛们是如何来设计key-value排序器、组合器、合并器的。
一、排序器(Sorter)
对于Hadoop中排序器的设计,我不得不得先向Hadoop的设计大牛们深深的鞠上一躬,它牛B了,太精彩了。他们将排序问题抽象成了一个框架,或者说是一个排序模型:
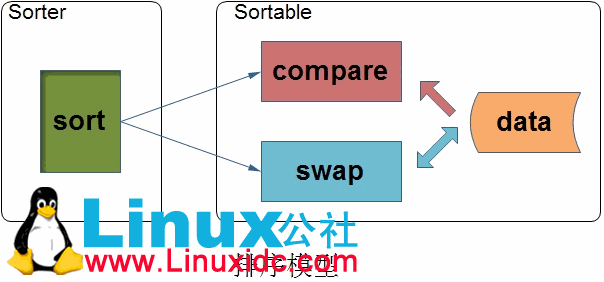
上面的排序模型将排序问题描述成这样的一个过程:排序器不断地对待排序的记录集进行某两条记录的比较与交换。也就是说,任何一种排序算法只对带排序的记录集进行两种基本操作:比较两条记录的大小、交换两条记录在带排序记录集中的位置,这就是Hadoop大牛们对排序问题的精简定义,这样的定义来源于他们对问题在最本质上的了解。我不得不说只有对问题有了最深入、最本质的了解之后才能设计出最抽象、最准确的解决方案,对已实现的解决方法的不断重构只能治标不能治本。在Sorter中实现某种排序算法,在Sortable中实现某种可排序的数据集,这样使得排序算法与待排序的数据集分开,排序算法永远也不知道也不需要知道它正在对哪个数据类型的数据集进行排序。而Hadoop在其内部这是这样设计的。

Hadoop关于可排序的数据集定义了一个抽象接口IndexedSortable,也就是说任何能够排序的数据集必须要实现两个方法,一是能够比较它的数据集中任意两项的大小,二是能够交换它的数据集中任意两项的位置;排序算法的实现定义了一个抽象接口IndexedSorter,它定义了两个方法,其中的一个方法还可以报告当前排序的完成进度。
二、组合器(Combiner)
Hadoop在其内部利用组合器来局部合并具有相同key的key-value记录,组合器的设计大致同排序器的设计一样,也是将合并操作和待合并的数据分开,这个组合器框架设计如下:
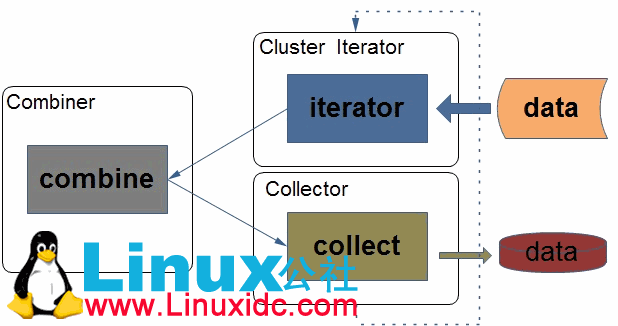
Hadoop中的合并器一般合并的key-value数据来自与内存,然后把合并后的结果按照一定的组织格式写入磁盘文件作为中间数据,待最后汇总合并,我们把每一次合并后的这种中间结果看做一个段。在Hadoop中是这样实现这个组合框架的:

Hadoop中的组合器的实现主要用来处理key-value类型的数据,它先把带合并的所有的key-value结合按照key值来聚合,这样就使得相同key值的key-value记录被保存到同一个迭代器(Iterator)中,然后把一个个迭代器结构组合器来处理,最后每一迭代器的处理结果被交给了收集器(Collector)来保存。
三、合并器(Merger)
这里的合并器(Merger)不同于上面介绍的组合器(Combiner),它主要是正对上面组合器生成的最后结果进行合并,也就是合并所有的中间段,这个框架在Hadoop内部是这样设计的:
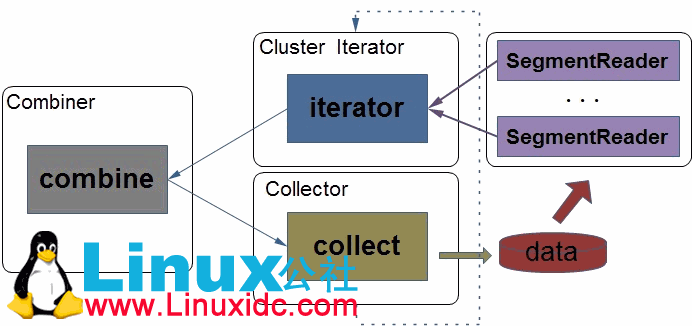
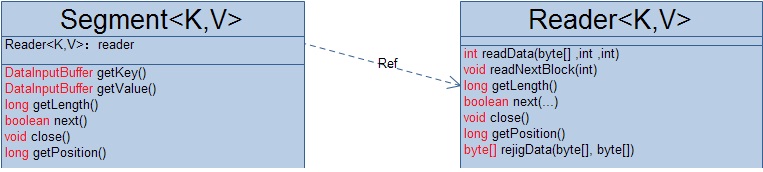
Hadoop中合并器(Merger)的设计类似于它的组合器(Combiner),唯一不同的就是这个聚合迭代器的来源略有不同,合并器中的每一个迭代器来自于所有的中间段中属于相同类的key-value,所以对每一中间段,合并器都生成了一个对应的段读取器来读取段(SegmentReader)中的key-value值。主要看一下与段读取器(SegmentReader)相关的实现类:
四、总结
在本文,我系统的介绍了Hadoop对排序器/组合器/合并器的设计,Hadoop对它们的设计可以说是站在一个好高的层次,因此我们就可以把这些框架移植到其它引用场景下,甚至无需修改任何代码。














 186
186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









