






This Article is From:https://examples.javacodegeeks.com/enterprise-java/apache-hadoop/hadoop-mapreduce-combiner-example/
关于拉曼Jhajj
![]() Ramaninder毕业于德国Georg-August大学计算机科学与数学系,目前与奥地利的大数据研究中心合作。他拥有应用计算机科学硕士学位,专业应用系统工程和商业信息学。他也是一名微软认证过程,在Java,C#,Web开发和相关技术方面有超过5年的经验。目前,他的主要兴趣是大数据生态系统,包括批处理和流处理系统,机器学习和Web应用程序。
Ramaninder毕业于德国Georg-August大学计算机科学与数学系,目前与奥地利的大数据研究中心合作。他拥有应用计算机科学硕士学位,专业应用系统工程和商业信息学。他也是一名微软认证过程,在Java,C#,Web开发和相关技术方面有超过5年的经验。目前,他的主要兴趣是大数据生态系统,包括批处理和流处理系统,机器学习和Web应用程序。
建议先看英文再看翻译:翻译使用的是Google翻译。
在这个例子中,我们将学习Hadoop Combiners。 组合器是Hadoop提供的非常有用的功能,特别是当我们处理大量数据时。 我们将使用一个简单的问题来理解组合器。
1.介绍(Introduction)
Hadoop组合器类是MapReduce框架中的一个可选类,它添加在Map类和Reduce类之间,用于通过组合Map中的数据输出来减少Reduce类接收的数据量。
组合器的主要功能是汇总Map类的输出,以便能够管理来自reducer的数据处理的压力,并且可以处理网络拥塞。
由于这个功能,Combiners还被命名为“Mini-Reducer”,“Semi-Reducer”等。
2.工作流程(Workflow)
与mapper和reducer不同,组合器没有任何预定义的接口。它需要实现reducer接口和覆盖reduce()方法。从技术上讲,组合器和减少器共享相同的代码。
让我们假设我们有一个map类,它从记录读取器接收输入并处理它以产生键值对作为输出。这些键值对包含每个工作作为键和1作为值,其中1表示此键具有的实例数。例如,像<This,1> <is,1> <an,1> <example,1>。
不合并器从映射输出接收每个键值对,并处理它以将键和传输器值作为集合来合并常用字。例如,<This,1,1,1> <is,1,1,1,1> <an,1> <example,1,1>等,其中“This”表示密钥,“1,1,1 “表示值的集合,这里它表示工作”这“出现3次,值为1所有3。
之后,Reducer方法从组合器获取这些“键值集合”对,并处理它以输出最终结果。这将把<This,1,1,1>变换为<This,3>。
3.使用Combiner的MapReduce字数计算示例
字计数程序是用于理解MapReduce编程范例工作的基本代码。我们将使用这个字计数程序来理解Map,Reduce和Combiner类。该程序包括Map方法,Combine方法和Reduce方法,用于计算文件中每个单词的出现次数。
3.1设置(Setup)
我们将使用Maven为Hadoop字计数示例设置一个新项目。在Eclipse中设置一个maven项目,并将以下Hadoop依赖项添加到pom.xml。这将确保我们具有对Hadoop核心库的所需访问权限。
pom.xml
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>3.2映射类(Mapper Class)
映射器任务负责基于空间对输入文本进行标记化,并创建单词列表,然后遍历所有标记并发出每个单词的键值对,计数为1。下面是MapClass:
MapClass.java
package com.javacodegeeks.examples.wordcount;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MapClass extends Mapper{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
//Get the text and tokenize the word using space as separator.
String line = value.toString();
StringTokenizer st = new StringTokenizer(line," ");
//For each token aka word, write a key value pair with
//word and 1 as value to context
while(st.hasMoreTokens()){
word.set(st.nextToken());
context.write(word,one);
}
}
}- 行13-14,定义具有整数值1的静态变量1和用于存储字的字
- 第22-23行,在map方法中,输入的Text变量被转换为String和Tokenized基于空格,以获得输入文本中的所有单词
- 第27-30行,对于文本中的每个单词,设置单词变量,并将单词和整数值的键值对传递给上下文。
3.3组合器/减速器代码(Conbiner/Reducer Code)
以下代码片段包含ReduceClass,这是我们将用于Combiner的相同代码,因此我们不需要完全编写其他类,但会使用相同的reducer类并将其分配为驱动程序类中的组合器(MapReduce的入口点)。此类扩展了MapReduce Reducer类并覆盖reduce()函数。 该方法对值进行迭代,添加它们并将其组合/减少为单个值/值对。Daa从mapper类移动到组合器,然后是reducer类
ReduceClass.java
package com.javacodegeeks.examples.wordcount;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class ReduceClass extends Reducer{
@Override
protected void reduce(Text key, Iterable values,
Context context)
throws IOException, InterruptedException {
int sum = 0;
Iterator valuesIt = values.iterator();
//For each key value pair, get the value and adds to the sum
//to get the total occurances of a word
while(valuesIt.hasNext()){
sum = sum + valuesIt.next().get();
}
//Writes the word and total occurances as key-value pair to the context
context.write(key, new IntWritable(sum));
}
}- 行17-18,在reducer接收的值上定义一个变量sum作为整数值0和Iterator
- 第22-24行,迭代所有的值,并添加总和的单词的出现
- 第27行,在上下文中将单词和和写为键值对
3.4驱动程序类(The Driver Class)
所以现在当我们有我们的地图,组合器和reduce类准备好了,是时候把它所有在一起作为一个单一的工作,这是在一个叫做driver类的类。此类包含用于设置和运行作业的main()方法。
WordCount.java
package com.javacodegeeks.examples.wordcount;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WordCount extends Configured implements Tool{
public static void main(String[] args) throws Exception{
int exitCode = ToolRunner.run(new WordCount(), args);
System.exit(exitCode);
}
public int run(String[] args) throws Exception {
if (args.length != 2) {
System.err.printf("Usage: %s needs two arguments, input and output
files\n", getClass().getSimpleName());
return -1;
}
//Create a new Jar and set the driver class(this class) as the main class of jar
Job job = new Job();
job.setJarByClass(WordCount.class);
job.setJobName("WordCounter");
//Set the input and the output path from the arguments
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
//Set the map and reduce classes in the job
job.setMapperClass(MapClass.class);
job.setCombinerClass(ReduceClass.class);
job.setReducerClass(ReduceClass.class);
//Run the job and wait for its completion
int returnValue = job.waitForCompletion(true) ? 0:1;
if(job.isSuccessful()) {
System.out.println("Job was successful");
} else if(!job.isSuccessful()) {
System.out.println("Job was not successful");
}
return returnValue;
}
}以下是main功能的工作流程:
- 第22-26行,检查是否提供了所需数量的参数
- 第29-31行,创建一个新的作业,设置作业的名称和主类
- 第34-35行,设置参数的输入和输出路径
- 第37-39行,设置键值类型类和输出格式类。这些类需要是我们在地图中使用的相同类型,并且减少输出
- 第42-44行,在作业中设置Map,Combiner和Reduce类
- 第46行,执行作业并等待其完成
4.代码执行(Code Execution)
有两种方法来执行我们编写的代码,首先是在Eclipse IDE自身中执行它用于测试目的,其次是在Hadoop集群中执行。我们将在本节中看到两种方法。
4.1在Eclipse IDE中
在eclipse中执行wordcount代码。 首先,创建一个带有虚拟数据的input.txt文件。 为了测试的目的,我们在项目根目录中创建了一个带有以下文本的文件。
Input.txt
This is the example text file for word count example also knows as hello world example of the Hadoop ecosystem.
This example is written for the examples article of java code geek
The quick brown fox jumps over the lazy dog.
The above line is one of the most famous lines which contains all the english language alphabets.在Eclipse中,传递项目参数中的输入文件和输出文件名。 以下是参数的样子。 在这种情况下,输入文件位于项目的根目录中,这是为什么只需要filename,但如果输入文件位于其他位置,则应提供完整的路径。
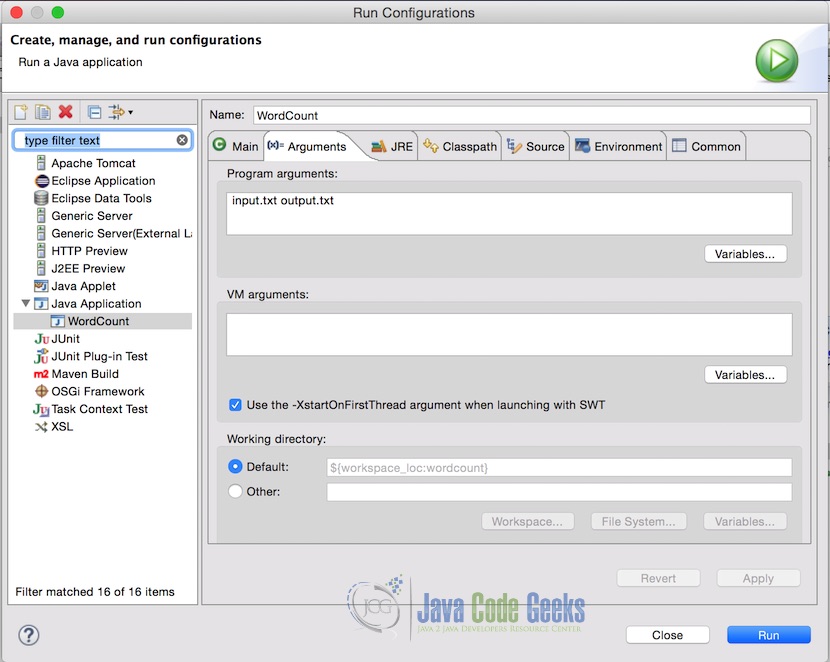
注意:确保输出文件不存在。如果存在,程序将抛出一个错误。
设置参数后,只需运行应用程序。 成功完成应用程序后,控制台将显示输出。
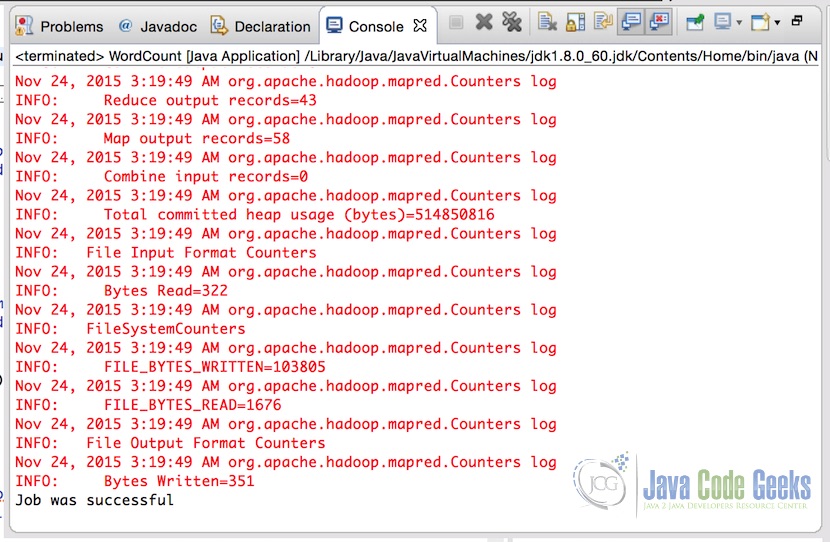
下面是输出文件的内容:
Hadoop 1
The 2
This 2
above 1
all 1
alphabets. 1
also 1
article 1
as 1
brown 1
code 1
contains 1
count 1
dog. 1
ecosystem. 1
english 1
example 4
examples 1
famous 1
file 1
for 2
fox 1
geek 1
hello 1
is 3
java 1
jumps 1
knows 1
language 1
lazy 1
line 1
lines 1
most 1
of 3
one 1
over 1
quick 1
text 1
the 6
which 1
word 1
world 1
written 14.2在Hadoop集群上
为了在hadoop集群上运行Wordcount示例,我们假设:
- Hadoop集群已设置并运行
- 输入文件位于HDFS中的路径/user/root/wordcount/Input.txt
如果您需要任何帮助设置hadoop集群或Hadoop文件系统,请参阅以下文章:
现在,首先确保Input.txt文件存在于路径/ user / root / wordcount,使用命令:
hadoop fs -ls /user/root/wordcount
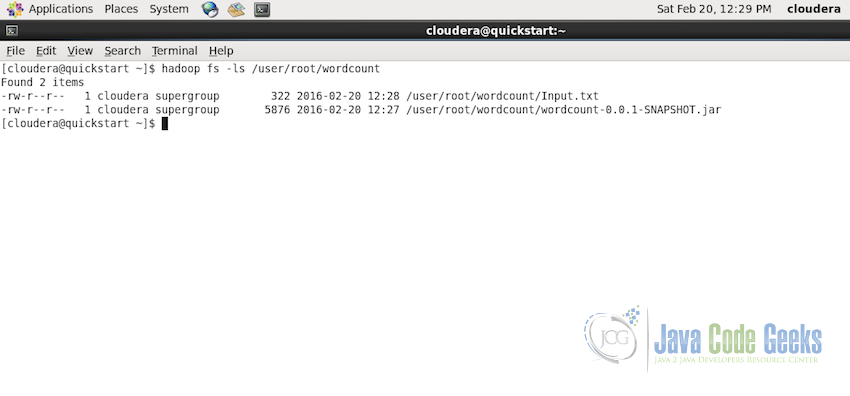
确认输入文件是否存在于所需的文件夹中,现在是提交MapReduce作业的时候了。使用以下命令执行:
hadoop jar Downloads/wordcount-0.0.1-SNAPSHOT.jar com.javacodegeeks.examples.wordcount.Wordcount /user/root/wordcount/Input.txt /user/root/wordcount/Output在上面的代码中,jar文件位于Downloads文件夹中,Main类位于路径com.javacodegeeks.examples.wordcount.Wordcount
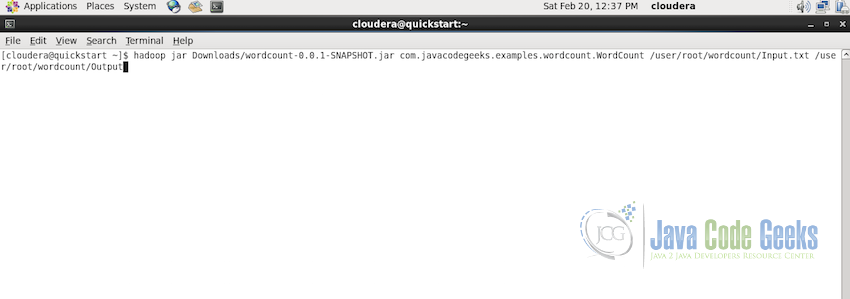
现在我们可以读取文件夹/ user / root / wordcount / Output /中的Wordcount映射reduce作业的输出。使用以下命令检查控制台中的输出:
hadoop fs -cat /user/root/wordcount/Output/part-r-00000下面的屏幕截图显示控制台上的Output文件夹的内容。
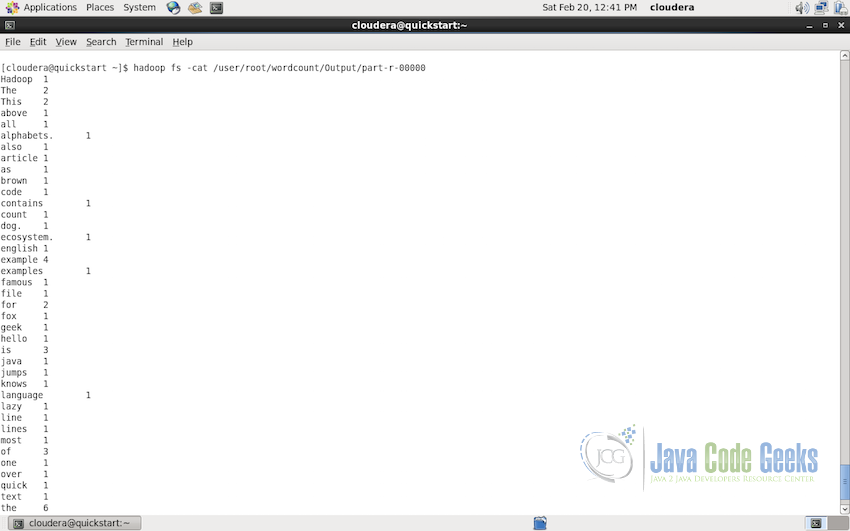
5.结论(Conclusion)
这个例子解释了关于Apache Hadoop的Map-Reduce和Combiner范例如何在MapReduce中逐步编写字计数示例。接下来,我们看到了如何在eclipse中执行示例以用于测试目的,以及如何在Hadoop集群中使用HDFS为输入文件执行。 本文还提供了有关在Ubuntu上设置Hadoop,设置Hadoop集群,了解HDFS和基本FS命令的其他有用文章的链接。我们希望,本文的目的是解释Hadoop MapReduce的基础知识,为您提供了解Apache Hadoop和MapReduce的坚实基础。
6.下载Eclipse项目
点击下面的链接下载完整的eclipse项目wordcount示例与Mapper,Reducer和Combiner。
下载您可以在这里下载此示例的完整源代码:WordcountWithCombiner
注:为保证代码持续可用,已备份至百度云盘http://pan.baidu.com/s/1jHLE7Oi















 4971
4971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









