








以R可视化为桥梁
经常有对比R,Python和Julia之间的讨论,似乎R语言在这三者之中是最为逊色的,实则不可一概而论。
R语言在常规数据分析的场景下,如数据读入,预处理,整理,以及单机可视化方面表现出的优势,无论从用户体验,还是代码流畅度,令另两种语言略逊一筹。
本文将从统计学中最基本的密度曲线的绘制,来串讲一下题目中所涉及的R语言可视化中三个强大的可视化包的用法,以及之间的联系。
以此为基础,进阶高段,可以自然过渡到Python,Julia等语言的可视化实践活动中。
首先引入本次实践使用的数据集SENIC,该数据集描述了在不同的美国医院测量的结果。具体说明如下:
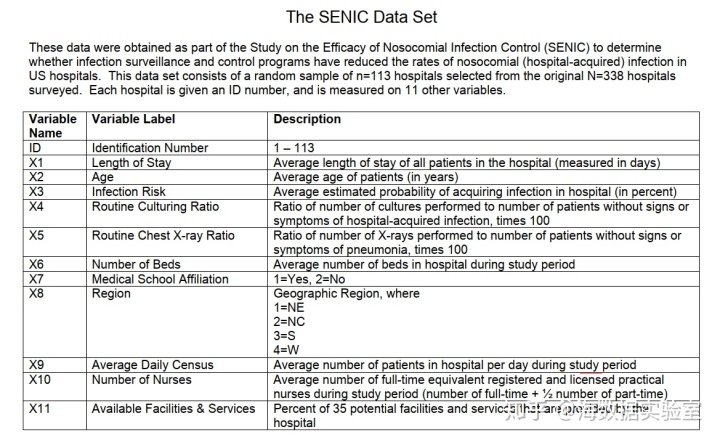
大家参考一下即可,本文着重具体操作。
数据集可在这里下载:
http://stu-docx.hismartlab.club/public/data/SENIC.txtstu-docx.hismartlab.club本文的代码部分,用Rmarkdown来实现,我们一起来做。
1准备可能用到的包
```{r setup, include=FALSE}
knitr::opts_chunk$set(echo=TRUE)
library(tidyverse)
library(plotly)
library(shiny)
library(griidExtra)
library(DT)
```这里介绍一下tidyverse,这个包是Rstudio开发的数据分析功能包的合集,已经成为一种生态体系,本文需要用到ggplot2就在其中,每次载入tidyverse,相关的包会显示出来,
如下图所示,足见其完备,其中dplyr也是一个非常实用的数据处理的包,在本文中也会有所使用。
plotly和shiny也是本文的重点,自然要载入。其他显示在图,并未于此提及的包会在后续步骤中用到时再做介绍。
2 读取数据,简单展示
2.1 根据数据集描述整理变量标签
variable_labels <- c("ID", "Length of Stay", "Age", "Infection Risk",
"Routine Culturing Ratio", "Routine Chest X-ray Ratio",
"Number of Beds", "Medical School Affiliation", "Region",
"Average Daily Census", "Number  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









