







 selenium+phantomjs爬取bilibili首先我们要下载phantomjs 你可以到 http://phantomjs.org/download.html 这里去下载 下载完之后解压到你想要放的位置 你需要配置一下环境变量哦如下图:首先,我们怎么让浏览器模拟操作,也就是我们自己先分析好整个操作过程,哪个地方有什么问题,把这些问题都提前测试好,没问题了再进行写代码。打开bilibili...
selenium+phantomjs爬取bilibili首先我们要下载phantomjs 你可以到 http://phantomjs.org/download.html 这里去下载 下载完之后解压到你想要放的位置 你需要配置一下环境变量哦如下图:首先,我们怎么让浏览器模拟操作,也就是我们自己先分析好整个操作过程,哪个地方有什么问题,把这些问题都提前测试好,没问题了再进行写代码。打开bilibili...
selenium+phantomjs爬取bilibili
首先我们要下载phantomjs 你可以到 http://phantomjs.org/download.html 这里去下载 下载完之后解压到你想要放的位置 你需要配置一下环境变量哦
如下图:

首先,我们怎么让浏览器模拟操作,也就是我们自己先分析好整个操作过程,哪个地方有什么问题,把这些问题都提前测试好,没问题了再进行写代码。
打开bilibili网站 https://www.bilibili.com/ 发现下图登陆弹窗
那么这里我们就得先把这个弹窗去除,怎么去呢?你刷新一下或者点一下 首页 就不会出现了,所以这里我们可以模拟再刷新一次或者点击首页。
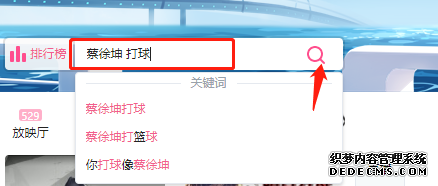
接下来搜索关键词 蔡徐坤 打球 这时就涉及到搜索输入框和搜索按钮
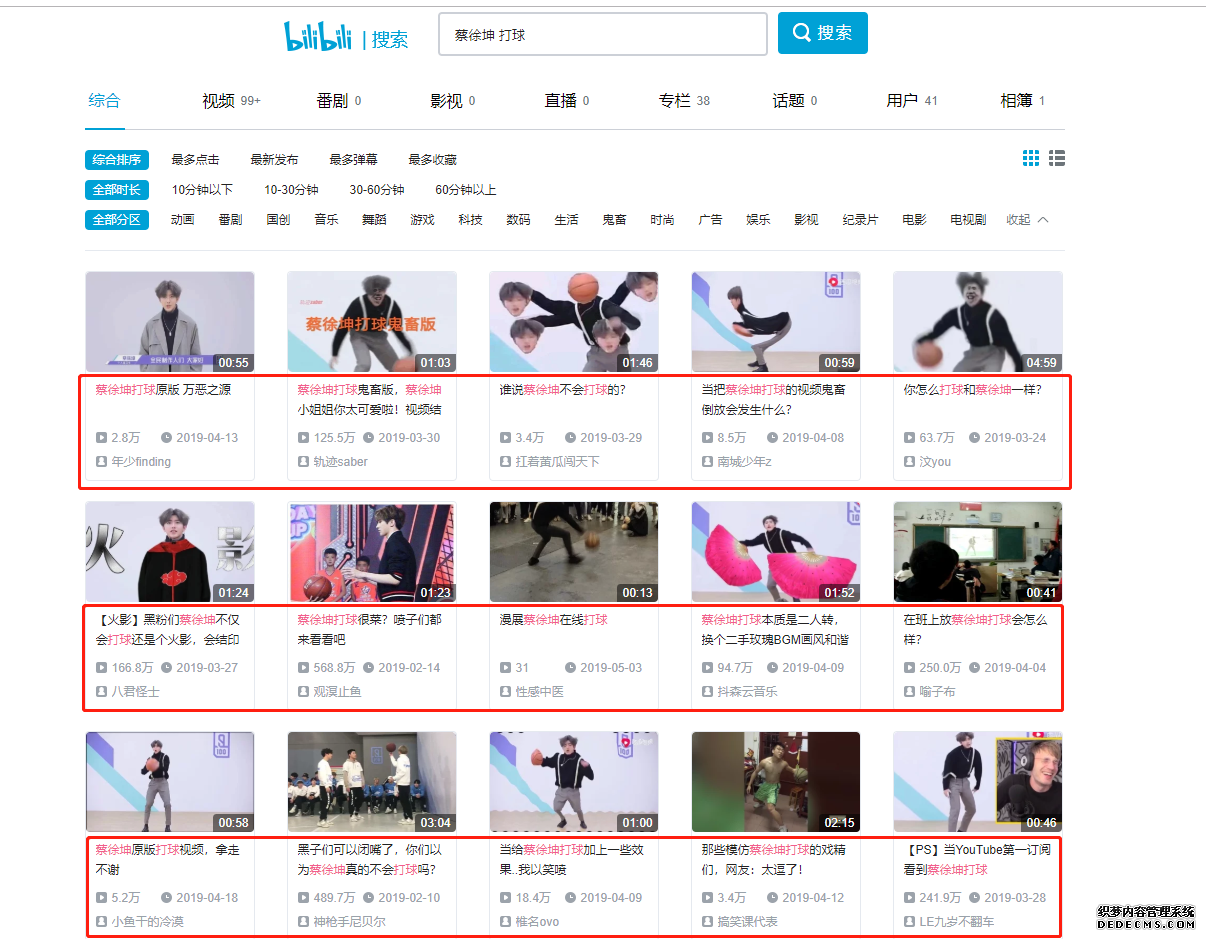
点击搜索后我们看到了下列内容,其中圈起来的就是要爬的信息啦 这时就涉及到页面源码获取,数据元素定位
那么上面这个过程走完了的话 我们也可以选择写入xls格式,同时这里还少了一个事,那就是我现在才爬了一页,那难道不写个自动化爬取全部吗?

那此时就得解决循环获取和写入xls 更重要的事怎么去操作页数和下一页按钮
大致的思路就是这样子了!!!
先导入这些模块
from selenium import webdriver
from selenium.common.exceptions import TimeoutException #一条命令在足够的时间内没有完成则会抛出异常
from selenium.webdriver.common.by import By #支持的定位器分类
from selenium.webdriver.support.ui import WebDriverWait #等待页面加载完成,找到某个条件发生后再继续执行后续代码,如果超过设置时间检测不到则抛出异常
from selenium.webdriver.support import expected_conditions as EC #判断元素是否加载
from bs4 import BeautifulSoup
import xlwt
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









