






一、Lucene提供的分词器StandardAnalyzer和SmartChineseAnalyzer
1.新建一个测试Lucene提供的分词器的maven项目LuceneAnalyzer

2. 在pom.xml里面引入如下依赖
org.apache.lucene
lucene-core
7.3.0
org.apache.lucene
lucene-analyzers-smartcn
7.3.0
3. 新建一个标准分词器StandardAnalyzer的测试类LuceneStandardAnalyzerTest
packagecom.luceneanalyzer.use.standardanalyzer;importjava.io.IOException;importorg.apache.lucene.analysis.Analyzer;importorg.apache.lucene.analysis.TokenStream;importorg.apache.lucene.analysis.standard.StandardAnalyzer;importorg.apache.lucene.analysis.tokenattributes.CharTermAttribute;/*** Lucene core模块中的 StandardAnalyzer英文分词器使用
* 英文分词效果好,中文分词效果不好
*@authorTHINKPAD
**/
public classLuceneStandardAnalyzerTest {private static void doToken(TokenStream ts) throwsIOException {
ts.reset();
CharTermAttribute cta= ts.getAttribute(CharTermAttribute.class);while(ts.incrementToken()) {
System.out.print(cta.toString()+ "|");
}
System.out.println();
ts.end();
ts.close();
}public static void main(String[] args) throwsIOException {
String etext= "Analysis is one of the main causes of slow indexing. Simply put, the more you analyze the slower analyze the indexing (in most cases).";
String chineseText= "张三说的确实在理。";//Lucene core模块中的 StandardAnalyzer 英文分词器
try (Analyzer ana = newStandardAnalyzer();) {
TokenStream ts= ana.tokenStream("coent", etext);
System.out.println("标准分词器,英文分词效果:");
doToken(ts);
ts= ana.tokenStream("content", chineseText);
System.out.println("标准分词器,中文分词效果:");
doToken(ts);
}catch(IOException e) {
}
}
}
运行效果:
标准分词器,英文分词效果:
analysis|one|main|causes|slow|indexing|simply|put|more|you|analyze|slower|analyze|indexing|most|cases|标准分词器,中文分词效果:
张|三|说|的|确|实|在|理|
4. 新建一个Lucene提供的中文分词器SmartChineseAnalyzer的测试类
packagecom.luceneanalyzer.use.smartchineseanalyzer;importjava.io.IOException;importorg.apache.lucene.analysis.Analyzer;importorg.apache.lucene.analysis.TokenStream;importorg.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;importorg.apache.lucene.analysis.standard.StandardAnalyzer;importorg.apache.lucene.analysis.tokenattributes.CharTermAttribute;/*** Lucene提供的中文分词器模块,lucene-analyzers-smartcn:Lucene 的中文分词器 SmartChineseAnalyzer
* 中英文分词效果都不好
*
*@authorTHINKPAD
**/
public classLuceneSmartChineseAnalyzerTest {private static void doToken(TokenStream ts) throwsIOException {
ts.reset();
CharTermAttribute cta= ts.getAttribute(CharTermAttribute.class);while(ts.incrementToken()) {
System.out.print(cta.toString()+ "|");
}
System.out.println();
ts.end();
ts.close();
}public static void main(String[] args) throwsIOException {
String etext= "Analysis is one of the main causes of slow indexing. Simply put, the more you analyze the slower analyze the indexing (in most cases).";
String chineseText= "张三说的确实在理。";//Lucene 的中文分词器 SmartChineseAnalyzer
try (Analyzer smart = newSmartChineseAnalyzer()) {
TokenStream ts= smart.tokenStream("content", etext);
System.out.println("smart中文分词器,英文分词效果:");
doToken(ts);
ts= smart.tokenStream("content", chineseText);
System.out.println("smart中文分词器,中文分词效果:");
doToken(ts);
}
}
}
运行效果:
smart中文分词器,英文分词效果:
analysi|is|on|of|the|main|caus|of|slow|index|simpli|put|the|more|you|analyz|the|slower|analyz|the|index|in|most|case|smart中文分词器,中文分词效果:
张|三|说|的|确实|在|理|
二、IKAnalyze中文分词器集成
IKAnalyzer是开源、轻量级的中文分词器,应用比较多
最先是作为lucene上使用而开发,后来发展为独立的分词组件。只提供到Lucene 4.0版本的支持。我们在4.0以后版本Lucene中使用就需要简单集成一下。
需要做集成,是因为Analyzer的createComponents方法API改变了
IKAnalyzer提供两种分词模式:细粒度分词和智能分词
集成步骤
1、找到 IkAnalyzer包体提供的Lucene支持类,比较IKAnalyzer的createComponets方法。
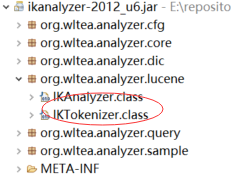
4.0及之前版本的createComponets方法:
@Overrideprotected TokenStreamComponents createComponents(String fieldName, finalReader in) {
Tokenizer _IKTokenizer= new IKTokenizer(in, this.useSmart());return newTokenStreamComponents(_IKTokenizer);
}
最新的createComponets方法:
protected abstract TokenStreamComponents createComponents(String fieldName);
2、照这两个类,创建新版本的, 类里面的代码直接复制,修改参数即可。
下面开始集成:
1.新建一个maven项目IkanalyzerIntegrated

2. 在pom.xml里面引入如下依赖
org.apache.lucene
lucene-core
7.3.0
com.janeluo
ikanalyzer
2012_u6
org.apache.lucene
lucene-core
org.apache.lucene
lucene-queryparser
org.apache.lucene
lucene-analyzers-common
3. 重写分析器
packagecom.study.lucene.ikanalyzer.Integrated;importorg.apache.lucene.analysis.Analyzer;/*** 因为Analyzer的createComponents方法API改变了需要重新实现分析器
*@authorTHINKPAD
**/
public class IKAnalyzer4Lucene7 extendsAnalyzer {private boolean useSmart = false;publicIKAnalyzer4Lucene7() {this(false);
}public IKAnalyzer4Lucene7(booleanuseSmart) {super();this.useSmart =useSmart;
}public booleanisUseSmart() {returnuseSmart;
}public void setUseSmart(booleanuseSmart) {this.useSmart =useSmart;
}
@OverrideprotectedTokenStreamComponents createComponents(String fieldName) {
IKTokenizer4Lucene7 tk= new IKTokenizer4Lucene7(this.useSmart);return newTokenStreamComponents(tk);
}
}
4. 重写分词器
packagecom.study.lucene.ikanalyzer.Integrated;importjava.io.IOException;importorg.apache.lucene.analysis.Tokenizer;importorg.apache.lucene.analysis.tokenattributes.CharTermAttribute;importorg.apache.lucene.analysis.tokenattributes.OffsetAttribute;importorg.apache.lucene.analysis.tokenattributes.TypeAttribute;importorg.wltea.analyzer.core.IKSegmenter;importorg.wltea.analyzer.core.Lexeme;/*** 因为Analyzer的createComponents方法API改变了需要重新实现分词器
*@authorTHINKPAD
**/
public class IKTokenizer4Lucene7 extendsTokenizer {//IK分词器实现
privateIKSegmenter _IKImplement;//词元文本属性
private finalCharTermAttribute termAtt;//词元位移属性
private finalOffsetAttribute offsetAtt;//词元分类属性(该属性分类参考org.wltea.analyzer.core.Lexeme中的分类常量)
private finalTypeAttribute typeAtt;//记录最后一个词元的结束位置
private intendPosition;/***@paramin
*@paramuseSmart*/
public IKTokenizer4Lucene7(booleanuseSmart) {super();
offsetAtt= addAttribute(OffsetAttribute.class);
termAtt= addAttribute(CharTermAttribute.class);
typeAtt= addAttribute(TypeAttribute.class);
_IKImplement= newIKSegmenter(input, useSmart);
}/** (non-Javadoc)
*
* @see org.apache.lucene.analysis.TokenStream#incrementToken()*/@Overridepublic boolean incrementToken() throwsIOException {//清除所有的词元属性
clearAttributes();
Lexeme nextLexeme=_IKImplement.next();if (nextLexeme != null) {//将Lexeme转成Attributes//设置词元文本
termAtt.append(nextLexeme.getLexemeText());//设置词元长度
termAtt.setLength(nextLexeme.getLength());//设置词元位移
offsetAtt.setOffset(nextLexeme.getBeginPosition(),
nextLexeme.getEndPosition());//记录分词的最后位置
endPosition =nextLexeme.getEndPosition();//记录词元分类
typeAtt.setType(nextLexeme.getLexemeTypeString());//返会true告知还有下个词元
return true;
}//返会false告知词元输出完毕
return false;
}/** (non-Javadoc)
*
* @see org.apache.lucene.analysis.Tokenizer#reset(java.io.Reader)*/@Overridepublic void reset() throwsIOException {super.reset();
_IKImplement.reset(input);
}
@Overridepublic final voidend() {//set final offset
int finalOffset = correctOffset(this.endPosition);
offsetAtt.setOffset(finalOffset, finalOffset);
}
}
5. 新建一个IKAnalyzer的测试类IKAnalyzerTest
packagecom.study.lucene.ikanalyzer.Integrated;importjava.io.IOException;importorg.apache.lucene.analysis.Analyzer;importorg.apache.lucene.analysis.TokenStream;importorg.apache.lucene.analysis.tokenattributes.CharTermAttribute;/*** IKAnalyzer分词器集成测试:
* 细粒度切分:把词分到最细
* 智能切分:根据词库进行拆分符合我们的语言习惯
*
*@authorTHINKPAD
**/
public classIKAnalyzerTest {private static void doToken(TokenStream ts) throwsIOException {
ts.reset();
CharTermAttribute cta= ts.getAttribute(CharTermAttribute.class);while(ts.incrementToken()) {
System.out.print(cta.toString()+ "|");
}
System.out.println();
ts.end();
ts.close();
}public static void main(String[] args) throwsIOException {
String etext= "Analysis is one of the main causes of slow indexing. Simply put, the more you analyze the slower analyze the indexing (in most cases).";
String chineseText= "张三说的确实在理。";/*** ikanalyzer 中文分词器 因为Analyzer的createComponents方法API改变了 需要我们自己实现
* 分析器IKAnalyzer4Lucene7和分词器IKTokenizer4Lucene7*/
//IKAnalyzer 细粒度切分
try (Analyzer ik = newIKAnalyzer4Lucene7();) {
TokenStream ts= ik.tokenStream("content", etext);
System.out.println("IKAnalyzer中文分词器 细粒度切分,英文分词效果:");
doToken(ts);
ts= ik.tokenStream("content", chineseText);
System.out.println("IKAnalyzer中文分词器 细粒度切分,中文分词效果:");
doToken(ts);
}//IKAnalyzer 智能切分
try (Analyzer ik = new IKAnalyzer4Lucene7(true);) {
TokenStream ts= ik.tokenStream("content", etext);
System.out.println("IKAnalyzer中文分词器 智能切分,英文分词效果:");
doToken(ts);
ts= ik.tokenStream("content", chineseText);
System.out.println("IKAnalyzer中文分词器 智能切分,中文分词效果:");
doToken(ts);
}
}
}
运行结果:
IKAnalyzer中文分词器 细粒度切分,英文分词效果:
analysis|is|one|of|the|main|causes|of|slow|indexing.|indexing|simply|put|the|more|you|analyze|the|slower|analyze|the|indexing|in|most|cases|IKAnalyzer中文分词器 细粒度切分,中文分词效果:
张三|三|说的|的确|的|确实|实在|在理|IKAnalyzer中文分词器 智能切分,英文分词效果:
analysis|is|one|of|the|main|causes|of|slow|indexing.|simply|put|the|more|you|analyze|the|slower|analyze|the|indexing|in|most|cases|IKAnalyzer中文分词器 智能切分,中文分词效果:
张三|说的|确实|在理|
三、扩展 IKAnalyzer的停用词和新词
扩展 IKAnalyzer的停用词
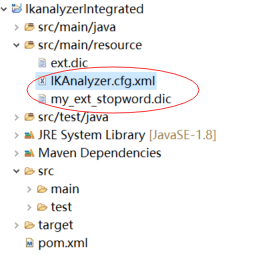
1、在类目录下创建IK的配置文件:IKAnalyzer.cfg.xml
2、在配置文件中增加配置扩展停用词文件的节点: my_ext_stopword.dic 如有多个,以“;”间隔
IK Analyzer 扩展配置
my_ext_stopword.dic
3、在类目录下创建我们的扩展停用词文件 my_ext_stopword.dic,编辑该文件加入停用词,一行一个

4、目录结构如下:
5.新建测试类ExtendedIKAnalyzerDicTest.java
packagecom.study.lucene.ikanalyzer.Integrated.ext;importjava.io.IOException;importorg.apache.lucene.analysis.Analyzer;importorg.apache.lucene.analysis.TokenStream;importorg.apache.lucene.analysis.tokenattributes.CharTermAttribute;importcom.study.lucene.ikanalyzer.Integrated.IKAnalyzer4Lucene7;/*** 扩展 IKAnalyzer的词典测试
*
**/
public classExtendedIKAnalyzerDicTest {private static void doToken(TokenStream ts) throwsIOException {
ts.reset();
CharTermAttribute cta= ts.getAttribute(CharTermAttribute.class);while(ts.incrementToken()) {
System.out.print(cta.toString()+ "|");
}
System.out.println();
ts.end();
ts.close();
}public static void main(String[] args) throwsIOException {
String chineseText= "厉害了我的国一经播出,受到各方好评,强烈激发了国人的爱国之情、自豪感!";//IKAnalyzer 细粒度切分
try (Analyzer ik = newIKAnalyzer4Lucene7();) {
TokenStream ts= ik.tokenStream("content", chineseText);
System.out.println("IKAnalyzer中文分词器 细粒度切分,中文分词效果:");
doToken(ts);
}//IKAnalyzer 智能切分
try (Analyzer ik = new IKAnalyzer4Lucene7(true);) {
TokenStream ts= ik.tokenStream("content", chineseText);
System.out.println("IKAnalyzer中文分词器 智能切分,中文分词效果:");
doToken(ts);
}
}
}
运行结果:
未加停用词之前:

加停用词之后:

扩展 IKAnalyzer的新词:
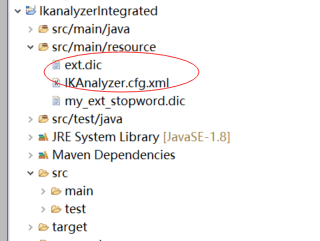
1、在类目录下IK的配置文件:IKAnalyzer.cfg.xml 中增加配置扩展词文件的节点: ext.dic 如有多个,以“;”间隔
IK Analyzer 扩展配置
ext.dic
my_ext_stopword.dic
2、在类目录下创建扩展词文件 ext.dic,编辑该文件加入新词,一行一个

3、目录结构如下:
4.运行前面的测试类测试类ExtendedIKAnalyzerDicTest.java查看运行效果
运行结果:
未加新词之前:

加新词之后:

源码获取地址:
https://github.com/leeSmall/SearchEngineDemo














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









