







一、下载和测试模型
1. 下载YOLO-v3
git clone https://github.com/qqwweee/keras-yolo3.git
这是在Ubuntu里的命令,windows直接去 https://github.com/qqwweee/keras-yolo3下载、解压。得到一个 keras-yolo3-master 文件夹
2. 下载权重
wget https://pjreddie.com/media/files/yolov3.weights
去 https://pjreddie.com/media/files/yolov3.weights 下载权重。将 yolov3.weights 放入 keras-yolo3-master 文件夹
3. 生成 h5 文件
python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5
执行convert.py文件,这是将darknet的yolo转换为用于keras的h5文件,生成的h5被保存在model_data下。命令中的 convert.py 和 yolo.cfg 已经在keras-yolo3-master 文件夹下,不需要单独下载。
4. 用已经被训练好的yolo.h5进行图片识别测试
python yolo_video.py --image
执行后会让你输入一张图片的路径,由于我准备的图片放在与yolo_video.py同级目录,所以直接输入图片名称,不需要加路径
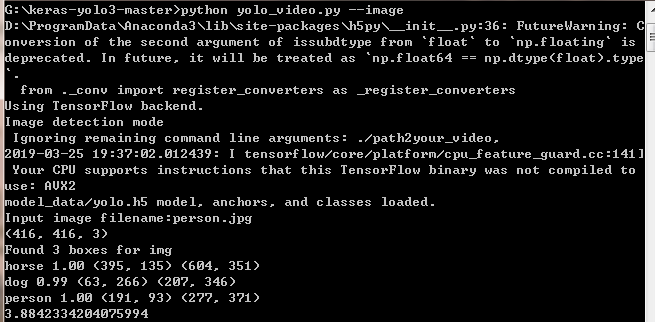
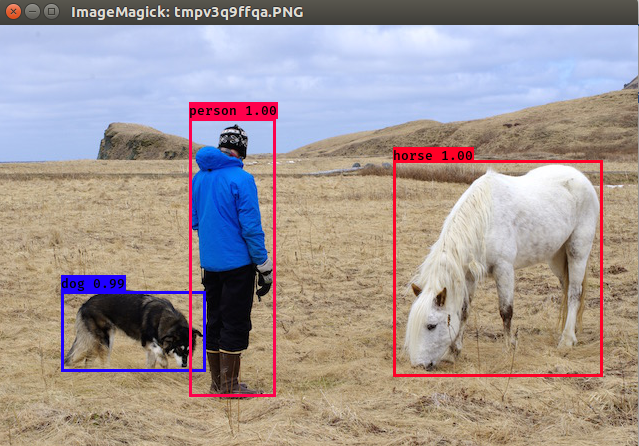
这就表明测试成功了。
二、制作自己的VOC数据集
参考我原来写的博客:
我是在Ubuntu内标注然后移到Windows的,如果在Windows里安装了LabelImg,可以直接在Windows下标注。
最后文件布局为:
三、修改配置文件、执行训练
1. 复制 voc_annotation.py 到voc文件夹下,修改 voc_annotation.py 分类。如下图:
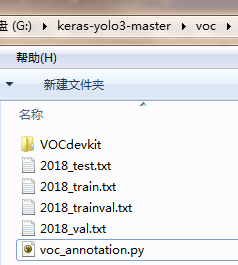 执行 voc_annotation.py 获得这四个文件
执行 voc_annotation.py 获得这四个文件
import xml.etree.ElementTree as ET
from os import getcwd
sets=[('2018', 'train'), ('2018', 'val'), ('2018', 'test'), ('2018', 'trainval')]
classes = []
def convert_annotation(year, image_id, list_fi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 615
615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









