







一、随机划分法
- 分层抽样(StratifiedShuffleSplit)
from sklearn.model_selection import StratifiedShuffleSplit
StratifiedShuffleSplit(n_splits=10,test_size=None,train_size=None, random_state=None)
n_splits:将数据集分成train/test对的组数,可根据需要进行设置,默认为10
train_size和test_size:是用来设置train/test对中train和test所占的比例。
参数random_state控制是将样本随机打乱
函数作用:(1)首先将数据集打乱n_splits次,产生n_splits组打乱的数据(2)其次根据设置的比例参数将每一组数据分层采样,所谓的分层采样就是保持在每一组划分后train和test中类别之间的比例与划分前的类别之间的比例相同。
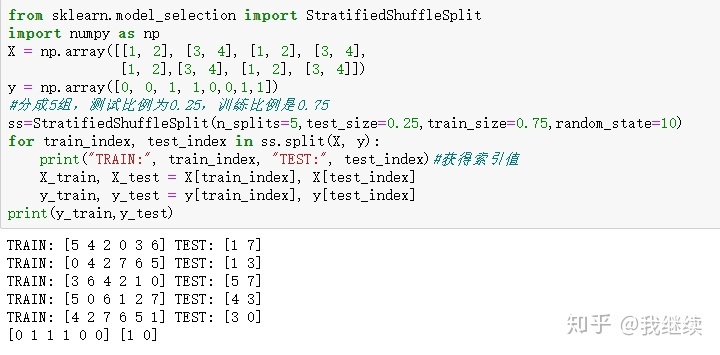
如上图,在y_test和y_train中类别之间比例为1:1,划分前数据类别比例也是1:1。这就是分层采样,保证数据的类别采样均匀性
- 随机有放回的抽样(ShuffleSplit)
from sklearn.model_selection import ShuffleSplit
测试集的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1122
1122











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









