






一、Apriori算法原理
参考:
Python --深入浅出Apriori关联分析算法(一)www.cnblogs.com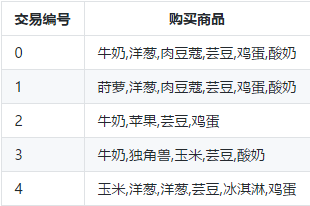
二、在Python中使用Apriori算法
查看Apriori算法的帮助文档:
from mlxtend.frequent_patterns import apriori
help(apriori)
Help on function apriori in module mlxtend.frequent_patterns.apriori:
apriori(df, min_support=0.5, use_colnames=False, max_len=None, verbose=0, low_memory=False)
Get frequent itemsets from a one-hot DataFrame
Parameters
-----------
df : pandas DataFrame
pandas DataFrame the encoded format. Also supports
DataFrames with sparse data;
Please note that the old pandas SparseDataFrame format
is no longer supported in mlxtend >= 0.17.2.
The allowed values are either 0/1 or True/False.
For example,
#apriori算法对输入数据类型有特殊要求!
#需要是数据框格式,并且数据要进行one-hot编码转换,转换后商品名称为列名,值为True或False。
#每一行记录代表一个顾客一次购物记录。
#第0条记录为[Apple,Beer,Chicken,Rice],第1条记录为[Apple,Beer,Rice],以此类推。
```
Apple Bananas Beer Chicken Milk Rice
0 True False True True False True
1 True False True False False True
2 True False True False False False
3 True True False False False False
4 False False True True True True
5 False False True False True True
6 False False True False True False
7 True True False False False False
```
min_support : float (default: 0.5)#最小支持度
A float between 0 and 1 for minumum support of the itemsets returned.
The support is computed as the fraction
`transactions_where_item(s)_occur / total_transactions`.
use_colnames : bool (default: False)
#设置为True,则返回的关联规则、频繁项集会使用商品名称,而不是商品所在列的索引值
If `True`, uses the DataFrames' column names in the returned DataFrame
instead of column indices.
max_len : int (default: None)
Maximum length of the itemsets generated. If `None` (default) all
possible itemsets lengths (under the apriori condition) are evaluated.
verbose : int (default: 0)
Shows the number of iterations if >= 1 and `low_memory` is `True`. If
>=1 and `low_memory` is `False`, shows the number of combinations.
low_memory : bool (default: False)
If `True`, uses an iterator to search for combinations above
`min_support`.
Note that while `low_memory=True` should only be used for large dataset
if memory resources are limited, because this implementation is approx.
3-6x slower than the default.
Returns
-----------
pandas DataFrame with columns ['support', 'itemsets'] of all itemsets
that are >= `min_support` and < than `max_len`
(if `max_len` is not None).
Each itemset in the 'itemsets' column is of type `frozenset`,
which is a Python built-in type that behaves similarly to
sets except that it is immutable.练习数据集:
链接: https://pan.baidu.com/s/1VLgpdc2N6ZEDvbaB5UnU1w
提取码: 6mbg
部分数据截图:
导入数据:
import pandas as pd
path = 'C:UsersCaraDesktopstore_data.csv'
records = pd.read_csv(path,header=None,encoding='utf-8')
print(records)结果如下:

使用TransactionEncoder对交易数据进行one-hot编码:
先查看TransactionEncoder的帮助文档:
from mlxtend.preprocessing import TransactionEncoder
... help(TransactionEncoder)
...
Help on class TransactionEncoder in module mlxtend.preprocessing.transactionencoder:
class TransactionEncoder(sklearn.base.BaseEstimator, sklearn.base.TransformerMixin)
| Encoder class for transaction data in Python lists
|
| Parameters
| ------------
| None
|
| Attributes
| ------------
| columns_: list
| List of unique names in the `X` input list of lists
|
| Examples
| ------------
| Method resolution order:
| TransactionEncoder
| sklearn.base.BaseEstimator
| sklearn.base.TransformerMixin
| builtins.object
|
| Methods defined here:
|
| __init__(self)
| Initialize self. See help(type(self)) for accurate signature.
|
| fit(self, X)
| Learn unique column names from transaction DataFrame
|
| Parameters
| ------------
| X : list of lists#指嵌套列表,列表中嵌套小列表。如[[],[],[]]格式。
| A python list of lists, where the outer list stores the
| n transactions and the inner list stores the items in each
| transaction.
|
| For example,
| [['Apple', 'Beer', 'Rice', 'Chicken'],
| ['Apple', 'Beer', 'Rice'],
| ['Apple', 'Beer'],
| ['Apple', 'Bananas'],
| ['Milk', 'Beer', 'Rice', 'Chicken'],
| ['Milk', 'Beer', 'Rice'],
| ['Milk', 'Beer'],
| ['Apple', 'Bananas']]
|
| fit_transform(self, X, sparse=False)
| Fit a TransactionEncoder encoder and transform a dataset.
|
| inverse_transform(self, array)#逆转换
| Transforms an encoded NumPy array back into transactions.
|
| Parameters
| ------------
| array : NumPy array [n_transactions, n_unique_items]
| The NumPy one-hot encoded boolean array of the input transactions,
| where the columns represent the unique items found in the input
| array in alphabetic order
|
| For example,
| ```
| array([[True , False, True , True , False, True ],
| [True , False, True , False, False, True ],
| [True , False, True , False, False, False],
| [True , True , False, False, False, False],
| [False, False, True , True , True , True ],
| [False, False, True , False, True , True ],
| [False, False, True , False, True , False],
| [True , True , False, False, False, False]])
| ```
| The corresponding column labels are available as self.columns_,
| e.g., ['Apple', 'Bananas', 'Beer', 'Chicken', 'Milk', 'Rice']
|
| Returns
| ------------
| X : list of lists
| A python list of lists, where the outer list stores the
| n transactions and the inner list stores the items in each
| transaction.
|
| For example,
| ```
| [['Apple', 'Beer', 'Rice', 'Chicken'],
| ['Apple', 'Beer', 'Rice'],
| ['Apple', 'Beer'],
| ['Apple', 'Bananas'],
| ['Milk', 'Beer', 'Rice', 'Chicken'],
| ['Milk', 'Beer', 'Rice'],
| ['Milk', 'Beer'],
| ['Apple', 'Bananas']]
| ```
|
| transform(self, X, sparse=False)
| Transform transactions into a one-hot encoded NumPy array.
|
| Parameters
| ------------
| X : list of lists#嵌套列表
| A python list of lists, where the outer list stores the
| n transactions and the inner list stores the items in each
| transaction.
|
| For example,
| [['Apple', 'Beer', 'Rice', 'Chicken'],
| ['Apple', 'Beer', 'Rice'],
| ['Apple', 'Beer'],
| ['Apple', 'Bananas'],
| ['Milk', 'Beer', 'Rice', 'Chicken'],
| ['Milk', 'Beer', 'Rice'],
| ['Milk', 'Beer'],
| ['Apple', 'Bananas']]
|
| sparse: bool (default=False)
| If True, transform will return Compressed Sparse Row matrix
| instead of the regular one.
|
| Returns
| ------------
| array : NumPy array [n_transactions, n_unique_items]
| if sparse=False (default).
| Compressed Sparse Row matrix otherwise
| The one-hot encoded boolean array of the input transactions,
| where the columns represent the unique items found in the input
| array in alphabetic order. Exact representation depends
| on the sparse argument
|
| For example,
| array([[True , False, True , True , False, True ],
| [True , False, True , False, False, True ],
| [True , False, True , False, False, False],
| [True , True , False, False, False, False],
| [False, False, True , True , True , True ],
| [False, False, True , False, True , True ],
| [False, False, True , False, True , False],
| [True , True , False, False, False, False]])
| The corresponding column labels are available as self.columns_, e.g.,
| ['Apple', 'Bananas', 'Beer', 'Chicken', 'Milk', 'Rice']由TransactionEncoder的帮助文档可知,需要将导入的文件由数据框格式转为嵌套列表形式,然后才能调用TransactionEncoder类下的fit()方法合transform()方法进行编码转换。
from mlxtend.preprocessing import TransactionEncoder
TE = TransactionEncoder()#类实例化
one_hot_records = TE.fit(lst_records).transform(lst_records)
print(one_hot_records)部分结果如下:
[['shrimp', 'almonds', 'avocado', 'vegetables mix', 'green grapes', 'whole weat flour', 'yams', 'cottage cheese', 'energy drink', 'tomato juice', 'low fat yogurt', 'green tea', 'honey', 'salad', 'mineral water', 'salmon', 'antioxydant juice', 'frozen smoothie', 'spinach', 'olive oil'], ['burgers', 'meatballs', 'eggs', nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan], ['chutney', nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan], ['turkey', 'avocado', nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan], ['mineral water', 'milk', 'energy bar', 'whole wheat rice', 'green tea', nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan], ……]可以看到,原本是空白单元格,在读入时被标记为NaN了,然后转换为list后,也保留了NaN。直接使用这样的数据进行one-hot编码转换报错了……
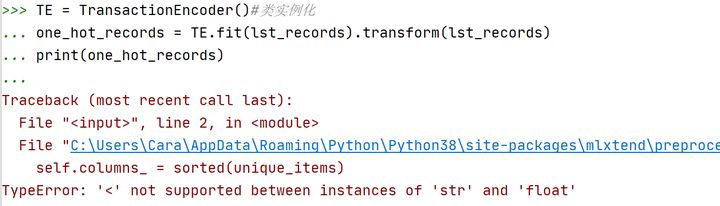
因此,尝试重新进行数据导入,设置na_filter=False将空值过滤掉。
#导入数据
import pandas as pd
path = 'C:UsersCaraDesktopstore_data.csv'
records = pd.read_csv(path,header=None,encoding='utf-8',na_filter=False)
print(records)结果如下:

将数据框转换为列表:
import numpy as np
lst_records = np.array(records).tolist()
print(lst_records)部分结果如下:
[['shrimp', 'almonds', 'avocado', 'vegetables mix', 'green grapes', 'whole weat flour', 'yams', 'cottage cheese', 'energy drink', 'tomato juice', 'low fat yogurt', 'green tea', 'honey', 'salad', 'mineral water', 'salmon', 'antioxydant juice', 'frozen smoothie', 'spinach', 'olive oil'], ['burgers', 'meatballs', 'eggs', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', ''], ['chutney', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', ''], ……]对交易数据进行one-hot编码:
from mlxtend.preprocessing import TransactionEncoder
TE = TransactionEncoder()#类实例化
one_hot_records = TE.fit(lst_records).transform(lst_records)
print(one_hot_records)结果如下:

调用Apriori算法进行频繁项集和关联规则挖掘:
由于Apriori算法要求输入数据格式为数据框,因此,需要对one-hot编码转换后的数据进行再次转换,目标格式:数据框。
df_records = pd.DataFrame(data = one_hot_records,columns = TE.columns_)
#TE类中的columns信息是由TE下的fit()方法得出的,参见TransactionEncoder类的参考文档
print(df_records)结果如下:
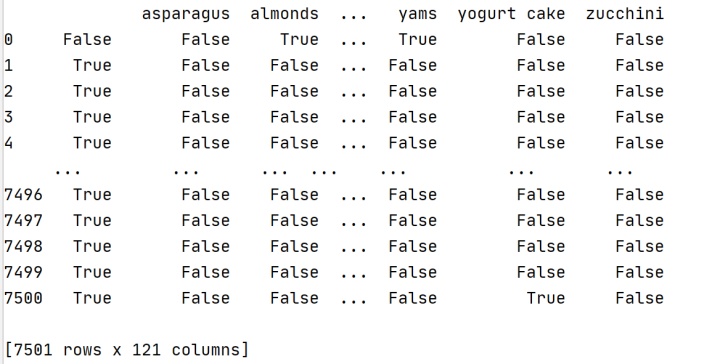
挖掘频繁项集:
from mlxtend.frequent_patterns import apriori
freq_items = apriori(df_records,min_support=0.05,use_colnames=True)
#min_support默认值为0.5,这里设置为0.05这么小,是因为设置太大了根本找不到频繁项集……
#设置use_colnames=True是为了在显示频繁项集时,使用商品名称,而不是商品所在列的索引值
print(freq_items)结果如下:
support itemsets
0 0.999867 ()
1 0.087188 (burgers)
2 0.081056 (cake)
3 0.059992 (chicken)
4 0.163845 (chocolate)
5 0.080389 (cookies)
6 0.051060 (cooking oil)
7 0.179709 (eggs)
8 0.079323 (escalope)
9 0.170911 (french fries)
10 0.063325 (frozen smoothie)
11 0.095321 (frozen vegetables)
12 0.052393 (grated cheese)
13 0.132116 (green tea)
14 0.098254 (ground beef)
15 0.076523 (low fat yogurt)
16 0.129583 (milk)
17 0.238368 (mineral water)
18 0.065858 (olive oil)
19 0.095054 (pancakes)
20 0.071457 (shrimp)
21 0.050527 (soup)
22 0.174110 (spaghetti)
23 0.068391 (tomatoes)
24 0.062525 (turkey)
25 0.058526 (whole wheat rice)
26 0.087188 (, burgers)
27 0.081056 (, cake)
28 0.059992 (, chicken)
29 0.163845 (, chocolate)
30 0.080389 (, cookies)
31 0.051060 (, cooking oil)
32 0.179709 (, eggs)
33 0.079323 (, escalope)
34 0.170911 (, french fries)
35 0.063192 (, frozen smoothie)
36 0.095321 (, frozen vegetables)
37 0.052393 (, grated cheese)
38 0.131982 (, green tea)
39 0.098254 (, ground beef)
40 0.076390 (, low fat yogurt)
41 0.129583 (, milk)
42 0.238235 (, mineral water)
43 0.065725 (, olive oil)
44 0.095054 (, pancakes)
45 0.071324 (, shrimp)
46 0.050527 (, soup)
47 0.174110 (, spaghetti)
48 0.068391 (, tomatoes)
49 0.062525 (, turkey)
50 0.058526 (, whole wheat rice)
51 0.052660 (mineral water, chocolate)
52 0.050927 (eggs, mineral water)
53 0.059725 (spaghetti, mineral water)
54 0.052660 (, mineral water, chocolate)
55 0.050927 (, eggs, mineral water)
56 0.059725 (, spaghetti, mineral water)由上可以看到,有一些被高频次购买的单品,如burgers、cake、chicken……也有一些被一起高频购买的商品组合,如(mineral water, chocolate),(eggs, mineral water)……
接下来使用association_rules()函数进行关联规则挖掘:
查看association_rules()函数帮助文档:
from mlxtend.frequent_patterns import association_rules
help(association_rules)
Help on function association_rules in module mlxtend.frequent_patterns.association_rules:
association_rules(df, metric='confidence', min_threshold=0.8, support_only=False)
Generates a DataFrame of association rules including the
metrics 'score', 'confidence', and 'lift'
Parameters
-----------
df : pandas DataFrame
pandas DataFrame of frequent itemsets#输入数据为频繁项集,即apriori算法返回的结果
with columns ['support', 'itemsets']
metric : string (default: 'confidence')#默认度量指标为置信度
Metric to evaluate if a rule is of interest.
**Automatically set to 'support' if `support_only=True`.**
Otherwise, supported metrics are 'support', 'confidence', 'lift',
'leverage', and 'conviction'
These metrics are computed as follows:
- support(A->C) = support(A+C) [aka 'support'], range: [0, 1]#支持度取值范围为0~1
- confidence(A->C) = support(A+C) / support(A), range: [0, 1]#置信度取值范围为0~1
- lift(A->C) = confidence(A->C) / support(C), range: [0, inf]#提升度(lift)取值范围为0到正无穷
- leverage(A->C) = support(A->C) - support(A)*support(C),
range: [-1, 1]
- conviction = [1 - support(C)] / [1 - confidence(A->C)],
range: [0, inf]
min_threshold : float (default: 0.8)
Minimal threshold for the evaluation metric,
via the `metric` parameter,
to decide whether a candidate rule is of interest.
support_only : bool (default: False)
Only computes the rule support and fills the other
metric columns with NaNs. This is useful if:
a) the input DataFrame is incomplete, e.g., does
not contain support values for all rule antecedents
and consequents
b) you simply want to speed up the computation because
you don't need the other metrics.
Returns
----------
pandas DataFrame with columns "antecedents" and "consequents"
that store itemsets, plus the scoring metric columns:
"antecedent support", "consequent support",
"support", "confidence", "lift",
"leverage", "conviction"
of all rules for which
metric(rule) >= min_threshold.
Each entry in the "antecedents" and "consequents" columns are
of type `frozenset`, which is a Python built-in type that
behaves similarly to sets except that it is immutable.进行关联规则挖掘:
from mlxtend.frequent_patterns import association_rules
association_rules_1 = association_rules(freq_items,metric='confidence',min_threshold=0.2)
#默认的min_threshold=0.8,但是这么高的情况下,找不到关联规则,于是不断降低门槛……
print(association_rules_1)部分结果如下:
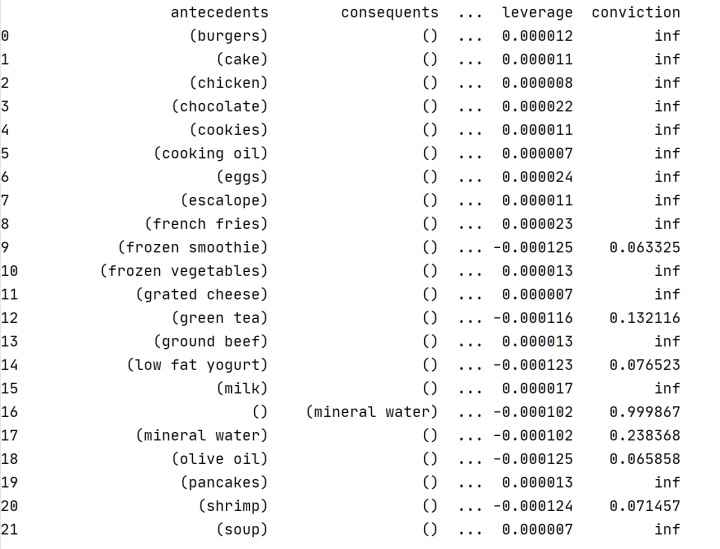
由于显示不完全,可以使用to_csv()方法将结果导出到excel表格:
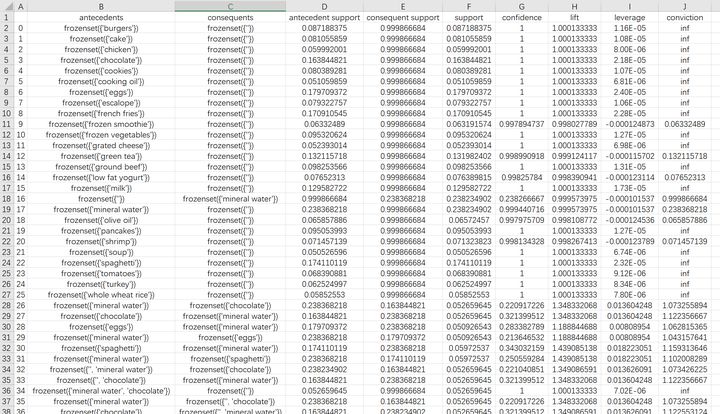
association_rules_1.to_csv(path_or_buf='C:UsersCaraDesktopassociation_rules.csv')结果如下:
附:全部Python代码
#导入数据
import pandas as pd
path = 'C:UsersCaraDesktopstore_data.csv'
records = pd.read_csv(path,header=None,encoding='utf-8',na_filter=False)
#na_filter=False,表示空值导入后会显示为空,而不是NaN
print(records)
#将数据框转为嵌套列表
import numpy as np
lst_records = np.array(records).tolist()
print(lst_records)
#对交易数据进行one-hot编码
from mlxtend.preprocessing import TransactionEncoder
TE = TransactionEncoder()#类实例化
one_hot_records = TE.fit(lst_records).transform(lst_records)
print(one_hot_records)
#数据格式转为数据框
df_records = pd.DataFrame(data = one_hot_records,columns = TE.columns_)
print(df_records)
#挖掘频繁项集
from mlxtend.frequent_patterns import apriori
freq_items = apriori(df_records,min_support=0.05,use_colnames=True)
print(freq_items)
#挖掘关联规则
from mlxtend.frequent_patterns import association_rules
association_rules_1 = association_rules(freq_items,metric='confidence',min_threshold=0.2)
print(association_rules_1)
#导出关联规则挖掘结果
association_rules_1.to_csv(path_or_buf='C:UsersCaraDesktopassociation_rules.csv')参考资料:
Python --深入浅出Apriori关联分析算法(一)www.cnblogs.com


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









