






引言
随着科技的发展和网络技术的进步,计算机存储空间愈加紧张,存储空间对文件系统的功能需求越来越大,大规模的数据增长为文件存储、非结构化数据存储提出了新的挑战。
对于许多物联网设备而言,拥有一个小型且具有弹性的文件系统至关重要,littlefs文件系统应运而生。littlefs文件系统在2017年由Christopher Haster开发,遵循Apache 2.0协议,被应用在ARM的IoT设备Mbed操作系统。littlefs文件系统能够让嵌入式系统在ROM和RAM资源有限的情况下,还具备文件系统基本的掉电恢复、磨损均衡的功能。
littlefs是一种极简的嵌入式文件系统,适配于norflash,它所采用的文件系统结构与运行机制,使得文件系统的存储结构更加紧凑,运行中对RAM的消耗更小。它的设计策略采用了与传统“使用空间换时间”完全相反的“使用时间换空间”的策略,虽然它极大地压缩了文件系统存储空间,但是运行时也增加了RAM的消耗,不可避免地带来了随机读写时IO性能的降低。
目前,OpenAtom OpenHarmony(以下简称“OpenHarmony”) liteos_m内核采用了littlefs作为默认的文件系统。本文着重介绍了littlefs文件系统的存储结构,并根据对读写过程的分析,解析引起littlefs文件系统随机读写IO性能瓶颈的根本原因,然后提出一些提升littlefs随机读写IO性能优化策略。
littlefs文件系统结构
文件系统存储结构信息基本以SuperBlock为开端,然后寻找到文件系统根节点,再根据根节点,逐步拓展成一个文件系统树形结构体。littlefs也与此类似,以SuperBlock和根目录为起点,构建了一个树形存储结构。不同的是littlefs的根(“/”)直接附加在SuperBlock之后,与其共享元数据对(metadata pair)。littlefs中目录或者文件都是以该根节点为起点,构建了与其他文件系统类似的树形结构。
littlefs文件系统树形存储结构如下:
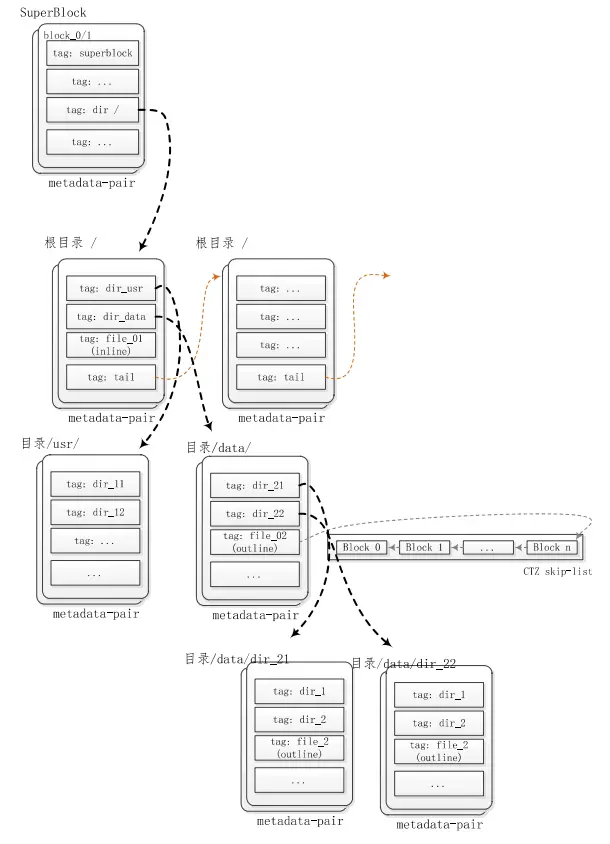
图1 littlefs文件系统树形存储结构示意图
如图1所示,存储littlefs文件系统元数据的结构为元数据对,即两个相互轮转、互为表里的Block。存储SuperBlock的元数据对固定存储在block 0和block 1,并且文件系统根目录附加在SuperBlock的尾部,与SuperBlock共享元数据对。元数据的存储是以tag的格式存储在元数据对内,按照元数据的类型,将Tag分为标准文件、目录、用户数据、元数据对尾部指针等类型。littlefs借助于这些不同类型tag信息,将littlefs文件系统组织成结构紧凑的树形存储结构体。例如tail类型的tag可以将比较大的目录结构使用多个元数据对存储,并且使用tail类型的tag将这些元数据对连接成一个单向的链表。而目录类型的tag则直接指向该目录的元数据对,例如"tag: dir_data"类型的tag指向目录"/data"的元数据对,而该元数据对中又可以包含子目录或者文件(Inline类型或者outline类型)。
littlefs目录存储结构
littlefs目录的引用为其父目录元数据对(metadata pair)内的一个dir类型的Tag,而其内容则占用一个或者多个元数据对。一个目录的元数据对内既可以包含子目录引用的Tag,也可以包含属于该目录下文件的Inline类型的Tag或者指向该文件的CTZ跳表的CTZ类型Tag指针。最终littlefs通过一层层目录或者文件的索引,组成了文件系统的树形存储结构。
littlefs文件存储方式
littlefs文件系统为极简的文件系统,使用最小的存储开销,同时实现对小文件(Bytes级别)和大文件(MB级别)的支持,对小于一个Block八分之一长度的文件,采用Inline类型的方式存储,而大于或者等于Block八分之一长度的文件则采用Outline的方式存储(CTZ Skip-list)。
** 1.2.1 inline文件存储方式**
Inline文件存储方式,如图2所示,即将文件内容与文件名称一同存储在其父目录的元数据对(metadata pair)内,一个Tag表示其名称,一个Tag表示其内容。
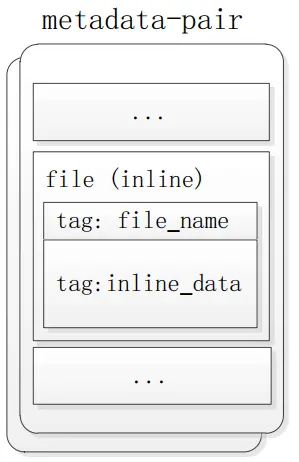
图2 littlefs Inline文件存储结构
1.2.2 outline文件存储方式
Outline文件存储方式,如图3所示,文件其父目录的元数据对(metadata pair)内,一个Tag表示文件名称,另一个Tag为CTZ类型,其指向存储文件内容的链表头。
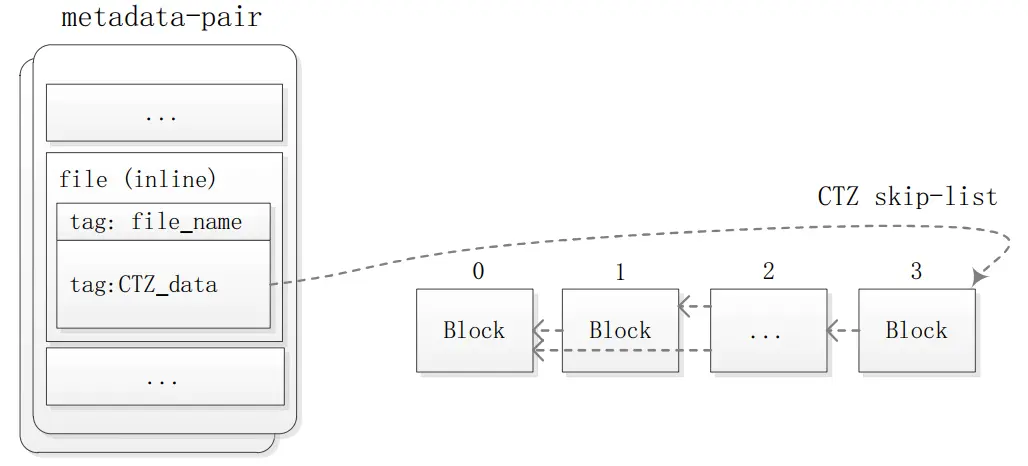
图3 littlefs Outline文件存储结构
CTZ跳表(CTZ skip-list)链表的特别之处是:
(1)CTZ跳表的头部指向链表的结尾;
(2)CTZ跳表内Block内包含一个以上的跳转指针。
若是使用常规链表,存储文件前一个数据块包含指向后一个数据块指针,那么在文件追加或者修改内容的时候,则需要存储文件起始块到目标块的所有内容拷贝到新块内,并且更新对后一个数据块的指针。而若是采用反向链表的方式,则在文件追加或者修改内容的时候,则只需要将存储文件目标块到链表结尾的块的所有内容拷贝到新块内,然后更新对后一个数据块内对前一个数据块指向的指针,这样对于文件追加模式可以减少修改量。另外,为了加快索引,采用了跳表的方式,Block内包含一个以上的跳转指针,规则为:若一个数据块在CTZ skip-list链表内的索引值N能被 2^X整除的数,那么他就存在指向N – 2^X的指针,指针的数目为ctz(N)+1。如表1,对于block 2,包含了2个指针,分别指向block 0和block 1,其它块也是采用相同的规则。
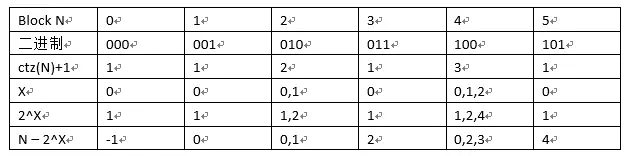
表1 littlefs 块的skip-list链表计算样表
littlefs文件读写流程
以上章节针对littlefs文件系统结构进行了分析,接下来开始探讨littlefs内部的运行机制,以读写流程为例,分析littlefs随机读写的IO性能瓶颈。
需要提前了解的是,littlefs的文件只拥有一个缓存,写时作为写缓存使用,读时作为读缓存使用。
littlefs文件读过程
以下图4是littlefs读文件的流程图,在读流程的开始先检测先前是否有对文件的写操作,即检测文件缓存是否作为写缓存。若是,则强制将缓存中的数据刷新到存储器,根据文件类型和访问位置,或者直接从文件所在的元数据对读取,或者从存储文件内容的CTZ跳表内的块内读取,再将数据拷贝到用户缓存冲,并从存储器预读取数据将文件缓冲区填满。具体过程如下:
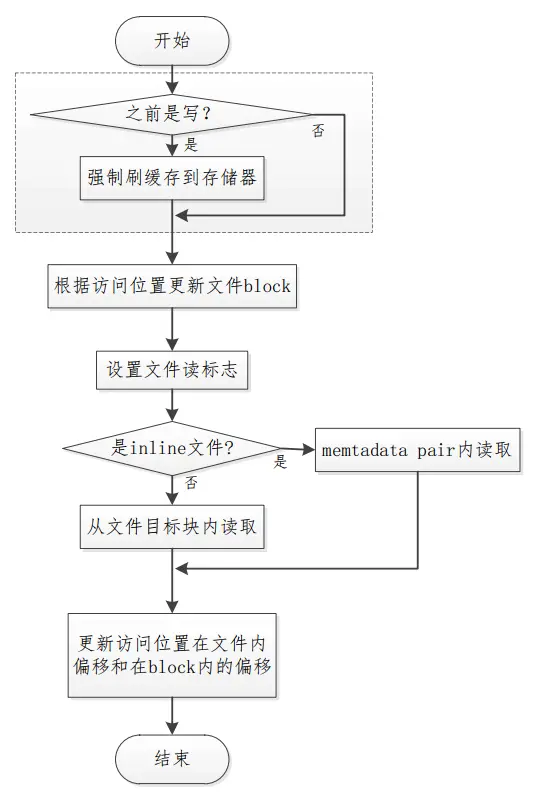
图4 littlefs文件系统读过程流程图
littlefs文件写过程
以下图5是littlefs写文件的流程图,在写流程的开始先检测先前是否有对文件的读操作,即检测文件缓存是否作为读缓存。若是,则清除缓存中的数据。若是APPEND类型的写操作,则直接减写位置定位到文件末尾。若写位置超过文件长度,说明文件结尾与写位置间存在空洞,则使用0填充文件中的空洞。对应Inline类型文件,若推测到写后,文件长度超过了阈值,则将文件转成Outline类型。对于Outline类型的文件,若是修改文件的内容,则需要申请新块,并将目标块内访问位置之前的所有内容都拷贝到新块,将buffer中的用户数据写到缓冲区或者刷新到存储器。
注意:写后并没有立刻更新Inline文件的commit,或者更新Outline文件的CTZ跳表,这些操作被延迟在文件关闭或者缓冲区再次作为读缓存的时候强制文件刷新时更新。
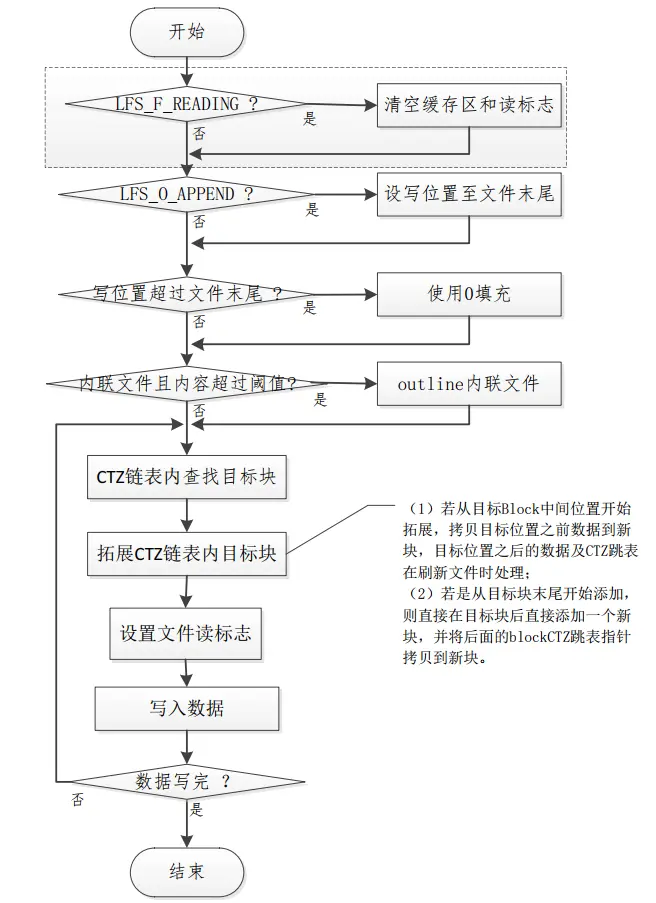
图5 littlefs文件系统写过程流程图
littlefs文件随机读写IO性能瓶颈分析
littlefs文件只有一个缓冲区,为读写复用。根据littlefs运行机制,若是对文件先读后写,那么仅需要直接将缓冲区的数据清空,然后申请一个新块将目标块内访问位置直接的数据拷贝到新块中,然后写数据到新块。若是先写后读,那么需要将数据刷新到存储器,同时更新文件的CTZ跳表。在这个过程中,不仅涉及到刷新数据到存储器,而且涉及到分配新块替换目标块之后的所有块从而更新CTZ跳表,出现多次费时的擦除块动作。在随机读写的过程中,频繁发生读写切换,也就频繁地发生申请新块、擦除新块(非常费时)、数据搬移等等动作,严重地影响了IO性能。
littlefs读写IO性能优化策略
由“2.3 littlefs文件随机读写IO性能瓶颈分析”章节描述可知,影响littlefs文件随机读写IO性能的主要原因是文件只有一个的缓存且被读写复用,造成在读写切换的过程中频繁地发生文件刷新,申请新块,然后执行费时的块擦除,再将CTZ跳表上块内的block内容搬移到新块,进而更新CTZ跳表,这严重影响了随机读写IO的性能。
所以,在RAM空间允许的情况下,可以考虑“使用空间换时间”的策略,适当地增加文件缓存的数量,使一个文件拥有多个缓冲区,而这些缓冲区对应着一个Block的大小,在一定的条件下一次刷新一个Block,从而避免过多的数据搬移。另外,littlefs的策略是“使用时间换空间”,但是每个文件都拥有一个缓冲区明显浪费空间。因为在一段时间内,只会有一定数量的文件被执行读或者写,所以可以考虑建立一个拥有一定数量的缓存池,使缓存在文件间共享。
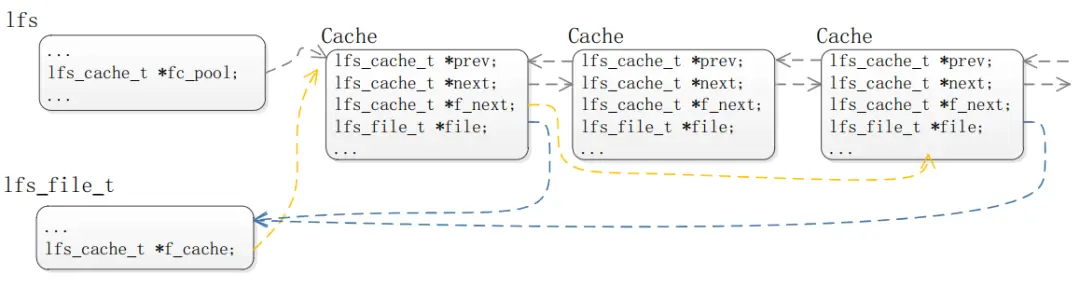
图6 littlefs优化策略
优化的策略如图6所示,littlefs文件缓存池为一个双向链表fc_pool,缓存池随着被打开文件的个数的增长而延长,直到用户设置的最大限制;缓存池随着文件的关闭而逐渐缩减。
每个缓存挂载在fc_pool缓存池双向链表上,当缓存被写或者被读时,则将缓存移到链表开头,那么缓存池链表末尾的缓存则为待老化的缓存,可以优先被选择回收。
在申请缓存时,优先从缓冲池链表末尾选择空闲缓存;若无空闲缓存,则考虑抢占读缓存;若缓存池既没有空闲缓存也没有读缓存,在缓存池长度没有达到优化限制的情况下,则创建新缓存,然后将新缓冲添加到链表头;若缓存池既没有空闲缓存也没有读缓存,并且缓存池长度已经达到用户限制,那么就需要从链表末尾抢占一个写缓存,并强制占有该缓存的文件执行刷新,进而完成抢占。
在文件被关闭或者刷新时,主动释放缓存到缓存池,挂载在双向链表的末尾。
使用上述策略对文件缓存进行优化,可以在一定程度上减少因更新文件内容而执行的存储器块擦除动作,从而增加随机读写的IO性能,也间接地延长了NorFlash的寿命。
总结
通过本文的讲解,相信大家对于littlefs文件系统有了较为全面的了解。总的来说,littlefs是一种极简的文件系统,实现了文件系统基本的数据缓存、掉电恢复、磨损均衡等功能,在资源相对富裕的环境中,开发者们可以对其运行机制甚至存储结构进行“使用空间换时间”的优化策略,提升读写的IO性能。学会有效地利用文件系统往往能起到事半功倍的作用,希望开发者能够将所学知识有效应用到未来的开发工作中,从而提高开发工作的效率。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









