






目录
问题描述:
java后端使用 Apache 的 POI导出 Word,涉及到两个 Word 模板合并的时候,合并后的文件打开出现下图中的问题!
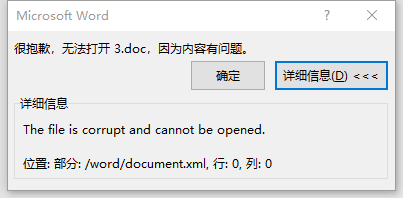
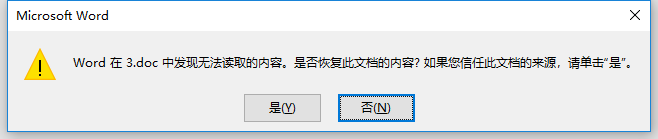
问题发现:
问题排查:
该博客中提到是 标签的问题,由此我写了一个标签匹配方法
/** 获取指定标签中的内容
* @param xml
* @param label
* @return
*/
public static String regex(String xml, String label) {
String context = "";
// 正则表达式
String rgex = "]*>((?:(?!)[\\s\\S])*)";
Pattern pattern = Pattern.compile(rgex);// 匹配的模式
Matcher m = pattern.matcher(xml);
// 匹配的有多个
List list = new ArrayList();
while (m.find()) {
int i = 1;
list.add(m.group(i));
i++;
}
if (list.size() > 0) {
// 输出内容自己定义
context = String.valueOf(list.size());
}
return context;
}
然后在 POI 合并的时候检查一下 POI 将 Word 转为 xml 后 w:sectPr 标签情况
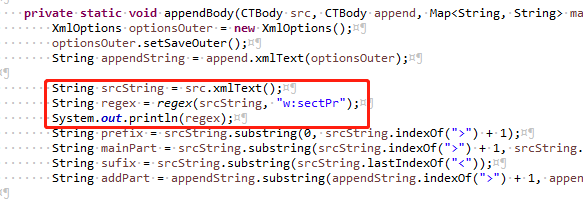
/** 两个对象进行追加
* 2019-06-26 houzw添加
* @param src 目标文档
* @param append 子文档
* @return
* @throws Exception
*/
public static XWPFDocument mergeWord(XWPFDocument src, XWPFDocument append) throws Exception {
// XWPFParagraph paragraph = src.createParagraph();
// //设置分页符
// paragraph.setPageBreak(true);
CTBody src1Body = src.getDocument().getBody();
CTBody src2Body = append.getDocument().getBody();
List allPictures = append.getAllPictures();
// 记录图片合并前及合并后的ID
Map map = new HashMap();
for (XWPFPictureData picture : allPictures) {
String before = append.getRelationId(picture);
// 将原文档中的图片加入到目标文档中
String after = src.addPictureData(picture.getData(), Document.PICTURE_TYPE_PNG);
map.put(before, after);
}
appendBody(src1Body, src2Body, map);
return src;
}
private static void appendBody(CTBody src, CTBody append, Map map) throws Exception {
XmlOptions optionsOuter = new XmlOptions();
optionsOuter.setSaveOuter();
String appendString = append.xmlText(optionsOuter);
String srcString = src.xmlText();
String regex = regex(srcString, "w:sectPr");
System.out.println(regex);
String prefix = srcString.substring(0, srcString.indexOf(">") + 1);
String mainPart = srcString.substring(srcString.indexOf(">") + 1, srcString.lastIndexOf("
String sufix = srcString.substring(srcString.lastIndexOf("
String addPart = appendString.substring(appendString.indexOf(">") + 1, appendString.lastIndexOf("
if (map != null && !map.isEmpty()) {
// 对xml字符串中图片ID进行替换
for (Map.Entry set : map.entrySet()) {
addPart = addPart.replace(set.getKey(), set.getValue());
}
}
// 将两个文档的xml内容进行拼接
CTBody makeBody = CTBody.Factory.parse(prefix + mainPart + addPart + sufix);
src.set(makeBody);
}
合并三个 word 文档,结果输出 2 也就是说前两个文档合并后 w:sectPr 标签有两个。因为我输出的是目标模板合并前的 w:sectPr 标签情况。
解决具体方法
去掉追加word内容中的 w:sectPr 标签,确保合成的word中只有一个 w:sectPr 标签对
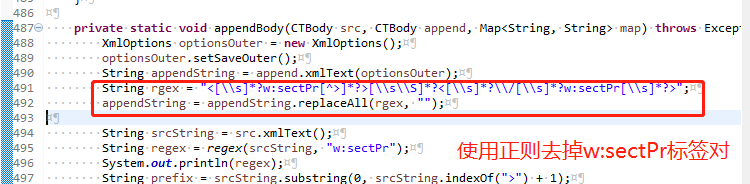
String rgex = "]*?>[\\s\\S]*?";
appendString = appendString.replaceAll(rgex, "");
至此问题解决!问题总是具有片面性,真诚希望各位看官斧正,有新的观点留言我,大家一起交流学习。
谢谢各位,祝大家玩的开心。
标签:src,CTBody,opened,标签,cannot,doxc,srcString,append,String
来源: https://www.cnblogs.com/himonkey/p/11110726.html














 1413
1413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









