






首先,我先定义一个文件,hello.txt,里面的内容如下:
hello spark
hello hadoop
hello flink
hello storm
Scala方式
scala版本是2.11.8。
配置maven文件,三个依赖:
org.apache.hadoop
hadoop-client
2.6.0-cdh5.7.0
org.scala-lang
scala-library
2.11.8
org.apache.spark
spark-core_2.11
2.2.0
packagecom.darrenchan.sparkimportorg.apache.spark.{SparkConf, SparkContext}
object SparkCoreApp2 {
def main(args: Array[String]): Unit={
val sparkConf= new SparkConf().setMaster("local[2]").setAppName("WordCountApp")
val sc= newSparkContext(sparkConf)//业务逻辑
val counts = sc.textFile("D:\\hello.txt").
flatMap(_.split(" ")).
map((_,1)).
reduceByKey(_+_)
println(counts.collect().mkString("\n"))
sc.stop()
}
}
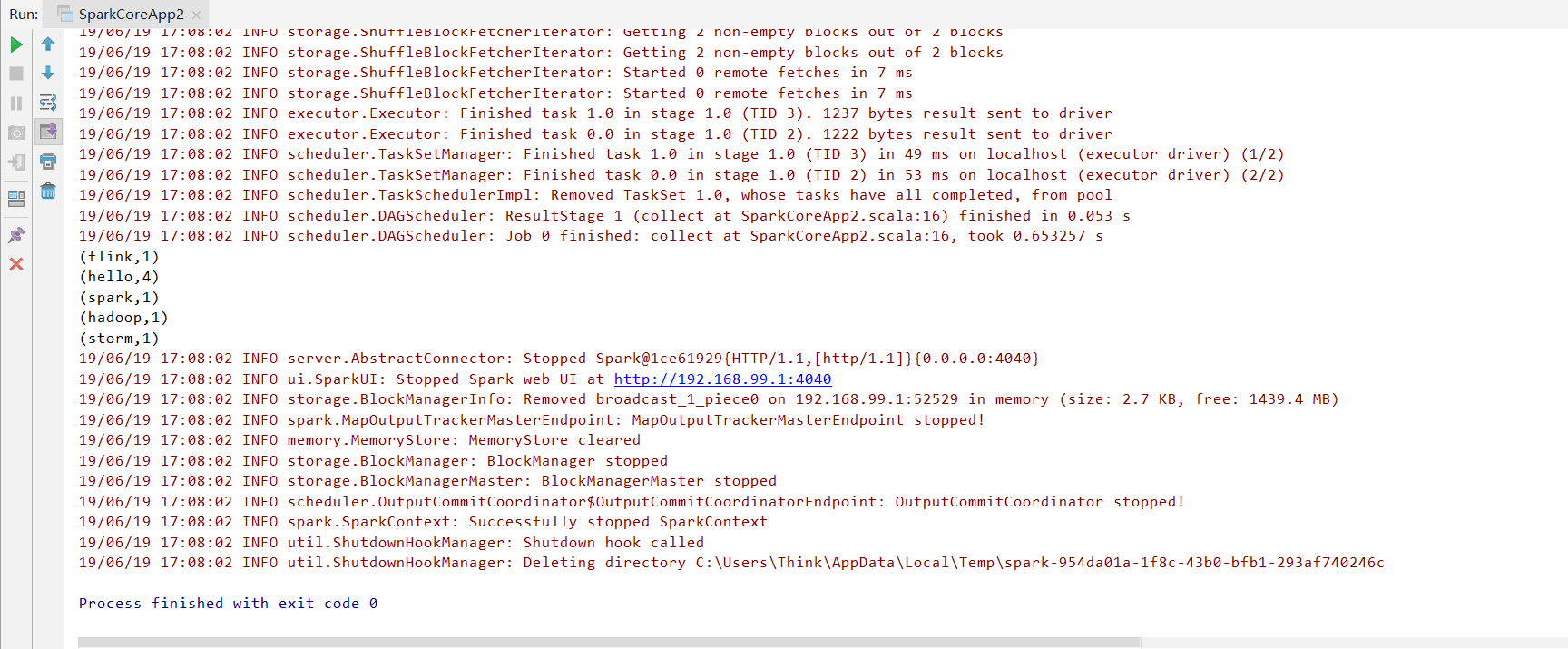
运行结果:
Java方式
Java8,用lamda表达式。
packagecom.darrenchan.spark.javaapi;importorg.apache.spark.SparkConf;importorg.apache.spark.SparkContext;importorg.apache.spark.api.java.JavaPairRDD;importorg.apache.spark.api.java.JavaRDD;importorg.apache.spark.api.java.JavaSparkContext;importorg.apache.spark.sql.SparkSession;importscala.Tuple2;importjava.util.Arrays;public classWordCountApp2 {public static voidmain(String[] args) {
SparkConf sparkConf= new SparkConf().setMaster("local[2]").setAppName("WordCountApp");
JavaSparkContext sc= newJavaSparkContext(sparkConf);//业务逻辑
JavaPairRDD counts =sc.textFile("D:\\hello.txt").
flatMap(line-> Arrays.asList(line.split(" ")).iterator()).
mapToPair(word-> new Tuple2<>(word, 1)).
reduceByKey((a, b)-> a +b);
System.out.println(counts.collect());
sc.stop();
}
}
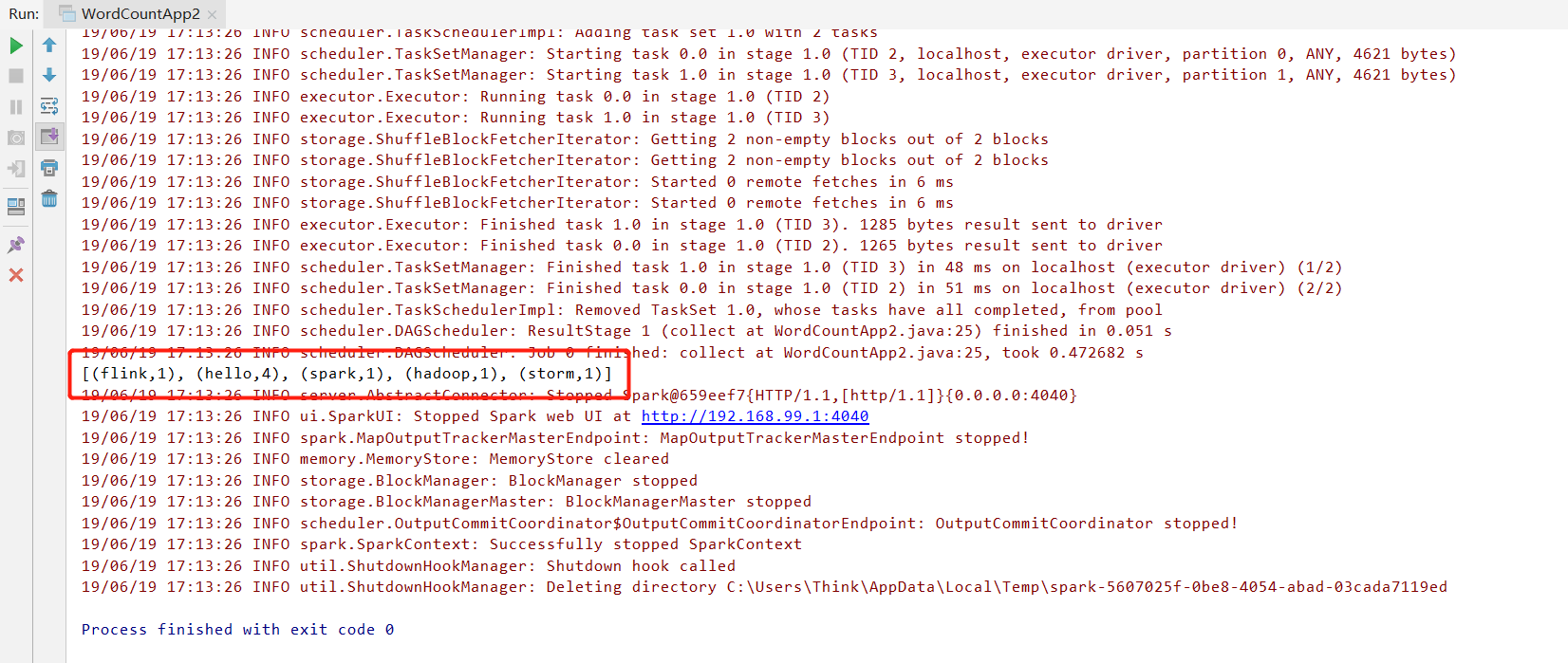
运行结果:
Python方式
Python 3.6.5。
from pyspark importSparkConf, SparkContextdefmain():#创建SparkConf,设置Spark相关的参数信息
conf = SparkConf().setMaster("local[2]").setAppName("spark_app")#创建SparkContext
sc = SparkContext(conf=conf)#业务逻辑开发
counts = sc.textFile("D:\\hello.txt").\
flatMap(lambda line: line.split(" ")).\
map(lambda word: (word, 1)).\
reduceByKey(lambda a, b: a +b)print(counts.collect())
sc.stop()if __name__ == '__main__':
main()
运行结果:

使用Python在Windows下运行Spark有很多坑,详见如下链接:















 2115
2115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









