






在搭建数据通道(data pipeline)时,由于涉及到:数据读取,数据分析,数据存储等等,
如果将各个部分分别容器化,独立设计各个模块,将有助于缩短开发时间。
这里以一个基于 Kafka 和 Spark Streaming 的实时流 data pipeline 为例,介绍如何使用 docker compose 分别搭建各个服务并实现快速demo。
整体架构
使用 Apache Kafka 作为数据总线, 进行数据的收集与分发。通过 Spark Streaming 实现数据的实时处理,并将结果数据存储到 MySQL 中。
具体结构如图:
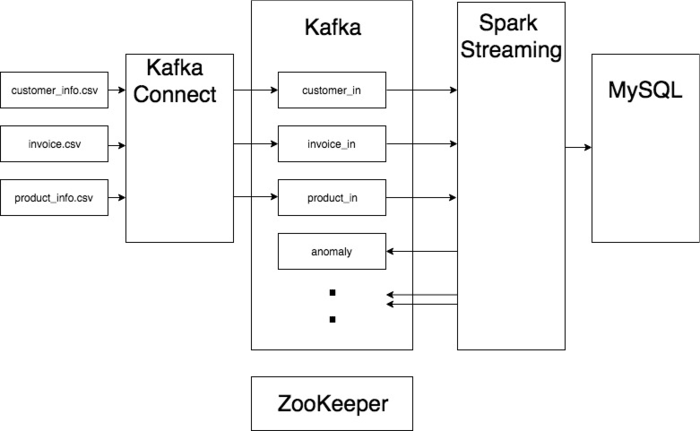
数据读取
实例中需要分析来自 csv文件的数据。为了将文件数据导入 Kafka,可以使用 Kafka Connect。
不同文件中的数据将被 Kafka Connect 导入 Kafka 中专门的 topic。
数据分析
Spark Streaming 可以方便地接收来自 Kafka 的实时数据。
这个Demo中使用的数据源为来自文件的批数据,不过Demo中的架构同样可以处理流数据。
数据存储
经过 Spark Streaming 分析得到的结果,将被导入 MySQL,方便之后的查询。同时,也可以导入 Kafka 中对应的 topic。例如异常分析的结果可以放入名为anomaly的 topic。
docker compose 管理
使用 docker compose 来管理上述众多服务。 由于主要的处理逻辑都放在了 Spark Streaming 中,需要自行编写Dockerfile,其它各个服务都可以直接使用来自 Docker Hub的镜像。
ZooKeeper服务zoo1: image: wurstmeister/zookeeper restart: unless-stopped hostname: zoo1 ports: - "2181:2181" container_name: pipeline-zookeeper
Kafka服务
使用来自 confluent 的 kafka 镜像。
仅用作Demo测试架构可行性,因此 kafka 仅含一个 broker, topic 的 partition 数以及 replication factor 也因此为1.kafka1: image: confluentinc/cp-kafka:4.0.0 hostname: kafka1 ports: - "9092:9092" environment: KAFKA_ADVERTISED_LISTENERS: "PLAINTEXT://kafka1:9092" KAFKA_ZOOKEEPER_CONNECT: "zoo1:2181" KAFKA_BROKER_ID: 1 KAFKA_LOG4J_LOGGERS: "kafka.controller=INFO,kafka.producer.async.DefaultEventHandler=INFO,state.change.logger=INFO" KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1 depends_on: - zoo1 container_name: pipeline-kafka
Kafka Connect服务
Kafka Connect 需要知道 Kafka 集群的信息。在 docker compose 内可以用服务名称即 kafka1 直接指代我们之前配置的 kafka broker。
这里配置的仅仅是 Kafka Connect Worker,具体的connect任务,即连接什么数据源,连接到kafka中的哪个topic去,需要在Kafka Connect服务启动后,通过 REST API 提交。kafka-connect: image: confluentinc/cp-kafka-connect:4.0.0 hostname: kafka-connect ports: - "8083:8083" environment: CONNECT_BOOTSTRAP_SERVERS: "kafka1:9092" CONNECT_REST_PORT: 8083 CONNECT_GROUP_ID: compose-connect-group1 CONNECT_CONFIG_STORAGE_TOPIC: docker-connect-configs CONNECT_OFFSET_STORAGE_TOPIC: docker-connect-offsets CONNECT_STATUS_STORAGE_TOPIC: docker-connect-status CONNECT_KEY_CONVERTER: org.apache.kafka.connect.storage.StringConverter CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL: 'http://kafka-schema-registry:8081' CONNECT_VALUE_CONVERTER: org.apache.kafka.connect.storage.StringConverter CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: 'http://kafka-schema-registry:8081' CONNECT_INTERNAL_KEY_CONVERTER: "org.apache.kafka.connect.json.JsonConverter" CONNECT_INTERNAL_VALUE_CONVERTER: "org.apache.kafka.connect.json.JsonConverter" CONNECT_REST_ADVERTISED_HOST_NAME: "kafka-connect" CONNECT_LOG4J_ROOT_LOGLEVEL: "INFO" CONNECT_LOG4J_LOGGERS: "org.apache.kafka.connect.runtime.rest=WARN,org.reflections=ERROR" CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: "1" CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: "1" CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: "1" volumes: - ./data:/data depends_on: - zoo1 - kafka1 container_name: pipeline-kafka-connect
Spark Streaming服务
Spark Streaming 服务build自本地路径./spark-streaming。
路径下放有Dockerfile,requirements.txt,以及存放处理逻辑的main文件夹。spark-streaming: build: ./spark-streaming ports: - "8081:8081" volumes: - ./log:/spark-streaming/log depends_on: - kafka1 container_name: pipeline-spark-streaming
MySQL服务
在environment下设置数据库名称与密码。
同时可以在command下声明初始化文件,创建项目中需要的表格。mysql: image: mysql:5.6.34 restart: always environment: MYSQL_DATABASE: "data_pipeline" MYSQL_ROOT_PASSWORD: "233" MYSQL_ALLOW_EMPTY_PASSWORD: "no" command: --init-file /tmp/create_db.sql volumes: - ./mysql/create_db.sql:/tmp/create_db.sql ports: - "3306:3306" container_name: pipeline-mysql
本文由职坐标整理发布,学习更多的MySQL数据库知识,请关注职坐标MySQL频道!















 836
836











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









