






导读
网络爬虫(Web crawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。
一.什么是爬虫
爬虫就像是一直蜘蛛一样 ,而互联网是就像是一张大大的蜘蛛网一样。简单的说爬虫就是请求网站并提取数据的自动化程序。
请求:我们打开浏览器输入关键词敲击回车,这就叫做是请求。我们做的爬虫就是模拟浏览器进行对服务器发送请求,然后获取这些网络资源。
提取:我们得到这些网络资源都是一些HTML代码,或者是一些文本文字。我们下一步做的工作就是在这些数据中提取出我们想要的东西。比如一个手机号。存在数据库或者文档里面。
自动化:程序就能代替人工不停的大量的进行提取数据。
二:爬虫的基本流程
1.发起请求:通过http库向目标站发起请求,即发送一个Request,请求可以包含额外的headers等信息,等待服务器响应。
2.获取响应的内容:如果服务器能正常的响应,会得到一个Request的内容便是所要获取的页面内容、类型可能有HTML,Json字符转,二进制数据等类型
3.解析内容:得到的内容可能是HTML可以用正则表达式,网页解析库进行解析。可能是json,可以直接转为json对象解析,可能是二进制数据,可以做保存或者进一步处理。
4.保存数据:保存格式多样化,可以存为文本,也可以保存至数据库,或者保存特定格式的文件。
三:什么是Request和Response
1.浏览器就发送消息给该网址所在的服务器,这个过程叫做HTTP Request。
2.服务器收到浏览器发送的消息后,能够根据浏览器发送消息的内容,做相应处理,然后把消息回传给浏览器。这个过程叫做HTTP Response。
3.浏览器收到服务器的Response信息后,会对信息进行相应处理,然后展示。
四:Request包含什么
1.请求方式:主要有Get,Post两种类型,另外还有Head,put,delete,options等。
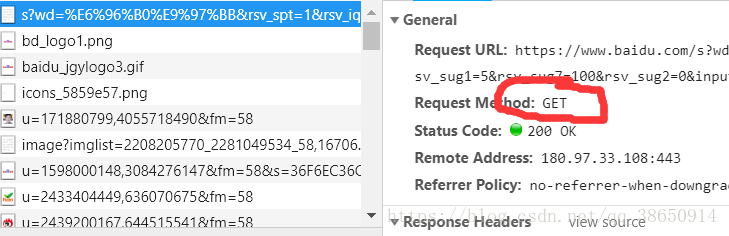
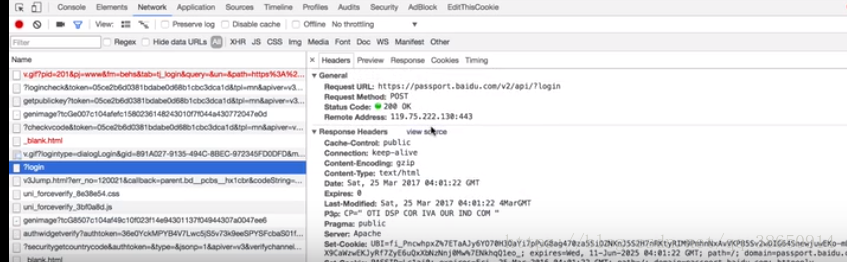
最主要的就是get和pose两种请求方式。pose请求的方式大多是用在登陆的请求上,他将许多的请求参数封装在一起,进行保密。get则是需要很多的参数才可以,用于搜索。
2.请求URL
URL全称统一资源定位符,如一个网页文档、一张图片,一个视频等都可以用URL唯来确定。
3.请求头:包含请求时的头部信息,如User-Agent,Host,Cookie等信息。
五:Response包含什么
1.响应状态:200代表成功,300以上的状态时用来做页面跳转的,400以上是用来说明服务器找不到资源的,500以上时表示服务器处理错误。
2.响应头:如内容的类型,内容的长度,服务器信息,,设置Cookie信息等等
3.响应体:最主要的部分,包含了请求资源的内容,如网页的HTML,图片二进制数据等















 185
185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









