







mysql的主从同步给构建大型系统带来了无限的可能性,接下来我们就简单介绍一下mysql的主动同步的基本原理以及实现方式。
什么是主从同步
在mysql集群这个体系中,mysql会单独拿出一台机器作为主机器master,我们所有的insert,update,delete操作全部都在这台master服务器的库上,然后其他的机器全部作为这台机去的从节点slave,从节点的mysql会去master机器上获取最近一段时间的操作(通常很短暂),然后同步更新自己的数据,这样就达到了主从同步的操作。
这样的不同于传统的单机操作模式,带来的好处就是可以实现读写分离,集群扩展,数据的分区容错和高可用,数据备份等。
主从同步实现方式
那么,mysql是通过怎样的一种方式来实现主从同步的呢?其实很简单,在mysql内部,会有一个特殊的文件来记录着master上发生的一切,这个文件被叫做binary-log,俗称bin-log,这个文件所记录的操作被成为主从同步事件,每一个事件代表着一系列的intert,update,delete等操作,总体上,主从同步事件又大致分为三种:statement 即master上执行的所有sql语句会被完整的记录到bin-log中
row 即每一条记录的变化情况会被记录到bin-log中
mix 即同时混合前面的两种事件,结合使用
当slave机器连接到master机器上时,master机器会开启一个叫做bin-dump的线程来管理这一个连接,当master的bin-log有改变的时候,dump线程会通知slave机器,同时将自己的更新内容同步给slave机器节点中。所以,一主多从下,master会有多个dump线程来维护多个slave服务器
同时,slave机器自身也会开启两个线程,一个叫做io线程,一个叫做sql线程,具体操作过程如下:io线程:接受master返回的bin-log中的更新内容,记录到本地的一个叫做中继日志中(relay.log),当同步完成后,它会休眠,直到下一次master有更新时,通知它。
sql线程:从中继日志中获取最新的改变内容,然后在本地同步执行这些操作。这里有一个限制:master上可能有许多不影响的操作,它会并行执行,但是slave在同步这些操作时,只会串行化的执行这些操作。
通过在master上执行命令可以查看当前master的dump线程:

当然,在slave上执行命令也可以查看自己的io线程和sql线程:
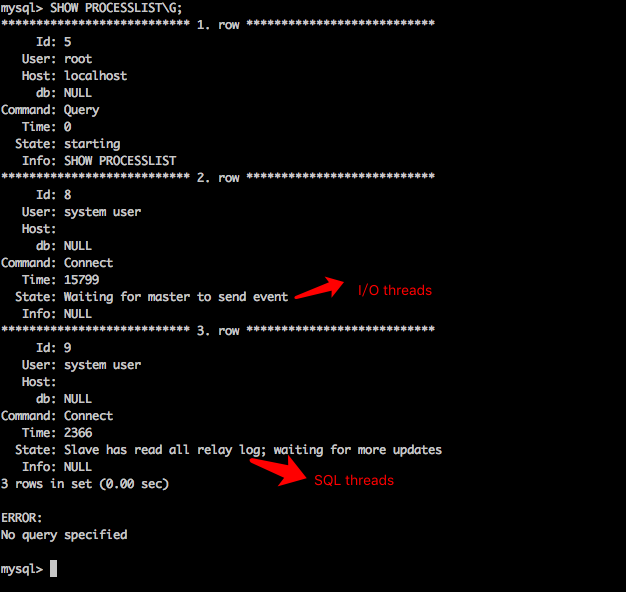
从sql线程中我们可以看到确实是从一个叫relay.log中获取同步操作的。
扩展slave节点
通常一个业务最开始都是从单机逐渐到集群的,所以mysql也是一样,我们很少有一开始就设置主从架构的应用,那么,如何在一个已有的服务器中添加从机器,或者从某一个已经有主从架构的服务商扩展一个新的slave呢?其实大致会有如下的几种方式:冷拷贝方式:即停止掉master节点,先进行数据复制,然后再启动,显然,这不是一个好的方案。
热拷贝方式:如果你是使用的myisam的存储引擎,那么你可以使用mysqlhotcopy程序来实现拷贝操作。
使用mysqldump方式:此时如果我们没有用myisam引擎,那么我们就可以通过dump来实现不停服务的情况下进行数据的拷贝,它的大致流程有如下三步:
1.锁表,我们知道,如果想保证数据一致,那么在进行复制时,锁表就是必须的一个步骤。
2.创建dump线程,执行数据同步操作。
3.释放表。
5.7新增的并行复制
从前面的步骤我们可以分析出一个结论,就是复制的过程必然会导致大量延迟(这也是确实存在的),所以mysql从5.6开始,就在全力解决这个棘手的问题,5.6之后,mysql提出了一个并行复制的概念,即可以同时进行数据的备份,用于减少延迟,大致上来说,5.6的mysql是基于schema的并行复制策略,所以这种场景下其实是有一个弊端的,我们知道,mysql中,每一个schema可以理解为一个库,所以基于schema就意味着可以实现多个库的并行复制,但是我们平常大多数时候,一个项目通常只会有一个库,所以单库下,我们并不能使用mysql的并行复制功能。
而mysql 5.7开始,从新引入一个叫gtids的概念,即全局事务id,所以说这一个版本开始,就是基于事务的复制了,这样就解决了单库的问题。














 101
101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









