





又是大模型相关啊~~ 因为也包括了图像才 搬的呀要不 就与我无关了~~
本文介绍了一个用于基于文本的行人检索的大规模多属性和语言检索数据集(Multi-Attribute and Language Search dataset), MALS,并探索了在属性识别和图像-文本匹配任务上同时进行预训练的可行性。
《Towards Unified Text-based Person Retrieval: A Large-scale Multi-Attribute and Language Search Benchmark》
论文地址:http://arxiv.org/abs/2306.02898
数据集下载地址:整理后公开
代码地址:https://github.com/Shuyu-XJTU/APTM (近期公开)
之前的工作有什么痛点?
作为一种跨模态学习任务,基于文本的行人检索很少从大规模的跨模态预训练中获益。原因:1)数据缺乏。由于隐私问题,通常无法收集足够的数据来满足当前深度学习大模型对数据的需求量。2)缺乏高质量的注释。语言注释过程很繁琐,并且不可避免地引入注释者的偏见。因此,文本描述通常非常简短,无法全面描述目标人物的特征。
这篇论文提出了什么?解决了什么问题?
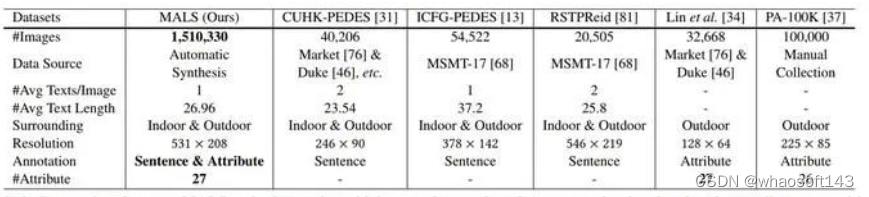
• 引入了一个新的大规模多属性和语言检索数据集,MALS。与现有数据集(如CUHK-PEDES)相比(如Table 1所示),MALS包含大约37.5倍的图像,并具有丰富的属性注释。
• 基于MALS,引入了一种新的联合多属性和文本匹配学习框架(APTM),以促进表示学习。顾名思义,APTM利用属性识别任务和基于文本的行人检索任务来规范模型训练。这两个任务互补并相互受益。
• APTM在包括CUHK-PEDES、ICFG-PEDES和RSTPReid在内的三个具有挑战性的真实基准数据集上实现了有竞争力的召回率。此外,我们还观察到文本匹配任务也有助于属性识别。在PA-100K(行人属性识别数据集)上对APTM进行微调,我们获得了82.58% 的竞争性性能(mA)。
数据集MALS构建:
我们借助现成的扩散模型和图像描述生成模型,构建了一个合成的图像-文本数据集。具体地:
(1)图像文本对生成:将CUHK-PEDES和ICFG-PEDES数据集的文本描述作为提示,利用扩散模型(ImaginAIry)生成行人图片,获得初始图像文本对。
(2)后处理:由于现有扩散模型缺乏细粒度和可控的生成能力,生成的部分图像不能满足行人检索网络的训练需求。我们删除灰度、模糊和嘈杂图像,利用OpenPose检测到的关键点作为紧凑的边界框来重新裁剪图像,从而获得最终的行人图像。
(3)图像描述校准:初始图像文本对中多个图像共享相同的文本描述,这导致了较差的文本多样性。因此,我们利用BLIP模型为每一张合成图像生成对应的文本描述,形成最终的图像文本对。Figure 1展示了合成数据集MALS和真实数据集CUHK-PEDES的一些图像文本对的例子。

(4)属性注释:通过对生成文本的分析(如Figure 2所示),我们预定义了和Market-1501属性数据集相同的属性空间。通过文本关键词匹配,自动为每一对图像文本对注释了27种不同类型的属性(由于文本可能没有包含所有的属性信息,图像文本对可能不具有完整的27个属性标签),如Table 2所示。
通过这种方式,我们收集了一个新的用于行人检索的大规模跨模态数据集,MALS。MALS 的优点有:高保真图像;多样性;更少的隐私问题;大规模图像文本对;丰富的注释等。

联合属性提示学习和文本匹配学习框架APTM:
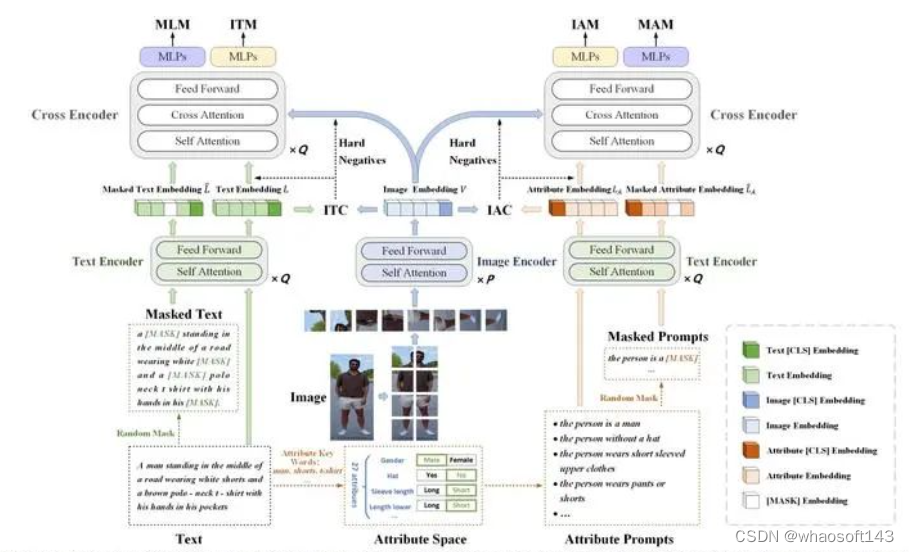
我们以MALS为预训练数据集,设计了一个新的简单的属性提示学习和文本匹配学习(Attribute Prompt Learning and Text Matching Learning, APTM)联合框架,如Figure3所示。整个过程通常分为两个步骤:预训练和微调。预训练时,进行属性提示学习(Attribute Prompt Learning , APL)和文本匹配学习(Text Matching Learning , TML),以学习基于文本的行人检索和行人属性识别的公共知识。微调时,针对特定的下游任务进一步优化参数。
APTM Architecture
如Figure3所示,APTM是一个多任务框架,包含一个图像-属性流和一个图像-文本流(权重共享)。APTM包括三个编码器(Image Encoder, Text Encoder, Cross Encoder), 以及两个基于MLP的头。
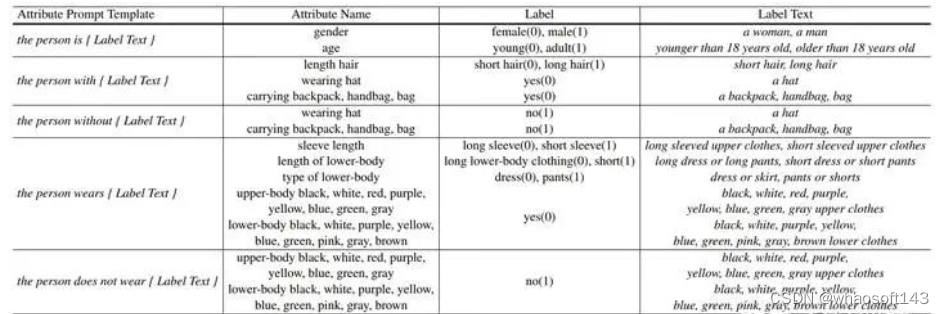
在预训练之前,我们将属性映射成属性提示 attribute prompts 作为图像-属性流的输入之一。如Table 9所示,属性提示由各个属性的属性提示模板和标签文本组成。为了方便,我们将MALS的属性注释视为27个二元属性,每个属性可以映射成两个相反的属性提示。例如,Figure3中的行人图片的性别属性是‘male’,则其属性提示模板是 ‘the person is {Label Text}’,Label Text 是 ‘a man’,完整的属性提示 --> ‘the person is a man’。‘the person is a man’的相反属性提示是 ‘the person is a woman’。在预训练期间,图像-文本流和图像-属性流被联合训练。我们通过 Random Mask 生成 masked text 和 masked prompts。Image Encoder, Text Encoder分别将图像和不同的文本编码成相应的特征表示。
Attribute Prompt Learning(APL)
受到跨模态学习的启发,我们利用图像-属性对比学习(Image-Attribute Contrastive Learning, IAC)、图像-属性匹配(Image-Attribute Matching, IAM)和掩码属性语言建模(Masked Attribute Language Modeling, MAM)对齐图像与其属性。



实验
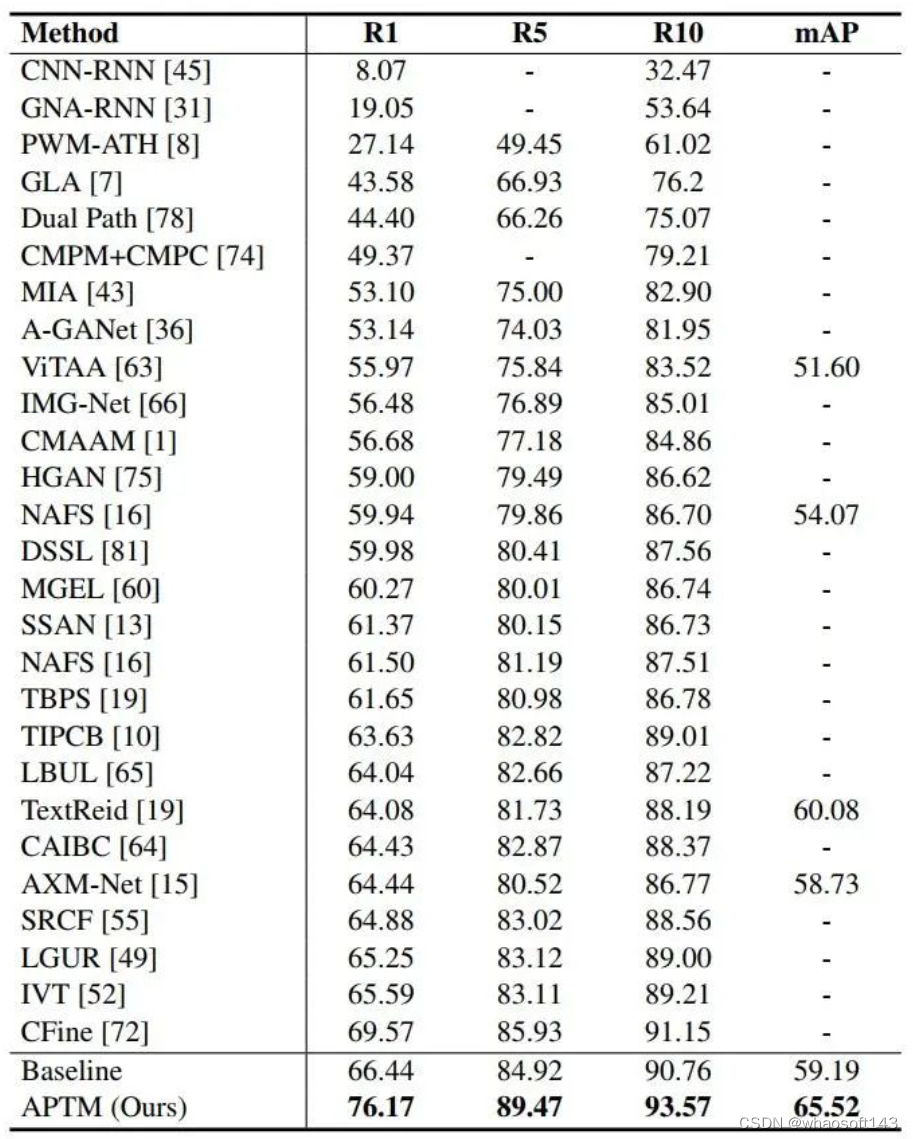
我们在CUHK-PEDES、RSTPReid和ICFG-PEDES数据集上评估了APTM(微调过程中优化ITC、ITM和MLM损失)。APTM在三个数据集上均达到了SOTA的R1,如Table 3、4、5所示。
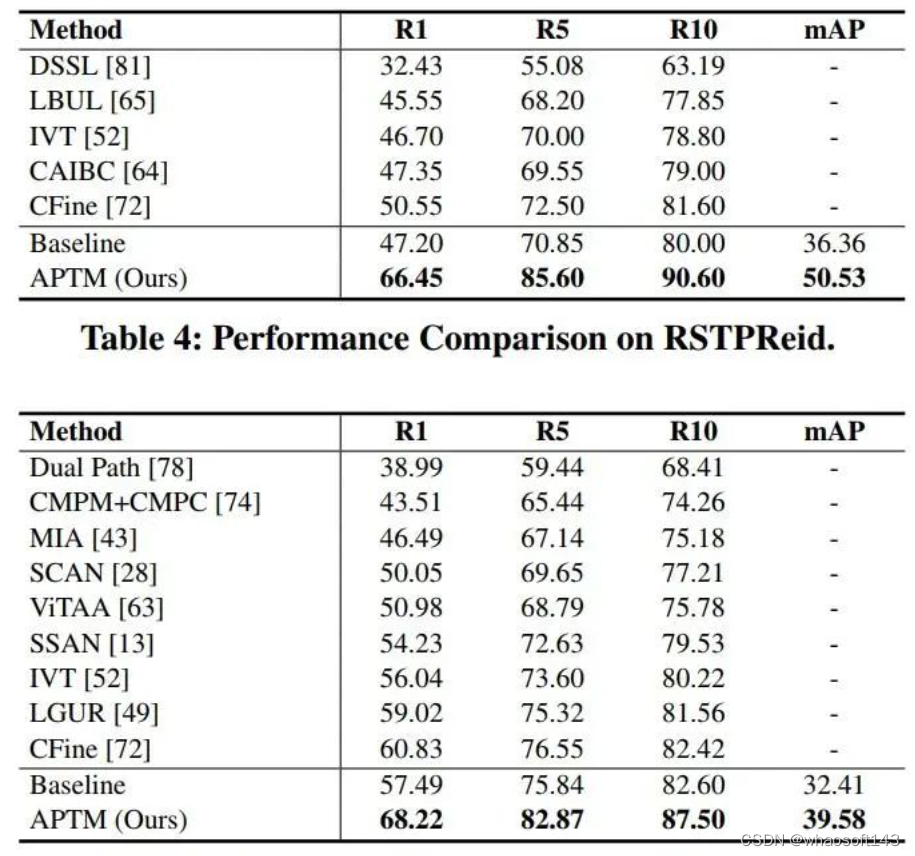
此外,我们将APTM的属性提示学习部分应用于PA-100K预测图像的属性。类似于MALS,我们为PA-100K构建属性提示并进行微调,获得了具有竞争力的结果(Table6)。
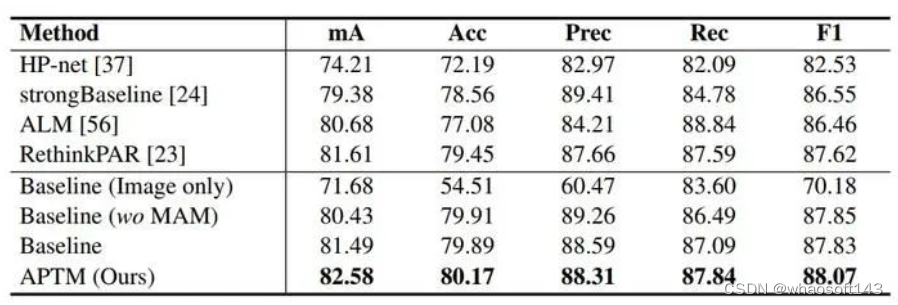
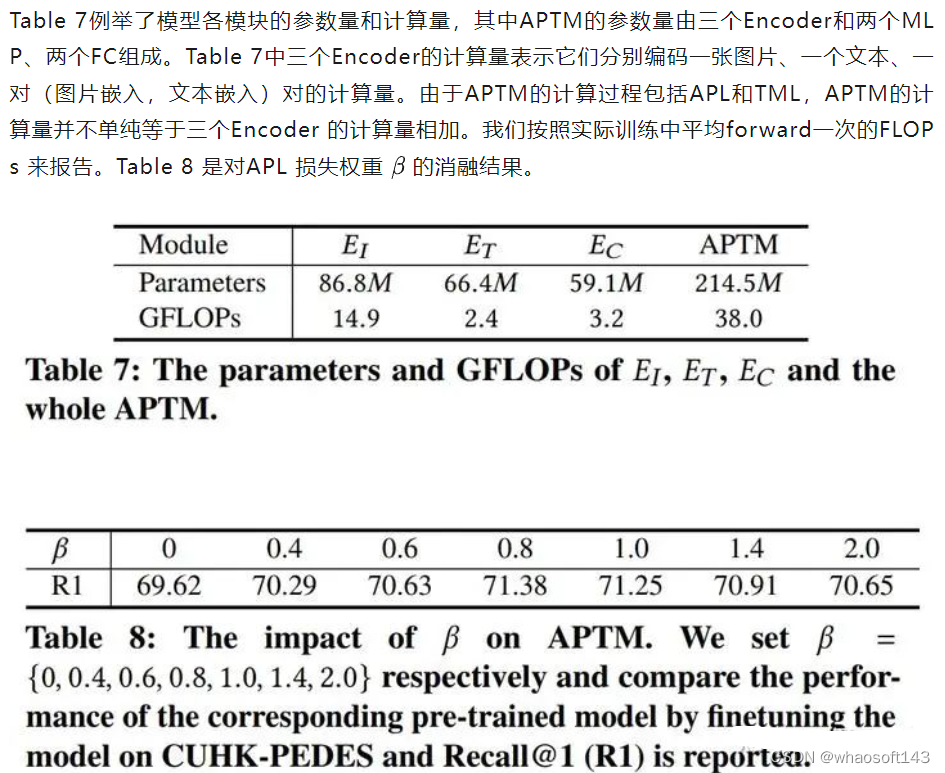
Figure 4 (a)探索了预训练数据集规模对基于文本的行人检索任务的性能影响,随着预训练数据集的规模增大,经过微调的模型性能持续提升。Figure 4(b)探索了APL和两种传统的基于分类器的属性识别方法的作用。

Figure 5 展示了一些检索结果的例子。

Figure 6 是对模型鲁棒性的一些探索结果。
















 957
957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









