






文章目录
题目:Towards Unified Text-based Person Retrieval: A Large-scale Multi-Attribute and Language Search Benchmark(面向统一的基于文本的人物检索:一个大规模的多属性和语言搜索基准)
期刊合集:最近五年,包含顶刊,顶会,学报>>网址
文章来源:
研究背景
本文,作者首先介绍一个用于基于文本的人物检索的大型多属性和语言搜索数据集,称为 MALS,它包含 1510330 个 图像—文本对,并且所有图像都用 27 个属性进行标注;并探讨在 属性识别和图像—文本匹配任务 上执行预训练的可行性。考虑到隐私问题和注释成本,作者利用现成的扩散模型来生成数据集。为验证从生成的数据中学习的可行性,开发一个新的属性提示学习和文本匹配学习(APTM)联合框架,考虑到属性和文本之间的共享知识。APTM 包含一个属性提示学习流和一个文本匹配学习流。(1) 属性提示学习利用属性提示进行图像属性对齐,增强了文本匹配学习。(2) 文本匹配学习促进细粒度细节的表示学习,进而促进属性提示学习。
给定行人描述,基于文本的行人检索旨在从大量候选人中定位目标。与传统的基于图像的行人检索相比,基于文本的人物检索提供了一种形成查询的直观方式。这些技术可以广泛应用于促进公共安全,例如在机场等大区域寻找走失儿童。然而,作为一种跨模态学习任务,基于文本的行人检索从大规模的跨模态预训练中获益甚微。原因有两个方面:1)缺乏数据。由于隐私问题,通常无法为当前急需数据的深度学习模型收集足够的数据。2) 缺乏高质量的注释。语言注释过程也很繁琐,不可避免地会引入注释者的偏见。因此,句子通常很短,无法全面描述目标人物的特征。
针对这些问题,作者建议借用现成扩散模型,构建一个合成的图像文本数据集模型和图像字幕模型。通过这种方式,可以自动生成无限制的图像并获得高质量的注释。此外,为了使合成数据有利于基于真实世界语言的人物检索,仍有两个挑战需要解决:(1) 合成图像文本对的现实主义。合成和真实世界的 图像—文本对 之间的视觉差异造成了 构建有意义的文本行人基准 的主要挑战。对于文本输入,利用从真实世界基于文本的行人数据中导出的描述来指导扩散模型,因此,生成的图像与现实世界中的图像非常相似。作者进一步应用后处理机制,以进一步细化合成图像并纠正任何剩余的差异。(2) 注释(句子和属性)的多样性。为了生成大规模的跨模态数据集,人工注释的描述不可避免地会被多次使用,导致文本多样性较差。为了处理这个限制,使用现成的字幕生成模型来增加每个合成图像的描述。此外,我们提出了一种自动属性提取机制,从描述中挖掘关键属性,以进一步丰富注释。通过这种方式,我们收集了一个新的大规模跨模态数据集,即具有丰富注释的多属性和语言检索数据集。
值得注意的是,虽然最近对扩散模型进行了数据扩充的研究,但这些工作主要集中在粗粒度类别识别的基准,如 ImageNet 和 EuroSAT。不同的是,由于个体之间的差异相对较小,因此行人检索需要更详细的表示。因此,MALS 数据集侧重于提供细粒度的细节,这对于基于文本的行人检索任务至关重要。此外,大量实验验证了从 MALS 中学到的知识在基于文本的人物检索和行人属性识别任务方面也可扩展到现实世界的应用。
为了验证收集的数据集的价值,作者引入 APTM 框架,包括三个模块,图像编码器、文本编码器和交叉编码器。通过所提出的显式匹配(EM)和隐式扩展(IE)机制,利用文本获取属性注释,并进一步将属性映射到一组属性提示。图像—文本对比学习(ITC)和图像属性对比学习(IAC)作用于特征编码器的嵌入,而 图像—文本匹配(ITM)、图像属性匹配(IAM)、掩蔽语言建模(MLM)和掩蔽属性提示建模(MAM)被施加于来自交叉编码器的各个预测。在预训练期间对上述约束进行联合优化,以学习有效的模型。
相关工作
Language-based Person Search. 文本到图像的行人检索由于其细粒度的特性,比一般的跨模态检索任务更具挑战性。根据对齐策略,现有的工作可以分为 基于跨模态注意力 或 无跨模态注意力 两种方法。为了在共享特征空间中对齐两种模态的表示,跨模态无注意力方法构建了各种模型结构或目标函数。相比之下,基于跨模态注意力的方法需要成对输入,并鼓励在区域和单词之间建立跨模态对应关系,或者在模态之间建立更多互动的区域和短语。值得注意的是,这两种策略都有其优点和缺点。一般来说,跨模态无注意力技术更有效,对于 M 图库大小和 N 查询数量,它的复杂性是 O(M + N)。相比之下,基于跨模态注意力方法由于成对输入,复杂性上升到 O (MN ) 。尽管如此,这些技术(跨模态注意力和跨模态无注意力技术)通常会显著提高检索性能。这是因为基于跨模态注意力的方法在早期阶段通过更多的跨模态交流更有效地减少了模态差距。在本文中,作者利用 跨模态无注意力 特征来快速找到候选人,然后部署 基于注意力 的模块来细化最终排名分数 (结合了两种方法的优点)。
Attribute-based Person Re-identification. 基于属性的行人重识别,旨在根据不同相机或时间段的人的属性(如衣服颜色、性别、身高等)来识别他们,而不是仅仅依靠视觉外观。林等人是最早研究行人属性的著作之一,他提出了一种使用颜色、纹理和轮廓线索进行人的重新识别的框架。特别地,Lin 等人从每个行人图像中提取判别特征,并训练多个属性分类器。在这项工作之后,Han等人进一步提出将部分特征与属性注意力相融合,而 He 等人则研究以连贯的方式联合训练多个属性分类器。与固定的水平分割相比,还研究了属性定位。为了鼓励属性之间的交互,Nguyen 等人和 Tang 等人都提出为每个人构建属性的图表示,其中节点表示属性嵌入,边表示它们之间的相关性。除了传统属性外,王等人还利用外表和人格特征来学习视觉外表和人格特质的表征,并将它们结合起来进行重新识别。最后,有几项工作可以使属性对遮挡或姿势变化更加鲁棒。例如,Jing 等人提出了一种多模态框架,该框架将基于属性的特征与基于姿态的特征相融合,以在具有挑战性的条件下提高重新识别的准确性。在本文中,利用稳健的属性学习来促进基于文本的人物检索,属性学习是对图像文本匹配的补充,反之亦然。
BENCHMARK
现有基于文本的行人检索数据集通常从现有的行人重识别数据集中收集行人图像,并手动注释相应的文本描述。然而,由于注释成本和隐私问题,这种做法极大地限制了规模和多样性,如表 1 所示。最近扩散模型的巨大成功激励要从合成领域收集行人图像。主要有两个优势:(1) 与 3D 游戏引擎或生成对抗性网络(GANs)相比,扩散模型显示出强大而稳定的能力,可以将具有高真实性的图像合成为文本,显著缩小了合成数据和真实数据之间的差距。[diffusion > Gans和3D引擎] (2) 使用合成行人图像也可以避免隐私问题。

BENCHMARK 的构建包括以下步骤:
Image-text Pair Generation. (图像—文本对生成)
作者利用现成的扩散模型 ImaginAIry,它可以生成新的行人图像。使生成的样本合理且接近对于真实世界的行人图像,使用 CUHK-PEDES 数据集和 ICFG-PEDES 数据集的文本描述作为提示。将提示输入ImaginAIry,并收集相应的合成图像,生成一对对齐的样本。为了确保生成具有可控可变性的高质量全身行人图像,将图像大小设置为 576×384,并调整随机种子以获得高质量样本。通过在推理过程中对噪声进行随机化,可以收集到大量多样的行人图像。
Post-Processing. (后处理) 由于文本到图像生成模型缺乏细粒度和可控的生成能力,许多生成的图像无法满足训练行人检索网络的要求。主要存在两个问题:(1) 低质量图像,包括灰度图像和模糊图像。为了克服这个弱点,只需按文件大小对图像进行排序,并删除大小小于 24k 的图像以过滤掉模糊的图像。然后,再计算每个图像的 3 个通道之间的差的平均方差,并去除平均方差小于预设阈值的图像。(2) 噪声图像,例如,一个图像中有多个人,只有一个人的一部分,或者没有人。为了解决这个问题,应用 OpenPose 来检测人体关键点并过滤掉不想要的人体图像,还利用检测到的关键点作为一个紧密的边界框来重新裁剪样本。通过以上步骤,可以获得最终的行人图像。
Caption Calibration. (字幕校准) 用于生成图像的提示是用作文本描述的直接选择。然而,这种方式会导致文本描述的多样性较差,因为多个图像通常共享同一文本。为了解决这个问题,利用跨模态模型 BLIP 为每个合成图像生成更合适的字幕,并形成最终的 图像—文本对。
Attribute Annotation. (属性注释) 相关的属性通常突出了图像和文本样本的关键特征,许多基于文本的行人检索工作表明了属性提高性能的潜力。受此启发,通过属性注释进一步增强 MALS,从而可以构建一个信息量更大、更全面的基准。考虑到手动注释的成本,作者以自动的方式获得属性注释。首先以与 Market-1501 属性相同的方式定义属性空间,然后提出两种获取属性的机制,显式匹配(EM)和隐式扩展(IE)。EM 根据文本中的关键词部署特定属性的对应关系,例如与属性 “性别:男性” 对应的单词 “男性”。IE 根据文本中未提及的显著特征分配相应的属性候选者,例如将描述中未提及 “hat” 的样本分配给属性 “hat:no”。最后,收集了 27 种不同类型的属性,如表 2 所示。

MALS Benchmark. (MALS 基准) 按照上述步骤,为基于文本的人物检索任务建立了一个高保真、多样化和大规模的基准。如图 1 所示,可以观察到视觉图像和文本句子的质量与 CUHKPEDES 相当。图 2 还直观地显示了使用单词云对 MALS 和 CUHK-PEDES 的单词分布的比较。可以观察到,尽管两个数据集之间仍然存在一些差异,但 MALS 的文本语料库与真实世界的数据非常接近。


与表 1 中现有的基于文本的人物检索数据集相比,MALS 具有以下优势:
-
High-fidelity Images: 与从监控摄像头收集的光线较差、纹理模糊的图像相比,MALS 的图像质量更高,这得益于扩散模型的能力(见图 1),这意味着合成图像在视觉上更具吸引力和逼真度。
-
Diversity: MALS 包含图像中的广泛变化,包括但不限于背景、视点、遮挡、服装和身体姿势的变化。多亏了字幕校准步骤,相关的文本描述也足够多样化。因此,MALS 可以支持我们训练出在视觉任务、语言任务和视觉—语言任务中对新数据和未见数据都具有良好泛化性能的强大模型。
-
Fewer Privacy Concerns: 与基于文本的行人检索在未经同意的情况下捕获图像的几个传统基准不同,MALS 的样本都是由非自稳定扩散模型生成的合成图像,这避免了伦理和法律问题。
-
Large-scale Pairs: MALS 包含1.5M 图像—文本对(见表1),而现有的数据集通常提供不超过 100k 个对齐的图像文本。数据集的这种规模使得能够进行全面的训练前研究。
-
Rich Annotations: MALS 中的每个 图像—文本 对都带有适当的属性标签,表明 MALS 不仅对文本图像匹配和属性提示学习有效,而且探索了预训练对 属性识别 和 图像—文本匹配 的可行性。
论文方法分析
本文贡献如下:
- 数据稀缺在很大程度上损害了基于文本的行人检索,本文提出了一种新的大规模多属性和语言搜索基准数据集,称为 MALS。
- 基于 MALS 数据集,引入了新的属性提示学习和文本匹配学习(APTM)联合框架,以促进表示学习,利用属性识别任务和基于文本的行人检索任务来规范模型训练。
网络框架
使用 Pytorch 在 4 个 NVIDIA A100 GPU上预训练 APTM 32个 epoch,mini-batch size 为 150。
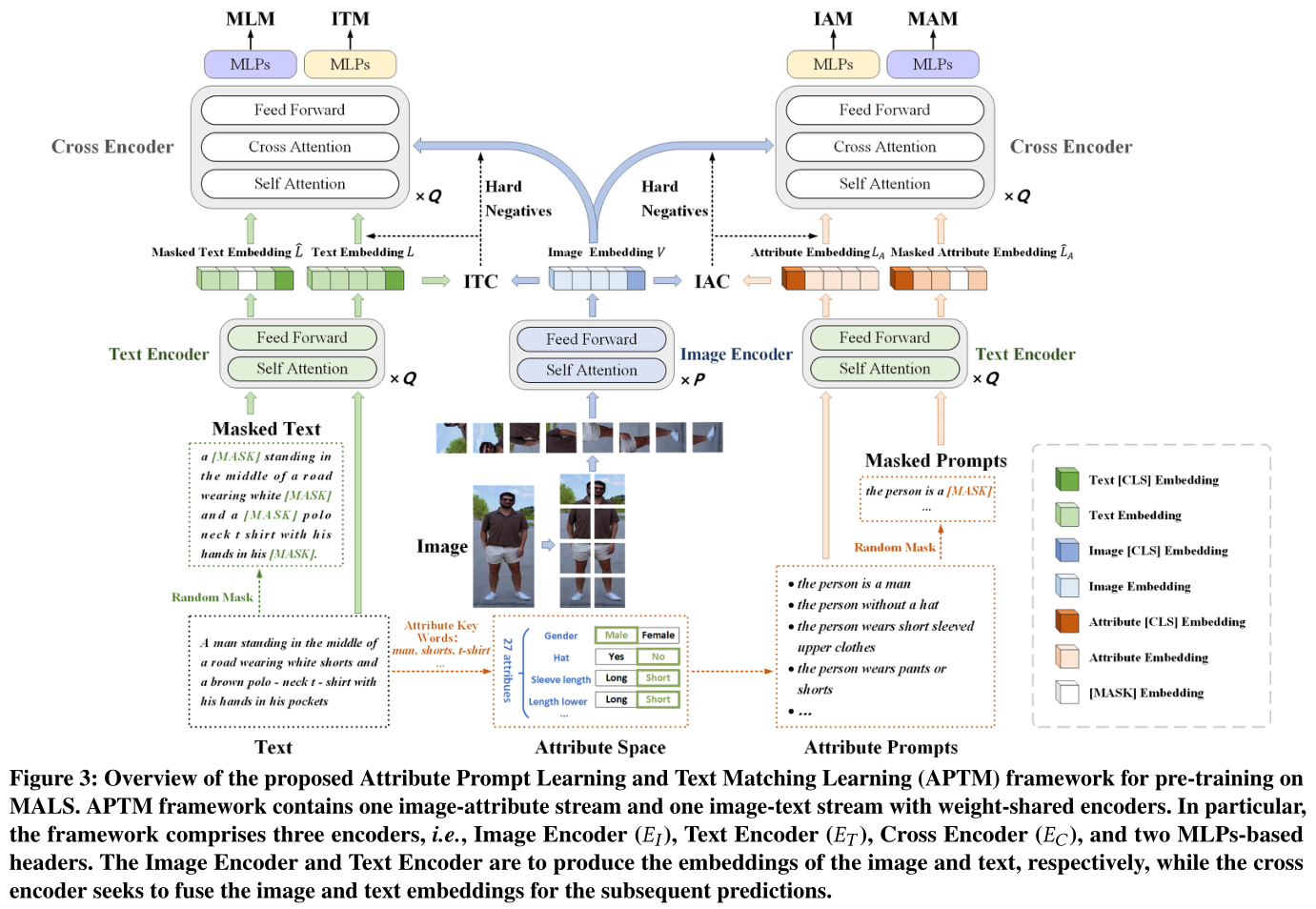
作者利用 MALS 作为预训练数据集,并设计了属性提示学习和文本匹配学习(APTM)联合框架,如图 3 所示。整个流程通常分为两个步骤,即预训练和微调。在预训练过程中,进行了属性提示学习(APL)和文本匹配学习(TML),以学习基于文本的行人检索和行人属性识别的公共知识。在第二步骤中,针对特定的下游任务进一步优化参数。 主要还是对预训练作说明,微调细节讲得很少。
1、APTM Architecture
如图 3 所示,APTM 是一个多任务框架,包含一个 图像属性流 和一个具有权重共享编码器和基于 MLP 的头部的 图像文本流。特别地,该框架包括三个编码器,即图像编码器(E I ),文本编码器(E T ),交叉编码器(E C ), 以及两个基于 MLP 的报头。在预训练之前,利用文本通过 显式匹配和隐式扩展机制 获取属性注释,然后将属性映射到一组属性提示(Attribute Prompts)作为图像属性流的输入之一。在预训练期间,图像文本流和图像属性流 被联合训练。部署随机掩码(Random Mask)来生成掩码文本和掩码属性提示,然后图像编码器将图像映射到嵌入向量 V,文本编码器通过分别对文本、掩码文本、属性提示和掩码属性提示进行编码,提取不同的文本表示,分别表示为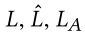
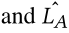 ,在 ITC 和 ITM 任务中,图像嵌入 V 与 L 配对,而在 IAC 和 IAM 上下文中,图像嵌入 V 与 L A 配对。此外,在 MLM 或 MAM 任务中,图像嵌入 V 还被输入到交叉编码器中,与
,在 ITC 和 ITM 任务中,图像嵌入 V 与 L 配对,而在 IAC 和 IAM 上下文中,图像嵌入 V 与 L A 配对。此外,在 MLM 或 MAM 任务中,图像嵌入 V 还被输入到交叉编码器中,与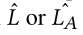 配对。
配对。
Image Encoder. 在不失一般性的情况下,部署 Swin Transformer(Swin-B)作为图像编码器(E I ),
2、Attribute Prompt Learning (属性提示学习)
Motivations. 属性通常强调行人图像的关键特征,如 性别和头发,这对于执行跨模态对齐和区分候选者至关重要。此外,如图 2 所示,合成描述和真实描述在属性关键字方面表现出相当大的重叠,这让我们相信强调相似的属性空间也可以缓解领域差距。为了更好地利用属性信息进行图像属性对齐,选择不依赖于传统的基于分类器的多属性学习方法。相反,使用提示模板将属性标签转换为属性提示,然后,将属性提示与相应的图像对齐,这构成了属性提示学习的基本基础。从跨模态学习中汲取灵感,我们利用图像属性对比学习(IAC)、图像属性匹配(IAM)和掩蔽属性语言建模(MAM)来有效地将图像与其属性对齐。
图像属性对比学习(IAC)专注于掌握区分正负对的能力。在小批量中给定一组属性文本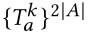 ,
,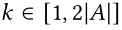 ,其中 A 是由 27 个二进制属性组成的属性集。对于图像 I, 如果它的任何属性标签与属性集相对应,我们将考虑相应的属性文本和 I 作为匹配的(图像、属性提示)对。
,其中 A 是由 27 个二进制属性组成的属性集。对于图像 I, 如果它的任何属性标签与属性集相对应,我们将考虑相应的属性文本和 I 作为匹配的(图像、属性提示)对。
如图 3 所示,“人是男人” 是图像的匹配属性提示,而 “人是女人” 则不是。我们将小批量中所有匹配(图像、属性提示)对的集合表示为
B a。图像 I 之间的匹配分数及其配对属性提示 T a 估计如下:

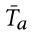 是
是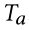 的相反属性,它是通过将 true 属性替换为 false 属性而构建的,例如,男人的相反属性就是女人。
的相反属性,它是通过将 true 属性替换为 false 属性而构建的,例如,男人的相反属性就是女人。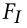 和
和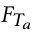 是经过两个不同 FC 各自 [CLS] 嵌入的映射特征,s(·, ·) 是余弦相似度。IAC 损失的公式如下:
是经过两个不同 FC 各自 [CLS] 嵌入的映射特征,s(·, ·) 是余弦相似度。IAC 损失的公式如下:

图像属性匹配学习(IAM) 旨在预测输入图像与属性提示是否匹配。特别是,IAM 被指定为一个二进制分类问题,以便于图像属性对齐:正样本是成对的图像属性提示,而不成对的则是负样本。在数学上,假设 |B| 以小批量对图像进行采样,随机构建 5 个属性提示,形成 5个 |B| (图像、属性提示) 对,表示为 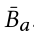 ,随后,图像属性提示元组通过 Cross Encoder 来获得 [CLS] 嵌入
,随后,图像属性提示元组通过 Cross Encoder 来获得 [CLS] 嵌入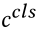 ,它们的匹配分数由具有 Sigmoid 激活的 MLP 给出:
,它们的匹配分数由具有 Sigmoid 激活的 MLP 给出: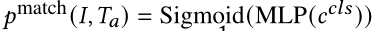 ,IAM 损失定义为:
,IAM 损失定义为:

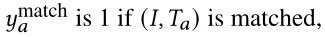 ,否则为 0。
,否则为 0。
掩蔽属性语言建模(MAM) 试图使用匹配的(图像,属性提示)作为线索来预测掩蔽词。为此,首先采用以下策略来随机屏蔽 2|A| 属性提示:1)在被屏蔽的标记中,将文本标记的概率屏蔽为 25%;2)10% 和 80%分别替换为随机令牌和特殊令牌 [MASK];3) 10% 保持不变。然后,在 B a 给定一个图像属性提示对 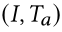 ,我们得到了相应的掩码属性提示
,我们得到了相应的掩码属性提示 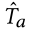 遵循上述策略。
遵循上述策略。

为什么 APL 效果更好。 与基于分类的多属性学习(CMAL)方法相比,APL 具有三个明显的优势:1) 明确强调属性。朴素的基于分类的做法通过分类过程隐含地突显关键属性,而 APL 明确构建属性提示,从而比隐式分类过程更有效地学习。2) 提供更丰富的输入信息。APL 通过构建附加的属性提示引入信息丰富的输入,为跨模态对齐学习提供更丰富的信息。相比之下,传统的 CMAL 只使用分类损失,不引入辅助信息。3) 框架增强的更大灵活性。由于构建的属性提示,APL 使得强大的跨模态学习目标(如图像文本对比学习(ITC)、图像文本匹配(ITM)和屏蔽语言建模(MLM))可以在修改后变得面向属性,从而增加了性能提升的潜力。在实验中,APL 优于若干朴素的 CMAL 变体,充分证实了 APL 的优越性。
3、Text matching Learning(文本匹配学习)
作为一种跨模态检索问题,基于文本的行人检索的核心是对齐文本查询和候选图像。因此,还结合了 图像—文本 对比学习(ITC)、图像—文本匹配学习(ITM)和掩蔽语言建模(MLM)的任务来施加对齐约束。
图像—文本对比学习(ITC) 侧重于学习区分积极和消极配对。将配对的图像文本(I,T)视为正样本,而不匹配的图像文本是负样本。形式上,我们随机抽样 |B| 每个小批量中的成对图像和文本。类似于等式 1,给定一对匹配的(I,T)。我们首先提取它们各自的表示 F I 和 F T 。匹配分数估计如下:

类似地,给定文本,配对图像的匹配分数 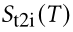 可以进行计算。最后,ITC 损失公式为:
可以进行计算。最后,ITC 损失公式为:

图像-文本匹配学习(ITM) 的目标是预测输入图像和文本是否匹配,类似于 IAM。然而,对不成对的项目(文本或图像)进行随机采样对于分类来说过于容易。因此,我们采用了一种硬挖掘策略。对于小批量中的每个文本,我们根据 ,即选取相似度最高的未配对图像作为硬负片。我们还以类似的方式为每个图像随机选择一个硬负面文本。最后 |B| 正图像文本对和 2|B| 负对,表示为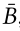 ,将通过交叉编码器和一个具有 Sigmoid 激活的 MLP。在这些步骤之后,ITM 损失可以类似地计算,如 等式3 所述。
,将通过交叉编码器和一个具有 Sigmoid 激活的 MLP。在这些步骤之后,ITM 损失可以类似地计算,如 等式3 所述。
掩蔽语言建模(MLM) 试图利用图像和文本线索来预测掩蔽词。给定一对在 B 里面的图像文本对(I,T),我们得到相应的屏蔽文本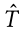 ,遵循与 MAM 相同的掩蔽策略。随后
,遵循与 MAM 相同的掩蔽策略。随后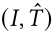 通过编码器以获得嵌入。
通过编码器以获得嵌入。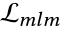 可通过等式 4 类似得到。
可通过等式 4 类似得到。
给定上述优化目标,训练前的全部损失公式为: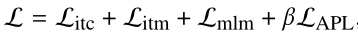 ,β 表示 APL 损失权重,设置 0.8。
,β 表示 APL 损失权重,设置 0.8。
我们使用Pytorch在 4 个 NVIDIA A100 GPU上预训练 APTM 32个时期,小批量大小为150。
实验结果

















 465
465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











