






交换排序
(1)冒泡排序
1.基本思想
从后往前(或从前往后)两两比较相邻元素的值,若为逆序(即A[i-1]>A[i]),则交换它们,直到序列比较完。
2.算法流程图
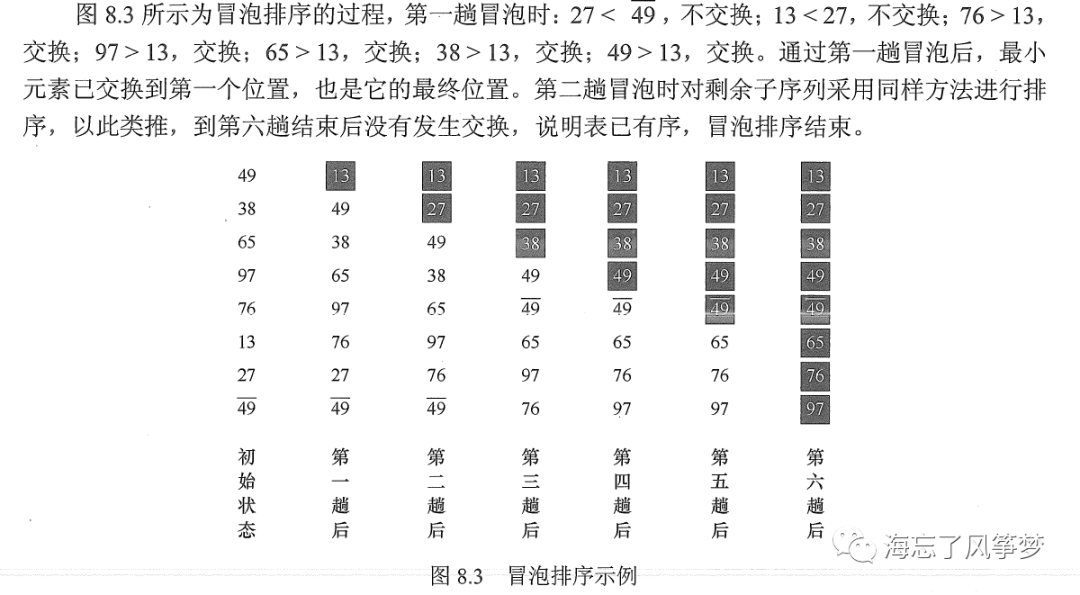
3.C语言代码
void BubbleSort(int A[],int n){ int temp=0; for(int i=0;i int flag=false; for(int j=n-1;j>i;j--){ if(A[j-1]>A[j]){ temp=A[j-1]; A[j-1]=A[j]; A[j]=temp; flag=true; } } if(flag==false) return; }}int main(){ int A[10] = {0,9,8,7,6,5,4,3,2,1}; BubbleSort(A,10); for(int i=0;i<10;i++){ printf("%d ",A[i]); } return 0;}
4.性能分析

(2)快速排序
1.基本思想
快速排序是C.R.A.Hoare于1962年提出的一种划分交换排序。它采用了一种分治的策略,通常称其为分治法(Divide-and-ConquerMethod)。
该方法的基本思想是:
1.先从数列中取出一个数作为基准数。
2.分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边。
3.再对左右区间重复第二步,直到各区间只有一个数。
虽然快速排序称为分治法,但分治法这三个字显然无法很好的概括快速排序的全部步骤。因此对快速排序作进一步的说明:挖坑填数+分治法
2.算法流程图
以一个数组作为示例,取区间第一个数为基准数。
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
72 | 6 | 57 | 88 | 60 | 42 | 83 | 73 | 48 | 85 |
初始时,i = 0; j = 9; X = a[i] = 72
由于已经将 a[0] 中的数保存到 X 中,可以理解成在数组 a[0] 上挖了个坑,可以将其它数据填充到这来。
从j开始向前找一个比X小或等于X的数。当j=8,符合条件,将a[8]挖出再填到上一个坑a[0]中。a[0]=a[8]; i++; 这样一个坑a[0]就被搞定了,但又形成了一个新坑a[8],这怎么办了?简单,再找数字来填a[8]这个坑。这次从i开始向后找一个大于X的数,当i=3,符合条件,将a[3]挖出再填到上一个坑中a[8]=a[3]; j--;
数组变为:
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
48 | 6 | 57 | 88 | 60 | 42 | 83 | 73 | 88 | 85 |
i = 3; j = 7; X=72
再重复上面的步骤,先从后向前找,再从前向后找。
从j开始向前找,当j=5,符合条件,将a[5]挖出填到上一个坑中,a[3] = a[5]; i++;
从i开始向后找,当i=5时,由于i==j退出。
此时,i = j = 5,而a[5]刚好又是上次挖的坑,因此将X填入a[5]。
数组变为:
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
48 | 6 | 57 | 42 | 60 | 72 | 83 | 73 | 88 | 85 |
可以看出a[5]前面的数字都小于它,a[5]后面的数字都大于它。因此再对a[0…4]和a[6…9]这二个子区间重复上述步骤就可以了。
对挖坑填数进行总结:
1.i =L; j = R; 将基准数挖出形成第一个坑a[i]。
2.j--由后向前找比它小的数,找到后挖出此数填前一个坑a[i]中。
3.i++由前向后找比它大的数,找到后也挖出此数填到前一个坑a[j]中。
4.再重复执行2,3二步,直到i==j,将基准数填入a[i]中。
3.C语言代码
void quick_sort(int s[], int l, int r){ if (l < r) { //Swap(s[l], s[(l + r) / 2]); //将中间的这个数和第一个数交换 参见注1 int i = l, j = r, x = s[l]; while (i < j) { while(i < j && s[j] >= x) // 从右向左找第一个小于x的数 j--; if(i < j) s[i++] = s[j]; while(i < j && s[i] < x) // 从左向右找第一个大于等于x的数 i++; if(i < j) s[j--] = s[i]; } s[i] = x; quick_sort(s, l, i - 1); // 递归调用 quick_sort(s, i + 1, r); }}int main(){ int A[10] = {0,9,8,7,6,5,4,3,2,1}; quick_sort(A, 0, 9); for(int i=0;i<10;i++){ printf("%d ",A[i]); } return 0;}4.算法性能分析

选择排序
(1)简单选择排序
算法思想
简单选择排序是一种选择排序。
选择排序:每趟从待排序的记录中选出关键字最小的记录,顺序放在已排序的记录序列末尾,直到全部排序结束为止。
2.算法流程
(1)从待排序序列中,找到关键字最小的元素;
(2)如果最小元素不是待排序序列的第一个元素,将其和第一个元素互换;
(3)从余下的 N - 1 个元素中,找出关键字最小的元素,重复(1)、(2)步,直到排序结束。
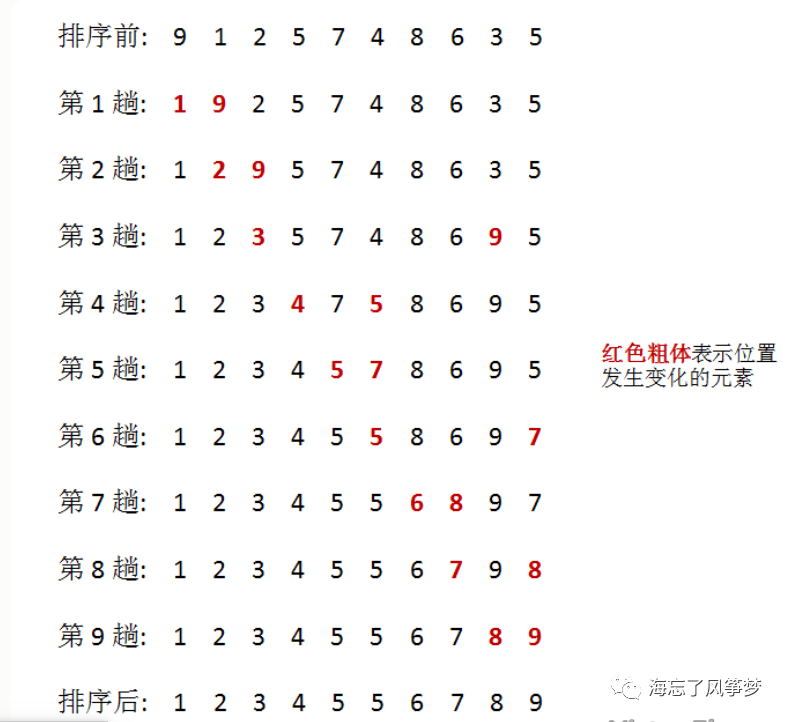
如图所示,每趟排序中,将当前第 i 小的元素放在位置 i 上。
3.C语言代码
void SelectSort(int A[],int n){ int i,j; for(i=0;i int min=i; for(j=i+1;j if(A[j] min=j; } if(min!=i){ int temp=A[min]; A[min] = A[i]; A[i]=temp; } }}int main(){ int A[10] = {0,9,8,7,6,5,4,3,2,1}; SelectSort(A, 10); for(int i=0;i<10;i++){ printf("%d ",A[i]); } return 0;}4.性能分析

(2)堆排序
算法思想
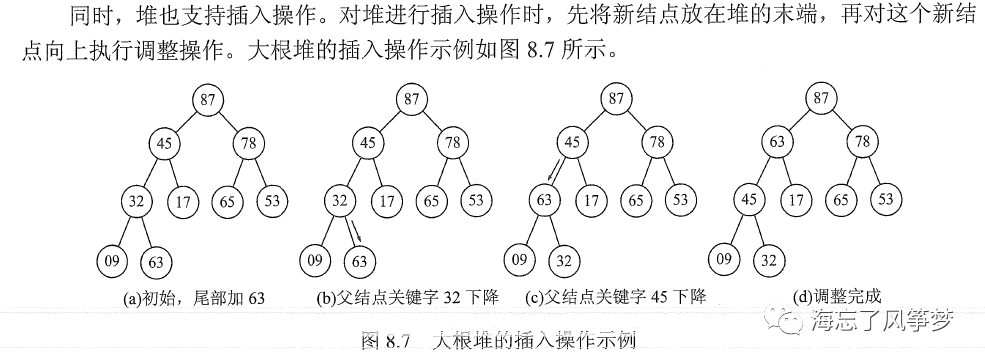
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。堆排序可以说是一种利用堆的概念来排序的选择排序。分为两种方法:
大顶堆:每个节点的值都大于或等于其子节点的值,在堆排序算法中用于升序排列;
小顶堆:每个节点的值都小于或等于其子节点的值,在堆排序算法中用于降序排列;
堆排序的平均时间复杂度为 Ο(nlogn)

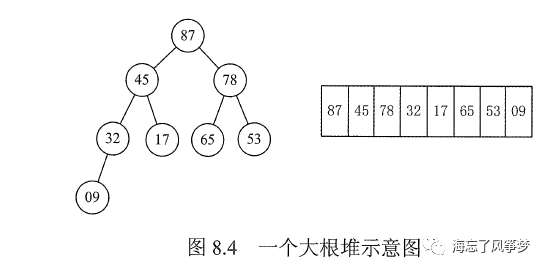
2.程序流程图

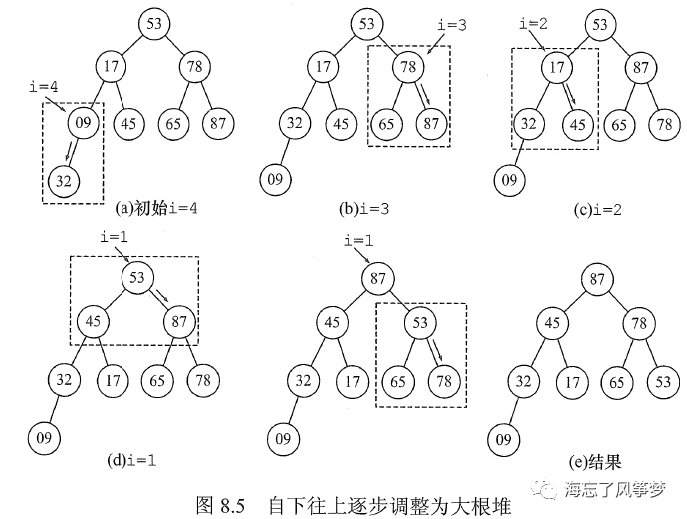
87输出后,把堆最后一个元素与堆顶元素交换,此时堆的结构被破坏,需要调整使之符合堆的性质
3.C语言程序
#include #include void swap(int *a, int *b) { int temp = *b; *b = *a; *a = temp;}void max_heapify(int arr[], int start, int end) { // 建立父節點指標和子節點指標 int dad = start; int son = dad * 2 + 1; while (son <= end) { // 若子節點指標在範圍內才做比較 if (son + 1 <= end && arr[son] < arr[son + 1]) // 先比較兩個子節點大小,選擇最大的 son++; if (arr[dad] > arr[son]) //如果父節點大於子節點代表調整完畢,直接跳出函數 return; else { // 否則交換父子內容再繼續子節點和孫節點比較 swap(&arr[dad], &arr[son]); dad = son; son = dad * 2 + 1; } }}void heap_sort(int arr[], int len) { int i; // 初始化,i從最後一個父節點開始調整 for (i = len / 2 - 1; i >= 0; i--) max_heapify(arr, i, len - 1); // 先將第一個元素和已排好元素前一位做交換,再重新調整,直到排序完畢 for (i = len - 1; i > 0; i--) { swap(&arr[0], &arr[i]); max_heapify(arr, 0, i - 1); }}int main() { int arr[] = { 3, 5, 3, 0, 8, 6, 1, 5, 8, 6, 2, 4, 9, 4, 7, 0, 1, 8, 9, 7, 3, 1, 2, 5, 9, 7, 4, 0, 2, 6 }; int len = (int) sizeof(arr) / sizeof(*arr); heap_sort(arr, len); int i; for (i = 0; i < len; i++) printf("%d ", arr[i]); printf("\n"); return 0;}4.性能分析

归并排序

接下来就以对序列A[0], A[l]…, A[n-1]进行升序排列来进行讲解,在此采用自顶向下的实现方法,操作步骤如下。(1)将所要进行的排序序列分为左右两个部分,如果要进行排序的序列的起始元素下标为first,最后一个元素的下标为last,那么左右两部分之间的临界点下标mid=(first+last)/2,这两部分分别是A[first … mid]和A[mid+1 … last]。(2)将上面所分得的两部分序列继续按照步骤(1)继续进行划分,直到划分的区间长度为1。(3)将划分结束后的序列进行归并排序,排序方法为对所分的n个子序列进行两两合并,得到n/2或n/2+l个含有两个元素的子序列,再对得到的子序列进行合并,直至得到一个长度为n的有序序列为止。下面通过一段代码来看如何实现归并排序。
c语言算法如下:
#include #include #define N 7void merge(int arr[], int low, int mid, int high){ int i, k; int *tmp = (int *)malloc((high-low+1)*sizeof(int)); //申请空间,使其大小为两个 int left_low = low; int left_high = mid; int right_low = mid + 1; int right_high = high; for(k=0; left_low<=left_high && right_low<=right_high; k++){ // 比较两个指针所指向的元素 if(arr[left_low]<=arr[right_low]){ tmp[k] = arr[left_low++]; }else{ tmp[k] = arr[right_low++]; } } if(left_low <= left_high){ //若第一个序列有剩余,直接复制出来粘到合并序列尾 //memcpy(tmp+k, arr+left_low, (left_high-left_low+l)*sizeof(int)); for(i=left_low;i<=left_high;i++) tmp[k++] = arr[i]; } if(right_low <= right_high){ //若第二个序列有剩余,直接复制出来粘到合并序列尾 //memcpy(tmp+k, arr+right_low, (right_high-right_low+1)*sizeof(int)); for(i=right_low; i<=right_high; i++) tmp[k++] = arr[i]; } for(i=0; i arr[low+i] = tmp[i]; free(tmp); return;}void merge_sort(int arr[], unsigned int first, unsigned int last){ int mid = 0; if(first mid = (first+last)/2; /* 注意防止溢出 */ /*mid = first/2 + last/2;*/ //mid = (first & last) + ((first ^ last) >> 1); merge_sort(arr, first, mid); merge_sort(arr, mid+1,last); merge(arr,first,mid,last); } return;}int main(){ int i; int a[N]={32,12,56,78,76,45,36}; printf ("排序前 \n"); for(i=0;i printf("%d\t",a[i]); merge_sort(a,0,N-1); // 排序 printf ("\n 排序后 \n"); for(i=0;i printf("%d\t",a[i]); printf("\n"); system("pause"); return 0;}性能分析:

基数排序介绍
基数排序(Radix Sort)是桶排序的扩展,它的基本思想是:将整数按位数切割成不同的数字,然后按每个位数分别比较。具体做法是:将所有待比较数值统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
基数排序图文说明
基数排序图文说明
通过基数排序对数组{53, 3, 542, 748, 14, 214, 154, 63, 616},它的示意图如下:
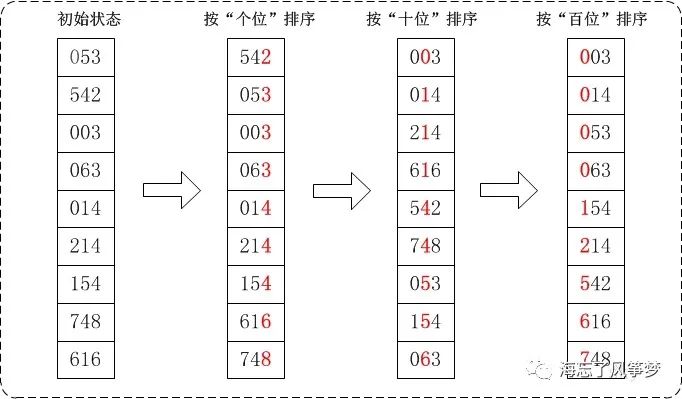
在上图中,首先将所有待比较树脂统一为统一位数长度,接着从最低位开始,依次进行排序。1. 按照个位数进行排序。2. 按照十位数进行排序。3. 按照百位数进行排序。排序后,数列就变成了一个有序序列。

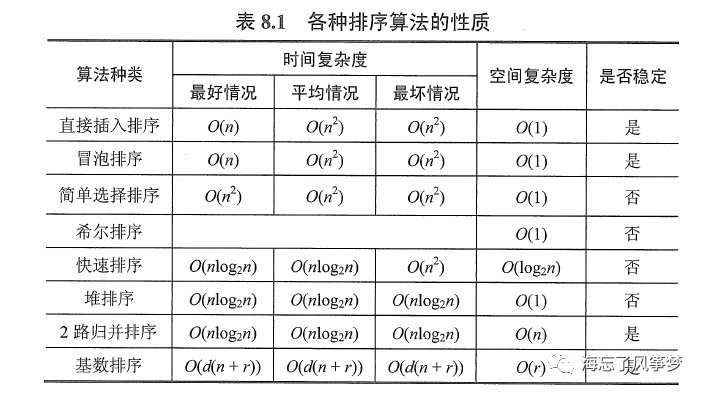
各种排序算法的比较




以上内容部分来源于:
菜鸟教程
王道数据结构
https://www.cnblogs.com/jingmoxukong/p/4303289.html
作者:静默虚空
https://www.cnblogs.com/skywang12345/p/3603669.html
作者:如果天空不死














 820
820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









