






为什么要优化?
系统的吞吐量瓶颈往往出现在数据库的访问速度上
随着应用程序的运行,数据库的中的数据会越来越多,处理时间会相应变慢
数据是存放在磁盘上的,读写速度无法和内存相比
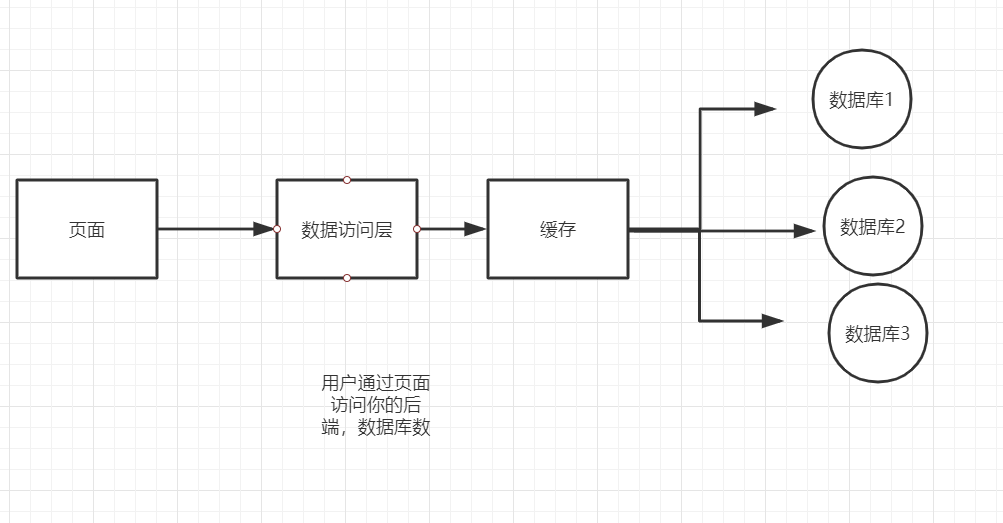
Memcached/Redis(缓存)+Mysql+垂直拆分
这种做法可以将你的数据库的数据从开始的一个数据库分成了3个,比如第一个数据库复制保存用户信息,第二个保存商品信息,第三个保存
缺点:
当你的 数据库1 炸了,整合项目就运行不起来了(不安全)
Mysql主从复制+读写分离
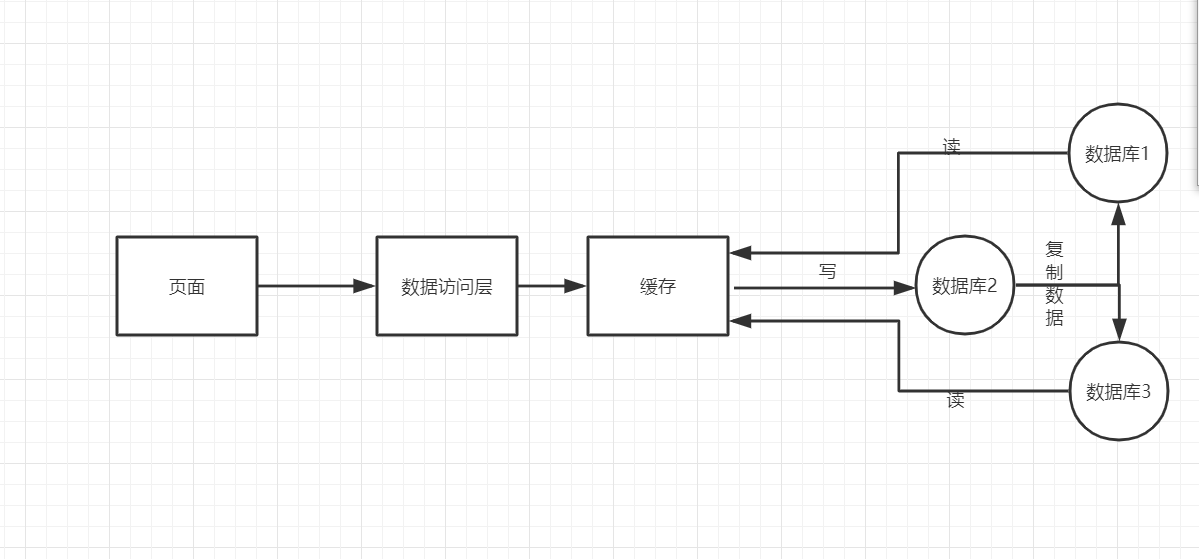
1、什么是主从复制
多搞几个数据库来存储数据,假设有三台服务器,一主二仆,即以太主服务器,二台从服务器
把你的主服务器的数据复制在你的二个从服务器里,复制是为了容错备份,缓存备份,保证数据的完整性,也为读写分离创建条件
2、什么是读写分离
增删改是写,查是读
写去主服务器去写
读取二个从服务器通过负载均衡去读
分工明确,结合缓存实现性能的一大提升
分库分表++Mysql集群
承接主从复制,读写分离,以及Memcached的使用,这时MySQL主库的写压力开始出现瓶颈
而数据量的持续猛增,由于数据量的指数级增长,单单表表上上的的记记录录条条数数增增长长到到千千万万
级,只能继续对架构进行演变。
这个演变,就是使用分库分表来缓解写压力和数据记录条数增长的问题。
3、什么是分库分表
从字面上简单理解,就是把原本存储于一个库的数据分块存储到多个库上,把原本存储
于一个表的数据分块存储到多个表上。
3.1、为什么要分库分表
数据库中的数据量不一定是可控的,在未进行分库分表的情况下,随着时间和业务的发
展,库中的表会越来越多,表中的数据量也会越来越大,相应地,数据操作,增删改查
的开销也会越来越大;另外,由于无法进行分布式部署,而一台服务器的资源(CPU、磁
盘、内存、IO等)是有限的,最终数据库所能承载的数据量、数据处理能力都将遭遇瓶
颈。分库分表就是为了解决这种瓶颈的。
3.2、分库分表的实施策略
分库分表有垂直切分和水平切分两种
3.2.1、垂直切分
即将表按照功能模块、关系密切程度划分出来,部署到不同的库上。例如,我们会建立
商品数据库payDB、用户数据库userDB、日志数据库logDB等,分别用于存储项目的商品
数据、用户数据、日志数据等。
3.2.2、水平切分
当一个表中的数据量过大时,我们可以把该表的数据按照某种规则,例如每300w条记录
拆分一次,进行划分,然后存储到多个结构相同但不在同一个库上的表里。例如,我们
的userDB中的用户数据表中,每一个表的数据量都很大,就可以把userDB切分为结构相
同的多个userDB:part0DB、part1DB等,再将userDB上的用户数据表userTable,切分
为很多userTable:userTable0、userTable1等,然后将这些表按照一定的规则存储到多个userDB上。
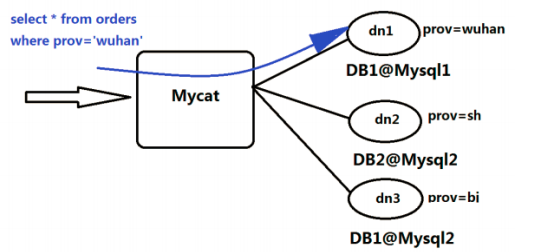
MyCat拦截了用户发送过来的 SQL 语句,对 SQL 语句做一些特定的分析:如分片分
析、路由分析、读写分离分析、缓存分析等,然后将此 SQL 发往后端的真实数据库,并
将返回的结果做适当的处理,最终再返回给用户。















 173
173











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









