







模式匹配:查找字符串中是否存在某个(些)子字符串
在NLP任务中,经常会遇到判断某些关键词是否在文本中以及在文本中的位置,还有些类似分词的应用场景,这时就可以利用模式匹配这种小而美的方式。本文主要涉及KMP算法、Trie树、双数组Trie树以及AC自动机四种算法的原理与实现。文本代码都是由Python实现,代码仅供参考。(更多内容知乎专栏:NLP杂货铺)
KMP算法
Trie树
双数组Trie树
AC自动机
KMP算法
当需要在一段文本(长度为n)中寻找某个确定子串的时候,一般需要 $O(n^2)$的时间复杂度,KMP算法则可以将时间复杂度降低为线性的。其原理如下: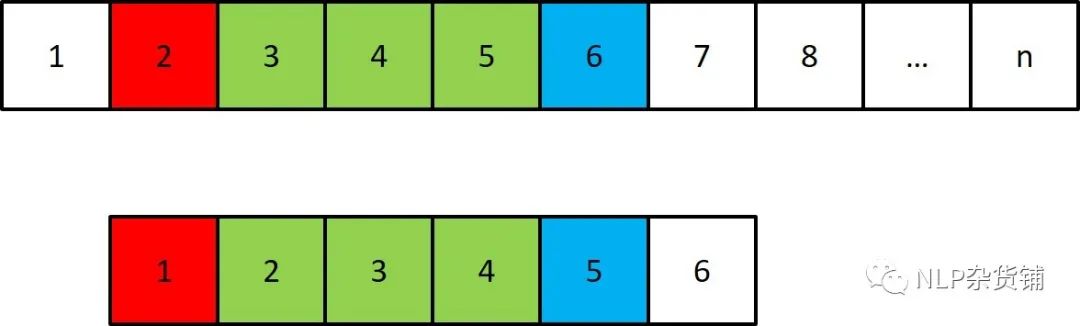 图中,上面表示文本,下面表示匹配的关键词。假设我们匹配到文本6的位置,此时判断关键词5的位置与其是否一致,如果一致,则继续往下匹配,如果不一致,朴素的想法则是像下图一样。
图中,上面表示文本,下面表示匹配的关键词。假设我们匹配到文本6的位置,此时判断关键词5的位置与其是否一致,如果一致,则继续往下匹配,如果不一致,朴素的想法则是像下图一样。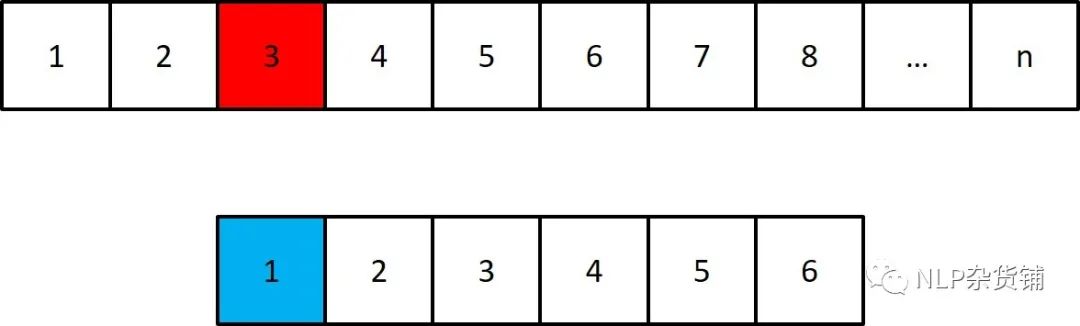 我们将关键词的头移至文本3的位置,开始重新匹配。事实上,我们有更好的选择。我们不需要再匹配文本2-5的位置,因为文本2-5的位置与关键词1-4是一样的,这样我们在匹配前,通过对关键词自身的匹配,就可以知道形如关键词1-4的字符串可以被匹配成什么样,如下图所示:
我们将关键词的头移至文本3的位置,开始重新匹配。事实上,我们有更好的选择。我们不需要再匹配文本2-5的位置,因为文本2-5的位置与关键词1-4是一样的,这样我们在匹配前,通过对关键词自身的匹配,就可以知道形如关键词1-4的字符串可以被匹配成什么样,如下图所示: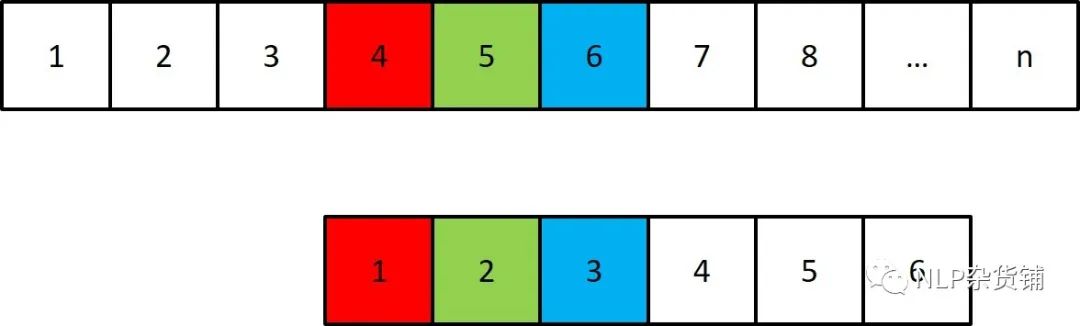 此时假设关键词1-4的后缀中(不包含1-4,只有2-4,3-4,4),是关键词的前缀且最长的是3-4(2-4不是前缀,4不管是不是前缀都比3-4短),此时就相当于文本4-5被关键词1-2匹配了,只需要判断关键词3与文本6是否一致。也就是关键词5的位置不匹配时,可以直接再判断关键词3是否与当前匹配。此时的状态与第一个图的状态一致,后续的匹配过程依次循环,直至匹配结束。
此时假设关键词1-4的后缀中(不包含1-4,只有2-4,3-4,4),是关键词的前缀且最长的是3-4(2-4不是前缀,4不管是不是前缀都比3-4短),此时就相当于文本4-5被关键词1-2匹配了,只需要判断关键词3与文本6是否一致。也就是关键词5的位置不匹配时,可以直接再判断关键词3是否与当前匹配。此时的状态与第一个图的状态一致,后续的匹配过程依次循环,直至匹配结束。
当然,如果关键词1-4的后缀中不存在关键词的前缀,那么直接重文本6开始重新匹配,如下图所示: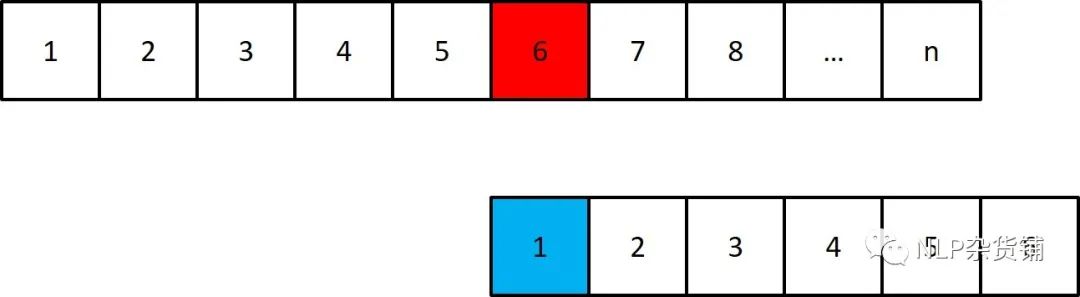 根据上面的分析,我们可以知道,在查找的过程中,不需要回退查找,只要扫一遍文本就可以了。其中关键点在于,当关键词n位置没能匹配时,我们需要跳到m位置进行匹配,通常我们用next数组表示这一关系,next[n]=m。其查找方式如下:
根据上面的分析,我们可以知道,在查找的过程中,不需要回退查找,只要扫一遍文本就可以了。其中关键点在于,当关键词n位置没能匹配时,我们需要跳到m位置进行匹配,通常我们用next数组表示这一关系,next[n]=m。其查找方式如下:
def self_match(self):
if self.length < 2:
return
for i in range(2, self.length):
for j in range(1, i):
if self.key[:i-1 - j] == self.key[j:i - 1]:
# 当前位置的后缀是关键词的前缀
self.next[i] = i-j
break
整个匹配过程,则如下:
def match(self, text):
match_pair = []
current_ind = 0 # 当前关键词位置
for i in range(len(text)):
if text[i] == self.key[current_ind]:
if self.stop_ind(current_ind):
match_pair.append((i - self.length + 1, i + 1))
current_ind = 0
else:
current_ind += 1
else:
while current_ind > 0:
current_ind = self.next[current_ind]
if text[i] == self.key[current_ind]:
current_ind +=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 759
759











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









