






介绍
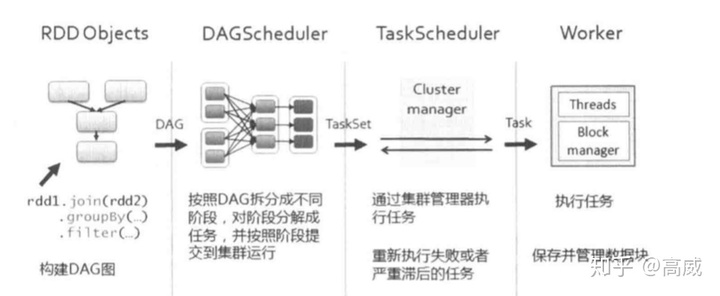
Spark的作业和任务调度系统是核心,它能够有效的进行调度的原因是对任务的划分DAG和容错,使得它对底层到顶层的各个模块之间的调用和处理显得游刃有余。
- JOB:RDD中由行动操作产生的一个或多个调度阶段;
- 调度阶段(stage):每个作业会因为RDD之间的依赖拆分为多组任务集合,称为调度阶段,也叫任务集。调度阶段的划分是由DAGScheduler来划分。
- 任务(task):分发到Executor上的工作任务,是Spark实际执行应用的最小单元。
- DAGScheduler:DAGScheduler是面向调度阶段的任务调度器,负责接收Spark应用提交的作业,根据RDD的依赖关系划分调度阶段,并提交调度阶段给TaskScheduler。
- TaskScheduler:TaskScheduler是面向任务的调度器,接收DAGScheduler提交过来的调度阶段,然后把任务分发到Work节点运行,由Work节点的Executor来运行。
Spark的作业调度主要是基于RDD的一系列操作构成一个作业,然后在Executor中执行,其中操作分为转换和行动操作,对于转换操作的计算是Lazy级别的,只有行动操作才能触发作业的提交。
- Spark程序提交后根据RDD之间的依赖关系构建DAG,交给DAGScheduler进行解析。
- DAGScheduler面向调度阶段的高层次调度器,把DAG按照RDD依赖是否为宽依赖拆分成相互依赖的调度阶段,同时监控运行调度阶段的过程,如果调度失败,则重新提交该调度阶段。每个阶段包含一个或者多个任务集,提交到TaskScheduler进行调度执行。
- 每个TaskScheduler接收DAGScheduler发过来的任务集,然后将任务分发到集群Worker节点中的Executor中运行。任务失败或者某个任务一直未执行完,TaskScheduler负责重试或者启动相同的任务。
- Worker中的Executor接收到TaskScheduler发过来的任务后,多线程去运行,每个线程负责一个任务,运行结束后返回给TaskScheduler。
调度流程
如何划分调度阶段
Spark的调度阶段的划分是有DAGScheduler实现的,DAGScheduler会由最后一个RDD出发,使用广度优先遍历整个依赖树,从而划分调度阶段。
调度阶段的划分依据是以操作是否为宽依赖(也就是是否有shuffle)进行的,如果某个RDD的操作是shuffle时,以该shuffle为界限划分前后两个阶段。
例如:
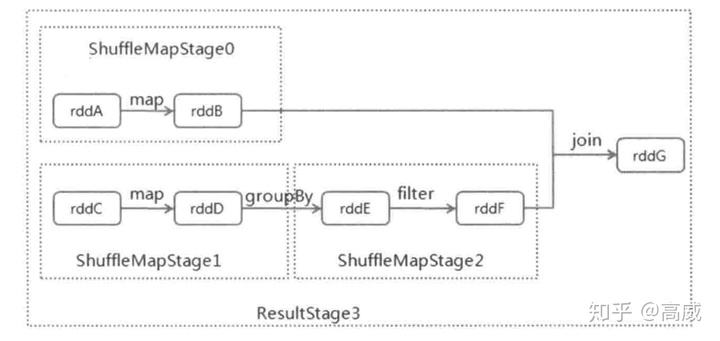
1、从最后一个rddG判断是否存在Shuffle操作,有Join,所以为宽依赖,进而拆分出两个调度阶段ResultStage3和上一层调度;
2、ResultStage3找到了两个rddB 和rddF,由rddB往前找,找到最开始的rddA,且操作为窄依赖,所以rddA和rddB之间的转换为一个调度阶段Stage0.
3、rddF往前找,找到rddE,是窄依赖,在往前找,出现了groupBy为宽依赖,所以这个地方也要划分为两个调度阶段,划分rddE到rddF为一个调度阶段,rddE之前的rddD为一个阶段。
4、rddD,在往前rddC为窄依赖,所以划分为一个调度阶段。
所以这个任务最后由rddG遍历划分为以上4个调度阶段,提交后然后反过来执行。当入口的调度阶段执行完后,相继提交后续的阶段,在判断该调度阶段依赖的父调度阶段的结果是否可用,如果都可用,则提交该调度阶段。如果执行失败,则重新提交该调度阶段。
如何调度
例如:
上面的调度阶段划分完成后,实际的调度顺序
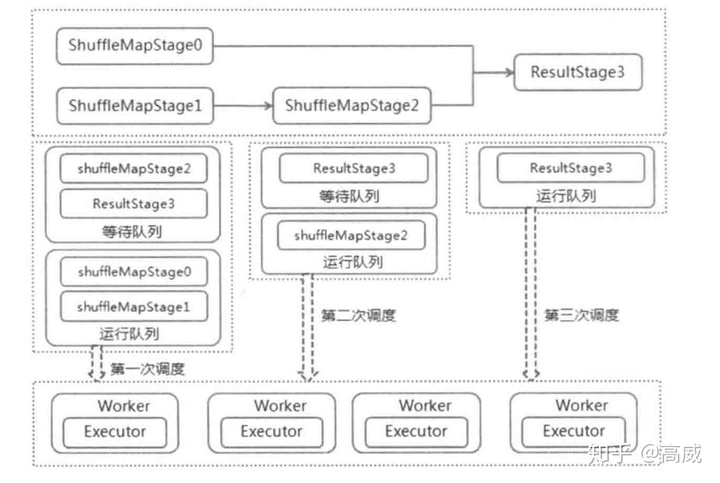
1、获取最后一个调度阶段ResultStage3,通过submitStage提交运行该调度阶段。
2、判断该调度存在两个父调度ShuffleMapStage0和ShuffleMapStage2,所以不能立即执行,将ResultStage3加入等待执行调度阶段列表waitingStages中。
3、递归调用submitStage,知道ShuffleMapStage0不存在父调度阶段,ShuffleMapStage2存在父调度阶段ShuffleMapStage1,所以ShuffleMapStage2加入等待执行调度列表,ShuffleMapStage1不存在父调度阶段,所以ShuffleMapStage0和ShuffleMapStage1作为第一次调度使用submitMissingTasks提交运行。
4、Executor任务执行完后,发送消息,DAGScheduler稽查调度阶段运行情况,如果完成,举行提交调度阶段运行,如果失败,重新提交该调度阶段,直到所有的调度阶段执行完成。
任务执行
当调度阶段提交运行后,DAGScheduler的submitMissingTasks方法中,会根据调度阶段的Partition个数来拆分对应个数的任务,这些任务组成任务集提交到TaskScheduler进行处理,作业中的任务调度ShuffleMapStage会生成ShuffleMapTask,作业的最后调度阶段ResultStage生成ResultTask。
对于ShuffleMapTask,计算结果会写到BlockManager中,返回DAGScheduler一个MapStatus对象,存储BlockManager的基本信息,这些存储信息将会成为下一个阶段任务需要获取的输入数据依据。
对于ResultTask,返回最终的func函数的计算结果。
- 向Diver端发送任务运行的开始消息;
- 对任务运行需要的文件、JAR包、代码反序列化;
- 调用Task的RunTask对象的子类ShuffleMapTask,计算结果写到BlockManager,生成MapStatus对象;
- 调用ShuffleMapTask的RunTask方法,反序列化获取RDD信息和RDD的依赖,计算结果写到BlockManager,生成MapStatus对象;
- 调用ResultTask的RunTask方法,生成最后结果;
- 判断作业是否完成,完成后清除依赖资源,发送消息给系统告知执行完毕;
- 获取执行结果发送Diver端;
调度算法
FIFO调度策略
调度过程中,Master先启动等待列表中应用程序的Driver,并尽可能的分散在集群的Worker节点上(充分利用集群资源,而且有利于数据的本地性),根据集群的内存和CPU使用情况,对等待运行的应用程序进行资源分配,分配算法上根据先来先分配,先分配的任务尽可能的获取满足条件的资源,后分配的任务在剩余资源中再次筛选,如果没有合适的资源只能等待:
- 比较作业的优先级(根据作业的编号,编号越小优先级越高),执行优先级高的;
- 如果是同一个作业,比较调度阶段的优先级(调度阶段的编号,编号越小,优先级越高);
FAIR调度策略
调度过程中,先获取调度的饥饿程度,饥饿程度为正在运行的任务是否小于最小任务,如果是,表示调度处理处于饥饿程度。获取饥饿程度后比较:
- 如果某个调度处于饥饿状态另一个非饥饿状态,优先满足处于饥饿状态的调度;
- 都处于饥饿状态,比较资源比,优先满足资源比小的调度;
- 都处于非饥饿状态,比较权重,优先满足权重比较小的调度;
- 以上情况都相同,按照调度的名称进行排序;
数据的计算尽可能在数据所在的节点中运行,这样可以减少不必要的网络传输,毕竟移动计算比移动数据的代价要小很多。
- 任务处于作业开始的调度阶段内,这些任务的RDD分区都肯定有首选运行为主,该为主也是任务的首选位置,数据本地性为NODE_LOCAL。
- 非开头调度阶段,可以根据父调度阶段运行为主得到任务首选位置;
- 在任务分配运行节点是,先判断最佳运行阶段是否空闲,如果没有足够的资源,任务会先等待一段时间,一般为3S,如果还是不足则会找到次佳节点运行。














 3247
3247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









