





近年来,神经网络收敛位置的平滑性(flatness)被证明与模型泛化能力有直接的联系,而现有对平滑性的定义仍局限于sharpness-aware minimization(SAM)及其变体的零阶平滑性(zeroth-order flatness),即收敛位置邻域域内最大损失值与当前损失值的差。清华大学崔鹏教授的CVPR2023 Highlight论文”Gradient norm aware minimization seeks first-order flatness and improves generalization”发现零阶平滑性有一定的局限性,所以提出了一阶平滑性的概念,并进一步提出了可以约束一阶平滑性的优化器GAM,大量实验证明GAM相比于现有优化器有更强的泛化能力
- 论文:https://arxiv.org/abs/2303.03108
- 代码:https://github.com/xxgege/GAM
神经网络的泛化能力与收敛位置平滑性
现今大型神经网络的参数规模急剧增大,模型在训练过程中对训练数据的拟合能力也大幅变强,但充分拟合训练数据并不一定代表模型在测试数据上表现可靠。如图1所示,模型在训练数据上持续优化甚至可能导致其在测试数据上的表现下降。而在绝大多数场景中,模型在测试场景下的表现才是更重要的。
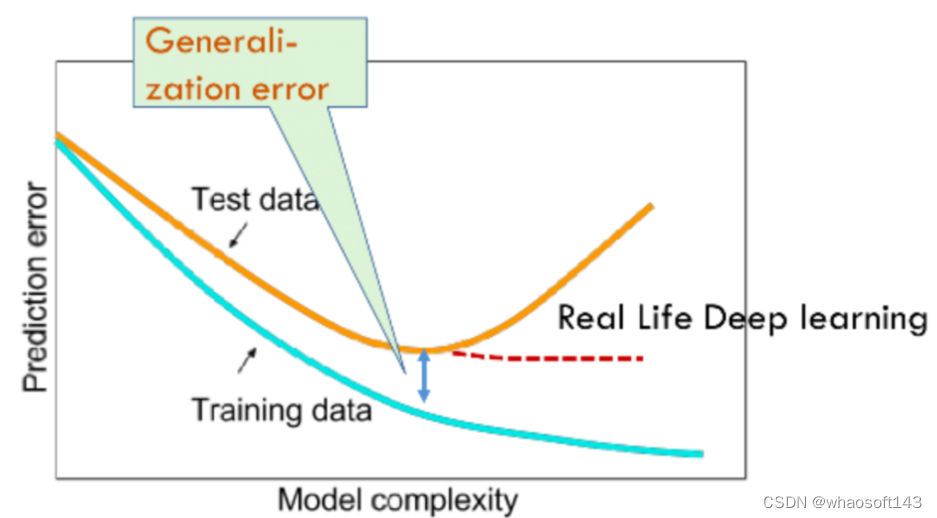
图1 神经网络的泛化误差
近年来,很多工作试图探索影响深度模型泛化能力的因素。如图2所示为使用使用残差连接的网络与不使用残差连接的网络 loss landscape(模型参数取值于其loss关系的可视化) 对比。当模型不使用残差连接时,其loss landscape明显更加陡峭,有很多尖锐的凸起和凹陷,而使用残差连接的模型loss landscape会显著平滑,收敛位置(极小值点)也相对更加平缓。联想到残差连接极大提升了深度模型可扩展性和泛化性,很多后续工作开始研究收敛位置平滑性与模型泛化性的关系。
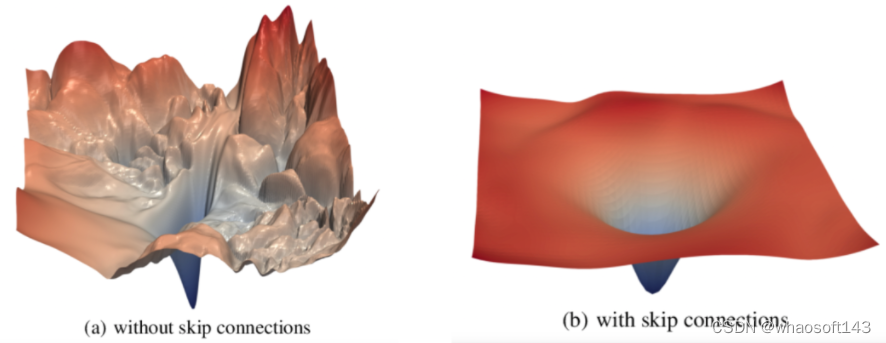
图2 使用残差连接的网络与不使用残差连接的网络 loss landscape 对比
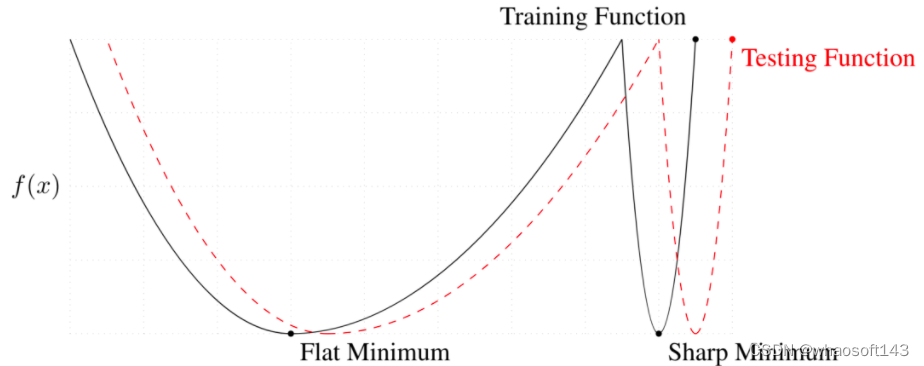
图3 平滑极值点的泛化误差大于尖锐极值点的泛化误差
Nitish Shirish等人[2]通过实验证明平滑的极小值点(flat minima)的泛化能力强于尖锐的极小值点(sharp minima),直觉性的示例如图3所示,更平滑的极值点相比于尖锐极小值点的测试误差(如红色虚线所示)更小。
模型参数收敛位置的零阶平滑性与一阶平滑性
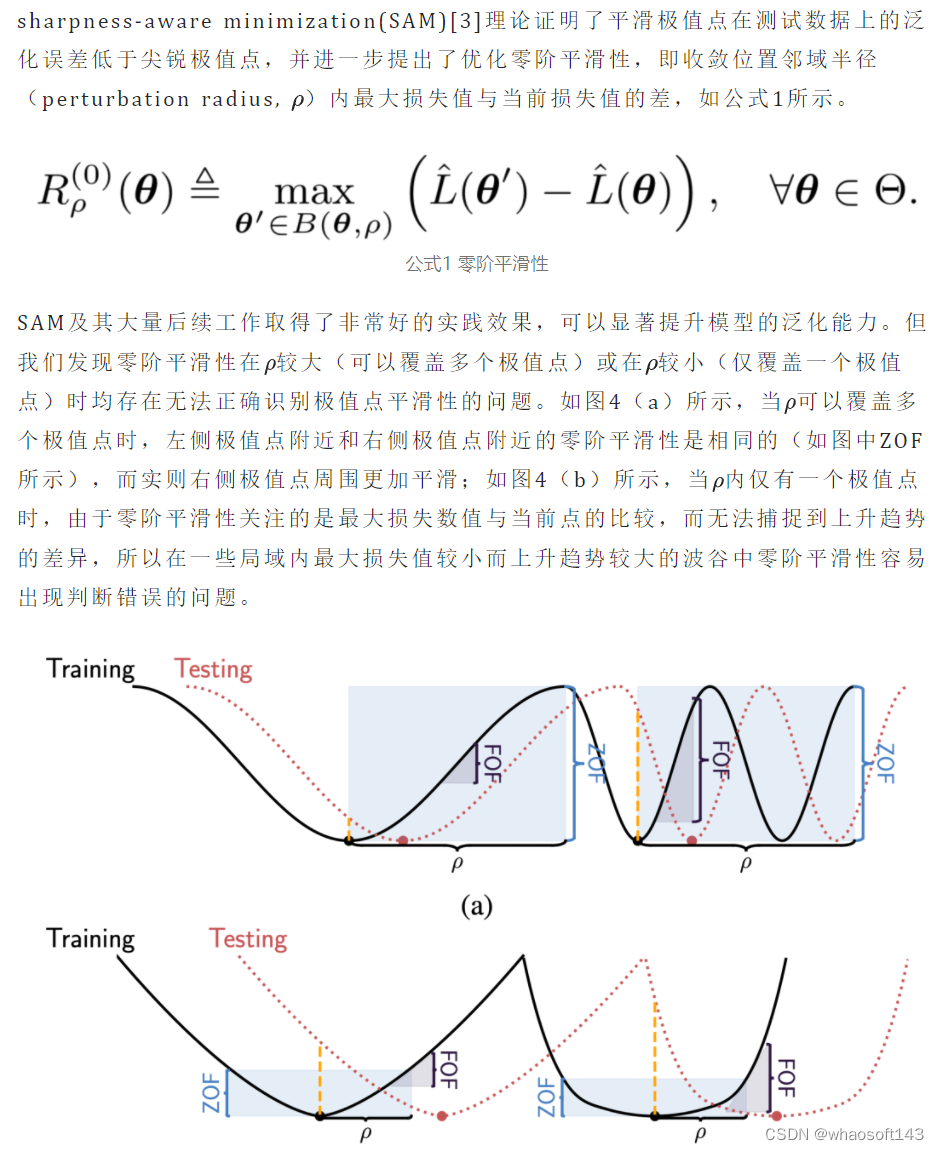
图4 零阶平滑性(zeroth-order flatness, ZOF)vs 一阶平滑性(first-order flatness, FOF)
基于以上的观察,我们提出一阶平滑性(first-order flatness, FOF)的概念,如公式2所示。相比于零阶平滑性,一阶平滑性关注的是参数邻域内最大的梯度的范数,所以更能捕捉loss的变化趋势。在图4所示的示例中,一阶平滑性可以正确区分左右两侧的波谷附近的平滑性。进一步,由于loss在当前参数邻域内的变化会被邻域内最大的梯度控制,所以保证了一阶平滑性即可以一定程度上控制零阶平滑性。
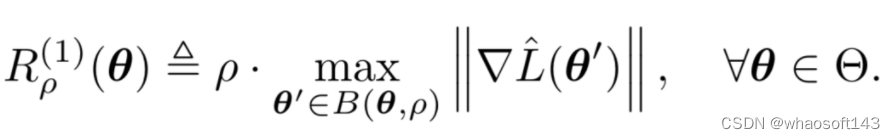
公式2 一阶平滑性
GAM:一阶平滑性优化器
基于一阶平滑性,我们提出了GAM(Gradient norm Aware Minimization)优化算法,GAM在训练过程中同时优化预测误差和邻域内最大梯度的范数。由于邻域内最大的梯度范数无法直接求解,我们通过一次梯度上升来近似该值,近似过程如公式3所示。最终结果可以用Pytorch或Tensorflow中的vector-Hessian products(vhp)进行计算。
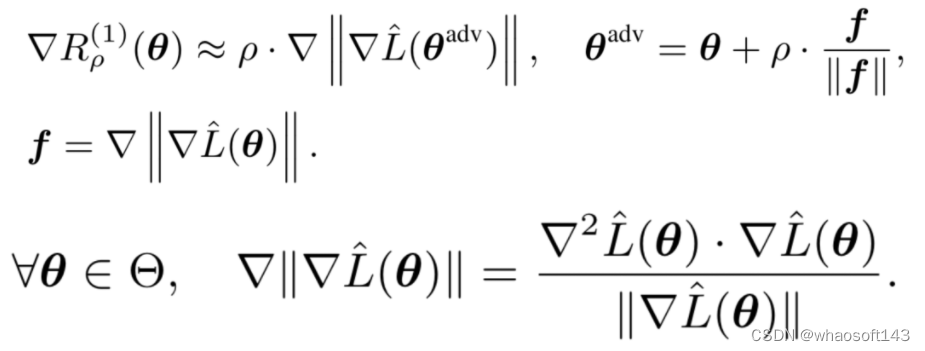
GAM的完整优化过程如算法1所示。

算法1 GAM优化过程
由于一阶平滑性直接约束邻域内最大梯度范数,所以在损失函数二阶近似下我们很容易得到一阶平滑性与Hessian最大特征值的关系,如公式4所示。Hessian的最大特征值被公认为衡量收敛位置平滑性、曲度的指标,但由于其无法直接优化,所以很多现有工作将其视为平滑性的评价指标,而GAM可以近似约束Hessian的最大特征值。
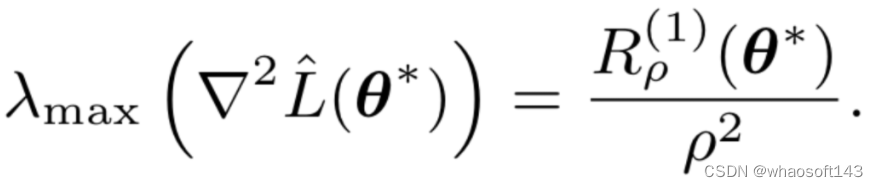
公式4一阶平滑性与Hessian最大特征值
进一步地,我们可以给出GAM的泛化误差上界,如公式5所示。公式5表明,模型在测试数据上的泛化误差会被其在训练数据上的损失与一阶平滑性控制,所以同时对其进行优化(GAM)即可控制模型的泛化误差。

公式5 GAM的泛化误差上界
我们还可以给出GAM的收敛性质,如公式6所示,GAM的梯度会随着时间T的增加而减小,并逐渐趋近于0。
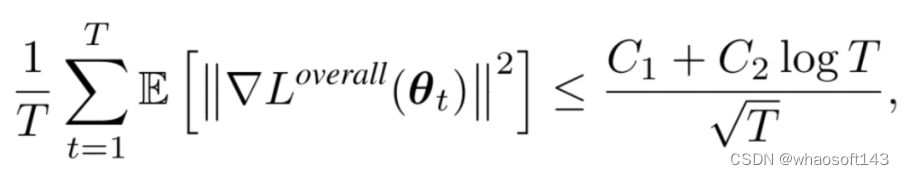
公式6 GAM的收敛性质,其中C1与C2为常数
实验结果
我们分别在CIFAR,ImageNet,Stanford Cars,Oxford_IIIT_Pets等数据集上验证GAM的泛化能力。部分结果如表1与表2所示。与SGD和AdamW相比,GAM可以显著提升模型的泛化能力,如与SGD相比,GAM可将PyramidNet110在CIFAR-100上的准确率提升2.17%;与AdamW相比,GAM可将Vit-B/32 在ImageNet上的top-1准确率提升2.43%。另外,与SAM结合后GAM可以进一步提升SAM的泛化能力,这或许是由于SAM和GAM都是用了一系列近似操作(例如泰勒展开)来估计零阶/一阶平滑性,所以SAM和GAM的结合或可以起到互补的作用,降低彼此由于近似估计带来的误差。
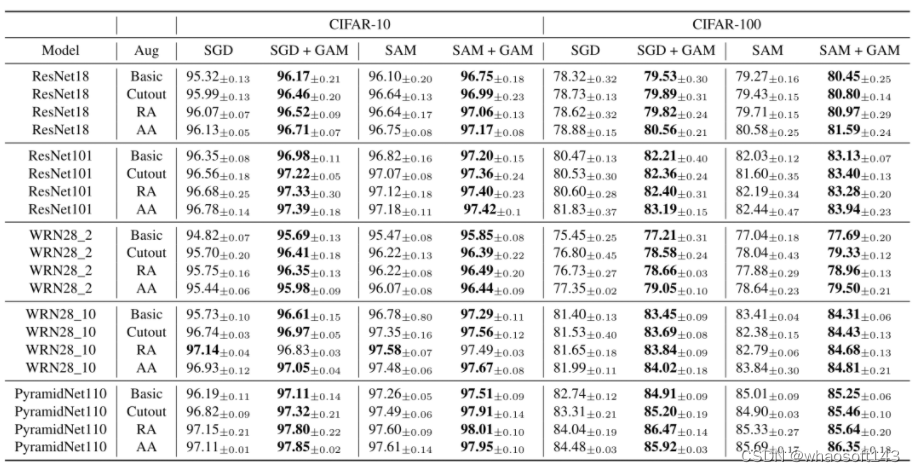
表2 GAM在CIFAR10/100 上的结果
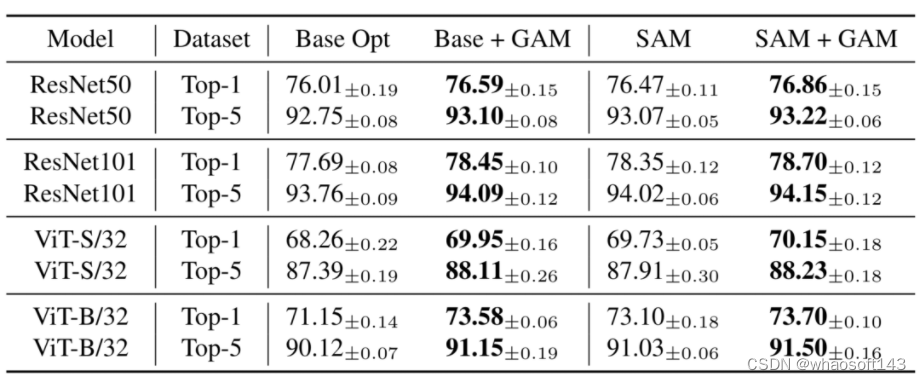
表1 GAM在ImageNet上的结果
为了进一步研究GAM对收敛位置平滑性的影响,我们分析了收敛位置Hessian的最大特征值与迹,如图5所示。相比于SGD和SAM,GAM可在训练过程中显著约束Hessian的最大特征值与迹(均为公认平滑性指标),即帮助模型收敛到更加平滑的极值点。
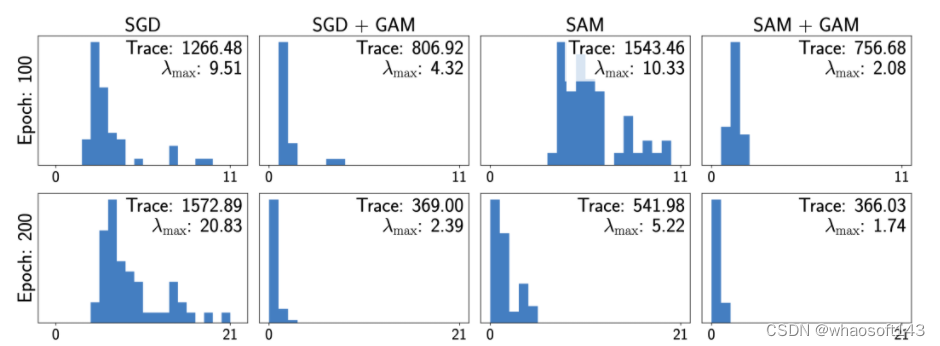
图5 SGD、SAM、GAM Hessian矩阵的最大特征值与迹对比
在CIFAR-100上SGD、SAM、GAM收敛位置的可视化如图6所示,GAM可以显著提升收敛位置的平滑程度,即提升模型的泛化能力。
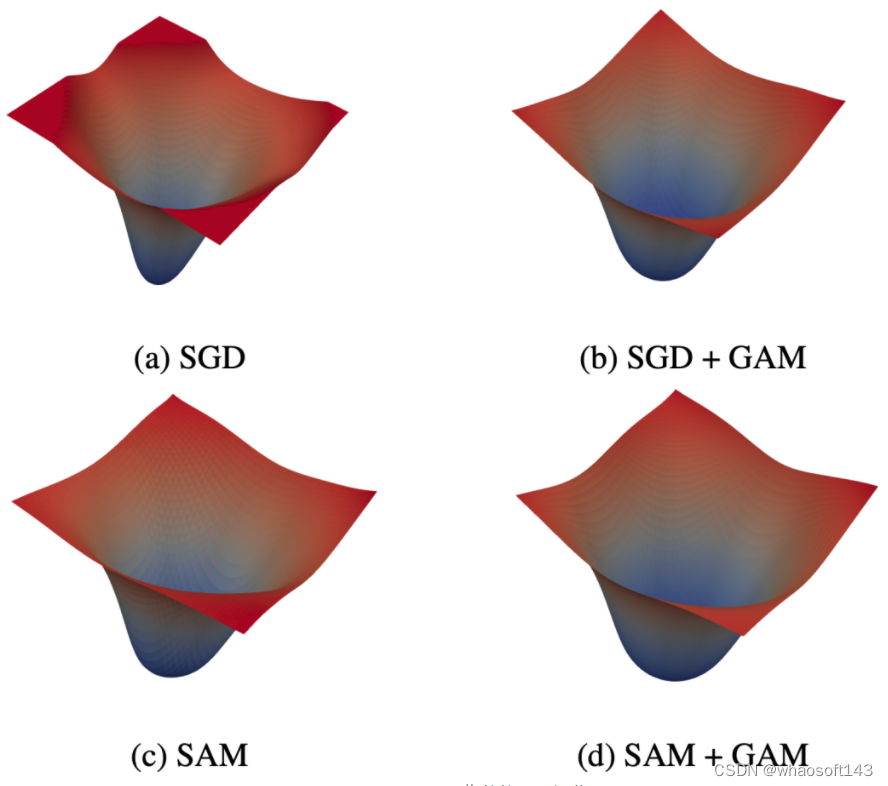
图6 SGD、SAM、GAM 收敛位置可视化















 1449
1449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









