







之所以用matlab实现,是因为这是数据挖掘课的几个大作业之一,作业要求,不然也不会这么蛋疼用matlab....(因为我不会matlab...)
朴素贝叶斯原理非常简单,最重要的就是概率公式:
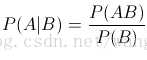
下面贴用matlab的具体实现
train阶段:
[spmatrix, tokenlist, trainCategory] = readMatrix('MATRIX.TRAIN');
trainMatrix = full(spmatrix);
numTrainDocs = size(trainMatrix, 1);
numTokens = size(trainMatrix, 2);
% trainMatrix is now a (numTrainDocs x numTokens) matrix.
% Each row represents a unique document (email).
% The j-th column of the row $i$ represents the number of times the j-th
% token appeared in email $i$.
% tokenlist is a long string containing the list of all tokens (words).
% These tokens are easily known by position in the
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 575
575











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









