





本文内容原创,未经作者许可禁止转载!
目录
一、前言
二、摘要
三、关键词
四、算法原理
五、经典应用
六、R建模
1、载入相关包(内含彩蛋):
1.1 library包载入
1.2 pacman包载入(彩蛋)
2、读入数据:
3、可视化:
一、前言
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法,最为广泛的两种分类模型是决策树模型和朴素贝叶斯模型。和决策树模型相比,朴素贝叶斯分类器发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。同时,NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。理论上,NBC模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为NBC模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,这给NBC模型的正确分类带来了一定影响。
二、摘要
朴素贝叶斯模型的精确度很高,如果已经准备好了一个带标签的数据集,则我们可以使用朴素贝叶斯模型,朴素贝叶斯模型的训练非常容易,模型的更新也非常迅速。
三、关键词
朴素贝叶斯;分类器
四、算法原理
朴素贝叶斯分类(NBC)是以贝叶斯定理为基础并且假设特征条件之间相互独立的方法,先通过已给定的训练集,以特征词之间独立作为前提假设,学习从输入到输出的联合概率分布,再基于学习到的模型,输入X求出使得后验概率最大的输出Y。


五、经典应用
垃圾邮件分类是朴素贝叶斯的经典应用。其原理是创造一个特征向量,每一项对应着词典中的一个词,之后根据每个词是否出现在邮件中,构成一个特征向量。每封邮件都可以表示为一个二元向量,这个向量的第j个元素是0还是1取决于总共要考虑的单词个数。
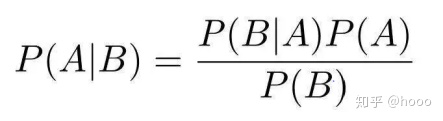
朴素贝叶斯分类应用定理来计算给定测试集个案条件下的类概率。朴素贝叶斯模型的核心概念是独立性。(其中c是一个类,X1,X2,X3……是一组特征向量,是数据集中预测变量的观测值)
概率P(c)可以视为类c的先验预期,而P(X1,..,Xp | c)则是在给定类c的条件下测试个案的似然概率。最后,分母是观测到的证据的概率。由于分母对所有类都是常数,所以决策仅取决于方程中的分子。
应用条件概率的统计定义和预测变量间独立的条件假设,推导出分式中的分子为:
朴素贝叶斯方法用训练集样本的相对频率来估计这些概率。应用这些估计值,该方法按照类概率公式来输出每一个测试个案的类概率。贝叶斯法则会帮助研究人员计算出真正想知道的概率值p(c | x)。
六、R建模
1、载入相关包:
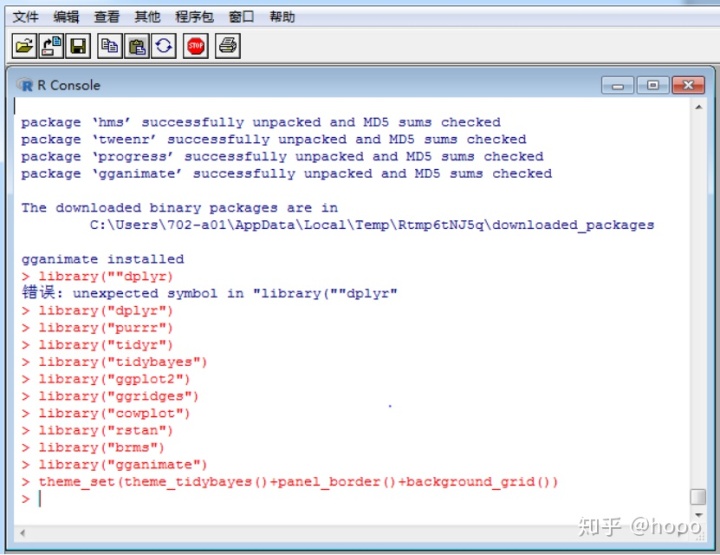
1.1 library包载入
首先分析所需要的相关包,然后进行载入,本项目中所用的包有:
l dplyr
l purrr
l tidyr
l tidybayes
l ggridges
l cowplot
l rstan
l brms
l gganimate
l ggplot2
通过library(“packagename”)将以上包挨个完成载入。
1.2 pacman包载入
对于大规模数据的挖掘项目,多达十几个packages的载入,library( )命令会使得工作量变得很大。在这里推荐一个在R中一次性安装加载多个包的——pacman包。
- pacman包是R包集群管理的工具,能够减少大量packages操作相关的键入。依托函数library( )为基础,pacman包能够在部署R工程时极大的提高集群管理的效率并减少有关packages的繁琐调用代码。其中p_load()方法用于一次性下载/装载/更新多个packages。
- 首先对pacman包进行安装:
先对CRAN镜像进行设定,输入代码:install.packages(“pacman”)
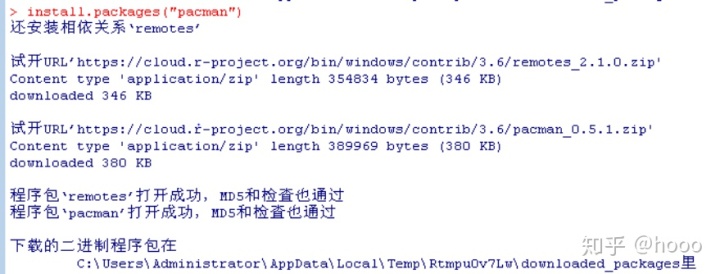
- pacman包安装成功后使用p_load( )函数,将以上对packages集群的下载及安装代码缩短为:
pacman::p_load(packagename1,packagename2,……,packagenameN)
安装实例如下图所示:

- 同时所需要的相关包的依托包也自动完成载入(若存在一些依托包下载失败的情况可以再手动官网下载相关包),打开包路径去检测packages集群的下载及安装是否正确,示意图如下:
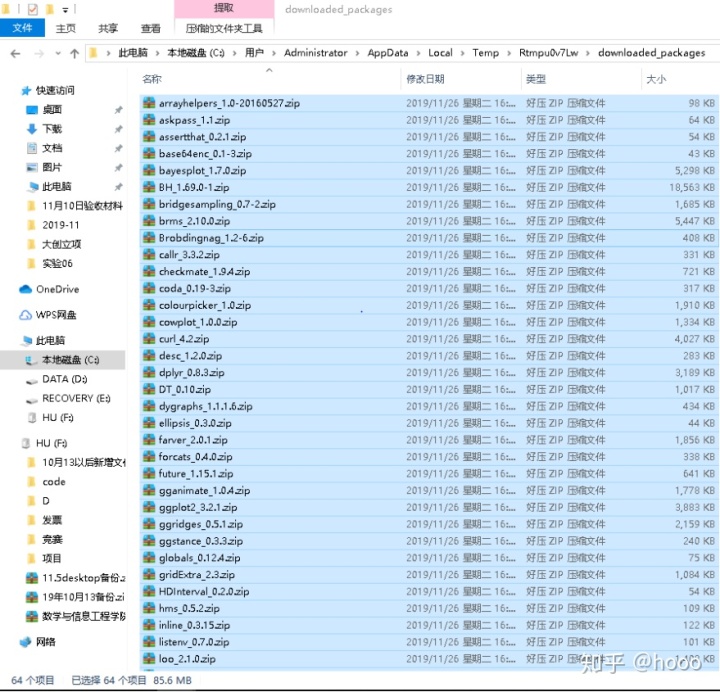
- 我们可以发现相关的包及其依托包成功安装,那么接下来我们可以开始对数据进行读入操作。
2、读入数据:
rnorm(n, mean = 0, sd = 1)
n 为产生随机值个数(长度),mean 是平均数, sd 是标准差 。
使用该函数的时候后,一般要赋予它 3个值.
rnorm() 函数会随机正态分布,然后随机抽样 或者取值 n 次,
>rnorm(5,0,1) 以N(0,1)的正态分布,分别列出5个值。
r 这列代表随机,可以替换成dnorm, pnorm, qnorm 作不同计算
r = random = 随机, d= density = 密度,
p= probability = 概率 , q =quantile = 分位
参数说明:set.seed( ):设置随机数种子,确保实验结果可以复现。
代码如下:
> set.seed(4118)
> n=100
> cens_df=tibble(
+ y_star=rnorm(n,0.5,n),
+ y_lower=floor(y_star),
+ y_upper=ceiling(y_star),
+ censoring="interval"
+ )
> cens_df
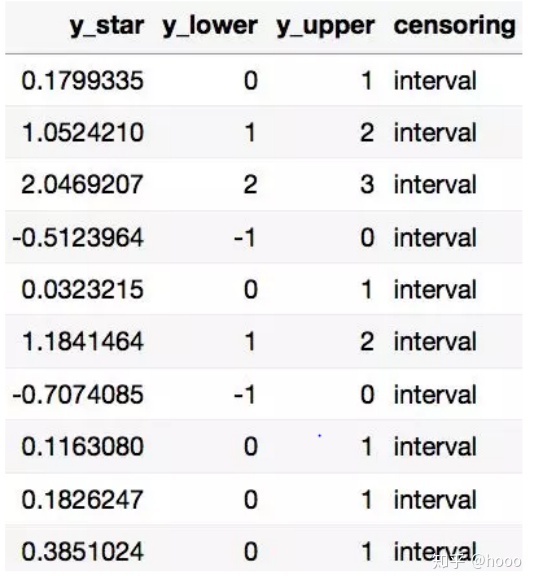
则cens_df数据集包含生成的n=100条数据(对前十条记录进行截取),数据样本如下图所示:
设置工作目录后,通过write.csv()方法将数据框中数据导出到csv文件保存,效果如下:
导出的csv文件在工作目录下,效果如下:
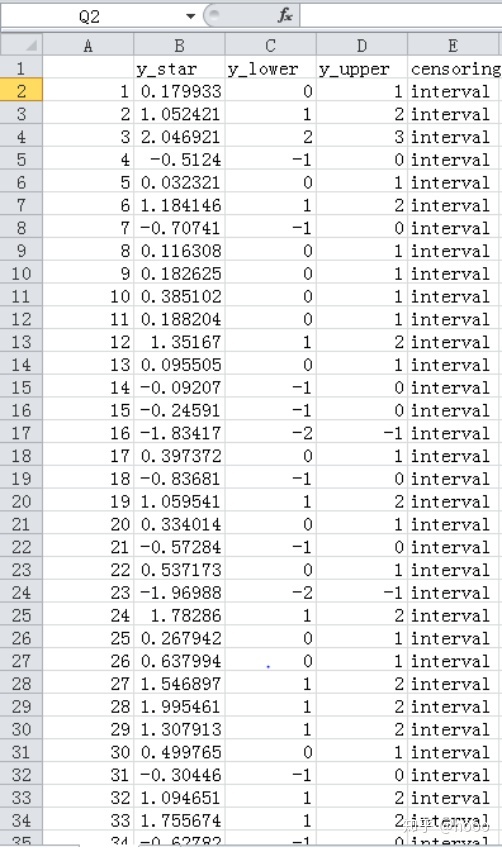
打开csv文件查看数据是否成功导出,可以发现导出成功,效果如下:
数据读入操作完成,接下来对数据进行可视化操作。
3、可视化操作:
3.1可视化:
首先对可视化过程中可能涉及到的几个包与函数进行功能说明,本文的可视化实现全是基于ggplot()函数来完成各图像的绘制。
ggplot(data,aes(x,y)) + 初始化图形并指定数据源和作图变量
geom_type()+ 指定图形的类型
annotate()+ 添加文本注释
labs()+ 修改住坐标和坐标轴标题
- 管道函数:
%>%来自dplyr包的管道函数,其作用是将前一步的结果直接传参给下一步的函数,从而省略了中间的赋值步骤,可以大量减少内存中的对象,节省内存。
符号%>%,这是管道操作,其意思是将%>%左边的对象传递给右边的函数,作为第一个选项的设置(或剩下唯一一个选项的设置)
- geom_density_ridges():
主要根据密度绘制山脊线图,该函数首先会根据数据计算密度然后绘图,此时美学映射height没有必要写入函数中。
- geom_jitter():
在R中散点图的时候会经常出现,点重合比较严重的现象,这对我们寻找数据规律或者观察数据有很大的干扰。所幸的是R中,可以用geom_jitter()函数来调整,消除点的重合。
geom_jitter(mapping = NULL, data = NULL, stat = "identity", position = "jitter", ..., width = NULL, height = NULL, na.rm = FALSE, show.legend = NA, inherit.aes = TRUE)就参数而言,geom_jitter()和其他函数差别不大,特别的两个参数是width,height
width 用于调节点波动的宽度
height 用于调节点波动的高度
- 标度Scale:
标度(scale),是将数据空间(标度的定义域)映射到图形属性空间(标度的值域)
的一个函数。每一种图形属性都有一个默认的标度,当我们每一次使用这个图形属性时都会自动
添加到图形中。
- geom_dotplot:
ggplot2包中绘制点图的函数有两个:geom_point和 geom_dotplot,当使用geom_dotplot绘图时,point的形状是dot,不能改变点的形状,因此,geom_dotplot 叫做散点图(Scatter Plot),通过绘制点来呈现数据的分布,对点分箱的方法有两种:点密度(dot-density )和直方点(histodot)。当使用点密度分箱(bin)方式时,分箱的位置是由数据和binwidth决定的,会根据数据进行变化,但不会大于binwidth指定的宽度;当使用直方点分箱方式时,分箱有固定的位置和固定的宽度,就像由点构成的直方图(histogram)。
bin是分箱的意思,在统计学中,数据分箱是一种把多个连续值分割成多个区间的方法,每一个小区间叫做一个bin(bucket),这就意味着每个bin定义一个数值区间,连续值会落到相应的区间中。对点进行分箱时,点的位置(Position adjustment)有多种调整方式:
identity:不调整
dodge:垂直方向不调整,只调整水平位置
nudge:在一定的范围内调整水平和垂直位置
jitter:抖动,当具有离散位置和相对较少的点数时,抖动很有用
jitterdodge:同时jitter和 dodge
stack:堆叠,
fill:填充,用于条形图
- 使用geom_dotplot()函数来绘制点图:
geom_dotplot(mapping = NULL, data = NULL, position = "identity", ...,
binwidth = NULL, binaxis = "x", method = "dotdensity",
binpositions = "bygroup", stackdir = "up", stackratio = 1,
dotsize = 1, stackgroups = FALSE, origin = NULL, right = TRUE,
width = 0.9, drop = FALSE, na.rm = FALSE, show.legend = NA,
inherit.aes = TRUE)
uncensored_plot=cens_df %>%
ggplot(aes(y=””,x=y_star))+
geom_density_ridges(bandwidth=0.5,scale=1.5)+
geom_jitter(aes(y=0.75,color=ordered(y_lower)),position=position_jitter(height=0.2))+
ylab(NULL)+
scale_x_continuous(breaks=-4:4,limits=c(-4,4))
censored_plot=cens_df %>%
ggplot(aes(y=””,x=(y_lower+y_upper)/2))+
geom_dotplot(
aes(fill=ordered(y_lower)),
method=”histodot”,origin=-4,binwidth=1,dotsize=0.5,stackratio=.8,show.legend=FALSE, stackgroups=TRUE,binpositions=”all”,color=NA)+
geom_segment(
aes(x=y+0.5,xend=y+0.5,y=1.75,yend=1.5,color=ordered(y)),
data=data.frame(y=unique(cens_df$y_lower)),show.legend=FALSE,
arrow=arrow(type=”closed”,length=unit(7,”points”)),size=1)+
ylab(NULL)+
xlab(“interval-censored y”)+
scale_x_continuous(breaks=-4:4,limits=c(-4,4))
plot_grid(align=”v”,ncol=1,rel_heights=c(1,2.5),
uncensored_plot,
censored_plot
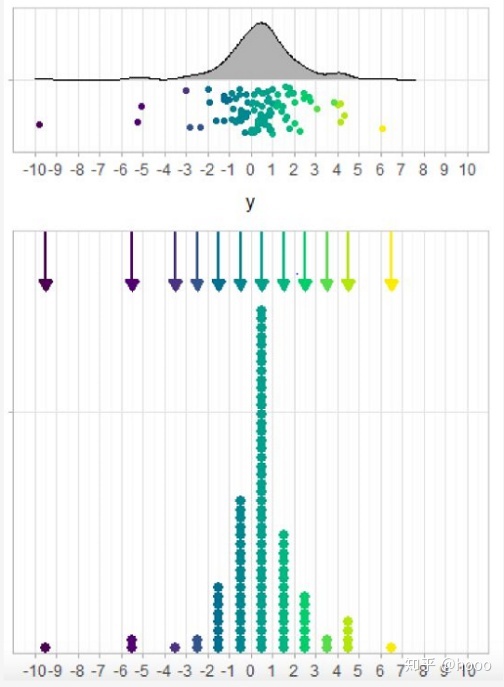
3.2数值比较:
ggplot2 geom设置—散点图
散点图也是目前R中的常用的图形之一
geom_point(mapping = NULL, data = NULL, stat = "identity", position = "identity", na.rm = FALSE, ...),类似上文中的geom_jitter
m %>%
spread_draws(condition_mean[condition],response_sd) %>%
mutate(y_rep=rnorm(n(),condition_mean,response_sd)) %>%
median_qi(y_rep, .width=c(.95, .8, .5)) %>%
ggplot(aes(y=fct_rev(condition),x=y_rep))+
geom_intervalh()+
geom_point(aes(x=response),data=ABC)+
scale_color_brewer()
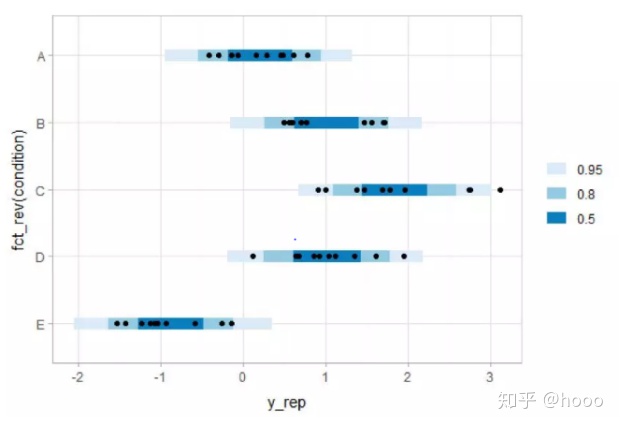
3.3 绘制分位数点图:
spread用来扩展表,把某一列的值(键值对)分开拆成多列。
spread(data, key, value, fill = NA, convert = FALSE, drop =TRUE, sep = NULL)
key是原来要拆的那一列的名字(变量名),value是拆出来的那些列的值应该填什么(填原表的哪一列)
spread_draws(condition_mean[condition]) %>%
do(tibble(condition_mean=quantile(.$condition_mean,ppoints(100)))%>%
ggplot(aes(x= condition_mean)) +
geom_dotplot(binwidth =.04) +
facet_grid(fct_rev(condition) ~.) +
scale_y_continuous(breaks =NULL)
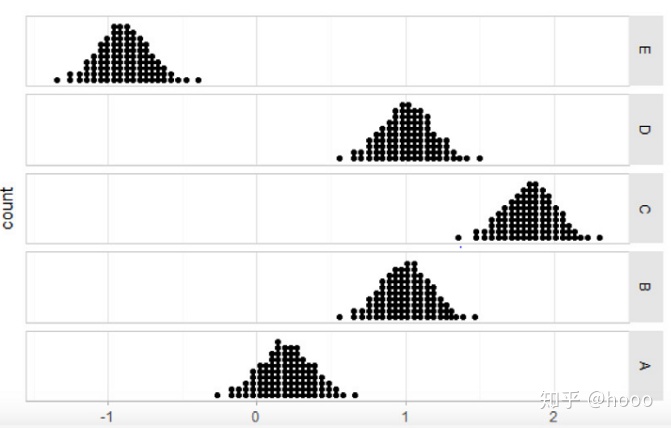
3.4绘制小提琴图:
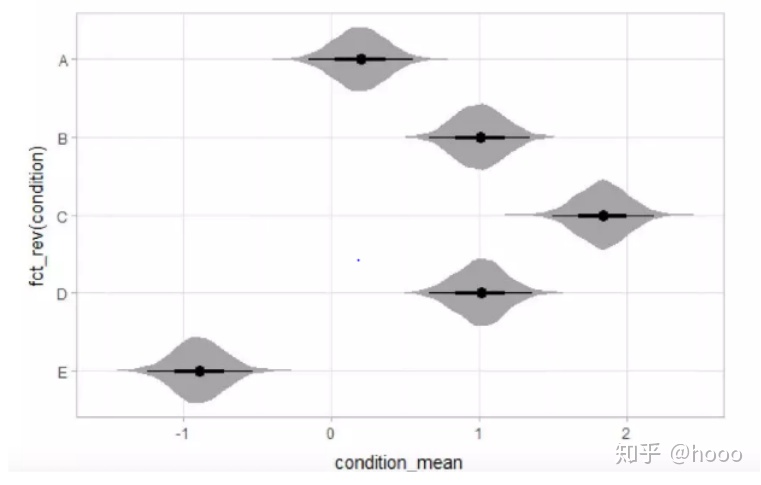
小提琴图(Violin Plot)用于显示数据分布及其概率密度,因其形状酷似小提琴而得名。
这种图表结合了箱线图和密度图的特征,主要用来显示数据的分布形状。中间的黑色粗条表示四分位数范围,从其延伸的幼细黑线代表95% 置信区间,而白点则为中位数。如果需要,中间的箱线图还可以替换为误差条图。
箱线图或误差条图在数据显示方面受到限制,简单的设计往往隐藏了有关数据分布的重要细节。例如使用箱线图时,我们不能了解数据分布是双模还是多模。小提琴图能够展示数据的真正分布范围和形状。值得注意的是,虽然小提琴图可以显示更多详情,但它们也可能包含较多干扰信息。
使用工具:R语言中的ggplot2工具包。
spread_draws(condition_mean[condition]) %>%
ggplot(aes(y=fct_rev(cens_df),x= cens_df))+
geom_violinh(color=NA,fill=”gray65”)+
stat_pointintervalh(.width=c(.95,.66))
七、总结
7.1小结:
朴素贝叶斯(Naive Bayes)是一种生成学习算法,即对p(x | y)进行建模,该理论是基于贝叶斯定理的一种统计分类方法,应用到预测变量之间具有独立想这一假设。在实际应用中,通常会有一个简单的基础模型以备使用。
我们首先搜集相关资料,基于朴素贝叶斯构造分类模型,朴素贝叶斯模型的精确度很高,如果已经准备好了一个带标签的数据集,则我们可以使用朴素贝叶斯模型,朴素贝叶斯模型的训练非常容易,模型的更新也非常迅速。
通过对于资料进行整合,发现需要依托的包比较大,然后一个一个导入package使得工作量过大,便在网上查询有没有什么更便捷的方法可以一次load所需要的所有包。果不其然我们找到了pacman包,该包的具体依托函数library( )为基础,pacman包能够在部署R工程时极大的提高集群管理的效率并减少有关packages的繁琐调用代码。其中p_load()方法用于一次性下载/装载/更新多个packages。
完成了相关package的导入以后我们便开始生成相关的随机数,作为我们的数据集,在这里用到了rnorm和set.seed,完成了100条记录的生成,并且导出为csv文件。
接下来最后一步就是对我们生成数据进行可视化操作,分别进行了基本的可视化操作,然后对模型进行数值比较,再是绘制分位数点图和绘制小提琴图,完成了可视化实现。
7.2 收获:
本题目灵感来源于当时所作的”基于神经网络的故障电弧检测研究”科创项目,其中目前研究多为通过快速傅里叶变换来完成故障电弧的数据处理,还有一些相关的生成学习算法,然后就有了基于朴素贝叶斯构造分类模型的灵感。
本论文的完成加深了对各类包的理解,同时以及ggplot包的各种绘图神器,绘制一些简单的散点图、折线图、箱型图、小提琴等图形。还对R语言完成从零到简单入门,进一步的感受到R语言对于庞大数据量进行可视化操作的便利度,相比于matlab的图形处理在很多方面都有更多的便利。
欢迎大家加入人工智能圈参与交流
http://www.zhihu.com/club/1211742218421227520www.zhihu.com














 1903
1903











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









