







销售过程是一个多环节的过程,哪个步骤有了过大瑕疵,都会导致业绩急剧下滑。而诊断出哪个步骤有瑕疵,除了无形的经验,还有量化的诊断方式,就是今天要讨论的主角:转化漏斗模型。
示例数据
为了详细讨论这个漏斗的实现过程,我们举一个具体的网上商城的例子,被分析的数据也不复杂,只有一个事件表:
用户 ID:用户编码
事件 ID:事件编码
事件属性:不同事件有不同属性;json 格式,{“content”:”computer”,”page_num”:1}
时间:事件发生的时间
事件类型和事件属性如下所示
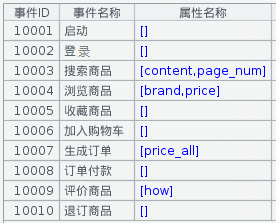
需求定义
目标结果是获得某个操作流程在每个操作的客户流失率,如下图,登录的用户有 20000 人;其中有 12000 人进行了:登录 -> 搜索商品;其中有 8000 人进行了:登录 -> 搜索商品 -> 查看商品。如下图所示:
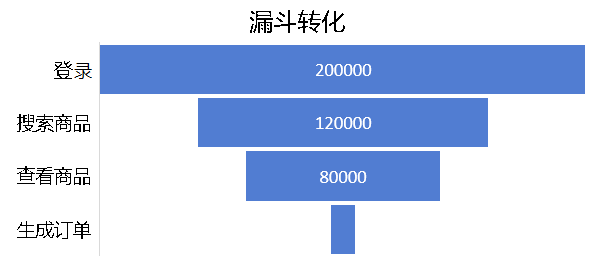
每个事件后都可能流失一些用户,整个图示就象一个漏斗形状,所以被称为漏斗转换分析。
我们来研究这个运算的一些需求点:
针对同一个用户,我们观察下面这两组数据,因为事件顺序关系,我们认为 1000001 用户只发生了登录行为,而 1000002 的三个事件符合目标顺序,到查看商品事件才流失
用户 ID
事件 ID
事件名称
时间
1000001
10002
登录
2017/2/3 0:01
1000001
10004
浏览产品
2017/2/3 0:03
1000001
10003
搜索产品
2017/2/3 0:08
1000001
10007
生成订单
2017/2/3 0:12
用户 ID
事件 ID
事件名称
时间
1000002
10002
登录
2017/2/3 0:01
1000002
10003
搜索产品
2017/2/3 0:03
1000002
10004
浏览产品
2017/2/3 0:08
上面这些事件,有一些事件有必然的前后关系,比如退订商品肯定发生在订单付款之后,订单付款肯定发生在生成订单之后;而收藏商品和加入购物车就不一定谁先谁后了,退订商品前也不一定发生评价商品的事件。这些不稳定性背后隐藏着用户行为,通过对一组有序事件的漏斗分析,就找到了这组行为用户在各个阶段的流失率。这是第一个需求点:事件要顺序发生,且能灵活定义。
第二个需求点是能对事件属性自由定义条件,如 brand=’APPLE’&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2182
2182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









