







一、概述
实际的数据库极易受到噪声、缺失值和不一致数据的侵扰,因为数据库太大,并且多半来自多个异种数据源,低质量的数据将会导致低质量的数据分析结果,大量的数据预处理技术随之产生。本文让我们来看一下数据预处理中常用的数据转换和归一化方法都有哪些。
二、数据转换(Data Transfer)
对于字符型特征的处理:转换为字符型。
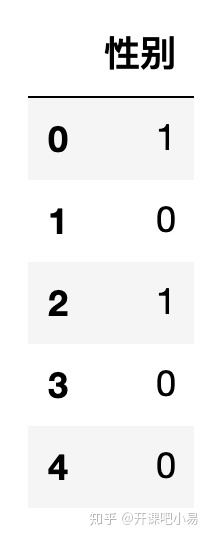
数据转换其实就是把一些字符型数据转换为计算机可以识别的数值型数据的过程,例如我们有性别这个属性,其中有“男”、“女”这两个元素,那我们就可以用数字0代表“男”,1代表“女”。
用python代码来实现一下:
```python
import pandas as pd
data = {'性别' : ['男', '女', '男', '女', '女']}
df = pd.DataFrame(data)
print(df)
```
```python
df[u'性别'] = df[u'性别'].map({'男': 1, '女': 0})
print(df)
```
三、零均值归一化(Z-Score Normalization)
说到零均值归一化,我们就要先来聊聊归一化是什么。
归一化是我们在数据预处理中经常要用到的方法。假设我们通过一个人的身高和体重去判断一个人的胖瘦,有一个人的身高为1.80m体重为80kg,大家都知道胖瘦是由身高和体重共同来决定的,但是此时体重的数值远远大于身高,也就会导致在计算的时候体重被赋予更高的权重,最终导致预测结果不准确,此时我们就会想到把两种属性映射到一个范围内去计算,这种方法就叫做归一化。
了解了归一化,再让我们来了解一下零均值归一化。零均值归一化也叫Z-score规范化(零均值标准化),该方法要求变换后各维特征的均值为0,方差为1,计算方式是将特征值减去均值,再除以标准差。
公式:$z-score = frac{x_i - mu}{sigma}$
**注:我们一般会把train和test放在一起做标准化**
用python代码来实现一下:
```python
from sklearn.preprocessing import StandardScaler, MinMaxScaler
import pandas as pd
views = pd.DataFrame([1295., 25., 1900., 50., 100., 300.], columns=['views'])
print(views)
```
```python
ss = StandardScaler()
views['zscore'] = ss.fit_transform(views[['views']])
```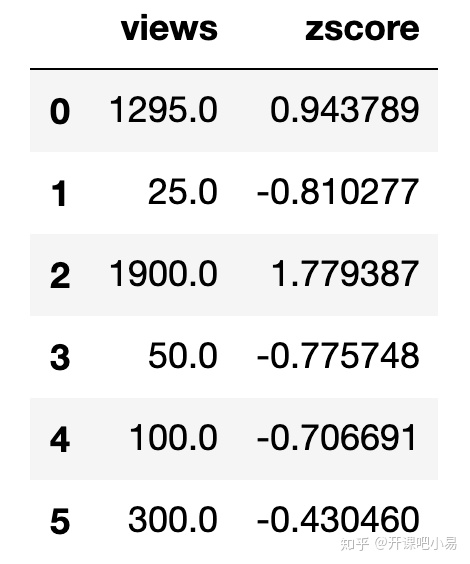
根据结果我们可以看到,属性views被缩放到了很小的范围内,也成功避免了属性值间差异过大的问题。
四、最大最小归一化(Min-Max Scaling)
归一化的另一种常用方法就是最大最小归一化(线性函数归一化),该方法将所有的数据变换到[0,1]区间内。
公式:$frac{x_i - min(x)}{max(x) - min(x)}$
用python代码来实现一下:
```python
mms = MinMaxScaler()
views['minmax'] = mms.fit_transform(views[['views']])
print(views)
```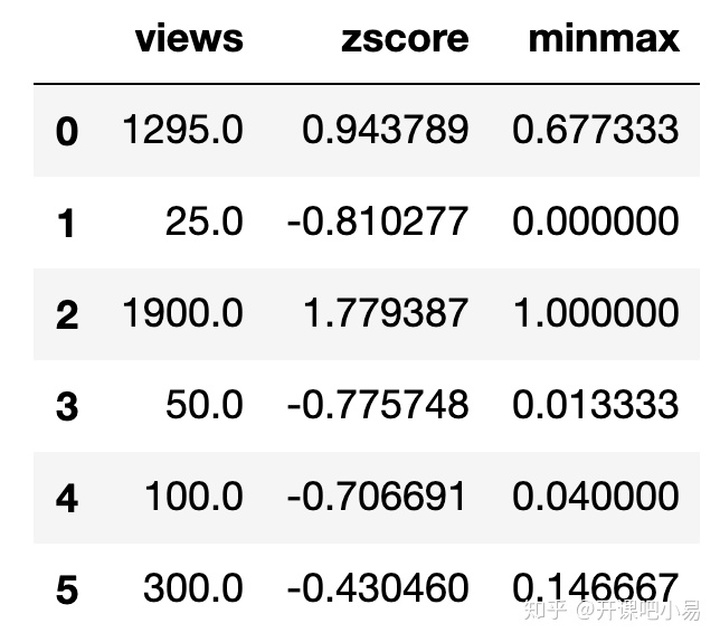
根据结果我们可以看出,最大最小归一化相比于零均值归一化而言映射到了一个更小的空间内
五、为什么要进行归一化
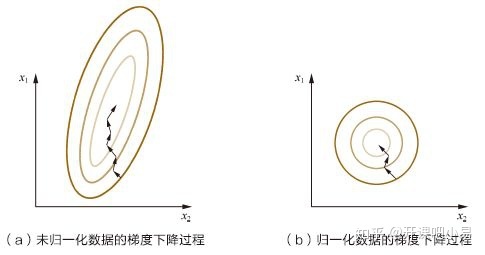
我们不妨从随机梯度下降的角度来思考一下,假设有两种数值型特征,x1的取值范围是[0,100],x2的取值范围是[0,10],我们就可以构造出一个图1中a的图形。当我们的学习速率相同的时候,很明显x1的更新速度会大于x2的更新速度,也就会导致收敛速度变慢,但是当我们把x1和x2归一化到同一个数值空间时,就会变成图1中b的图形,x1和x2的更新速度保持一致,从而加快了收敛速度。
六、小结
1、在实际应用中,通过梯度下降法进行求解的模型通常都是需要进行归一化的,例如:线性回归、逻辑回归、支持向量机、神经网络等。而决策树模型中信息增益与数据是否经过了归一化没有关系,此时是不需要进行归一化的。
2、在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,零均值归一化表现的更好。
3、在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用最大最小归一化或其他归一化方法。














 725
725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









