






空间和时间之间的转换无非就两种方式即:时间换空间,空间换时间。
当年蒋介石就完成过空间换时间,以大量的土地换取自己喘息的时间。
在实际开发中时间 = 运行时间,空间 = 运行内存,所以空间和时间的转换其实也就是运行时间和内存之间的占比。在时间运行中如何将两者的关系处理好就能提升系统的运行速度。时间换空间就是执行那些复杂的程序的时候需要消耗很大的内存,我们就需要把程序拆分成不同模块执行利用时间来降低内存的消耗,反之亦然。
在程序开发过程中,我们对于数据的处理,会有一些校验。
校验分为两种:简单校验和复杂校验。
对于一些简单的校验,如用户是否存在,密码是否正确等等。这种校验,可以说几乎不耗时的。所以也没必要在这里做优化。
对于复杂的校验,需要进行联合查询,通过查询很多次之后,才可以得出 数据的正确性与否。当然这种校验执行会很慢。
对于程序开发来说,时间复杂度和空间复杂度是可以相互转化的。说通俗一点,就是:对于执行的慢的程序,可以通过消耗内存(即构造新的数据结构)来进行优化。而消耗内存的程序,也可以多消耗时间来降低内存的消耗。
前者使用的是最多的。很少有人会为了节省内存而浪费时间。感兴趣的同学,请仔细看完这个例子。看如何是如何消耗内存来提高性能的。如果有不正确的地方,还请指出来。
先举例一个场景。来分别 看一下 正常思路的处理方法和优化过后的处理方法:
比如说给学生 排课。学生 和 课程 是一个多对多的关系。

按照正常的逻辑 应该有一个关联表来维护 两者之间的关系。
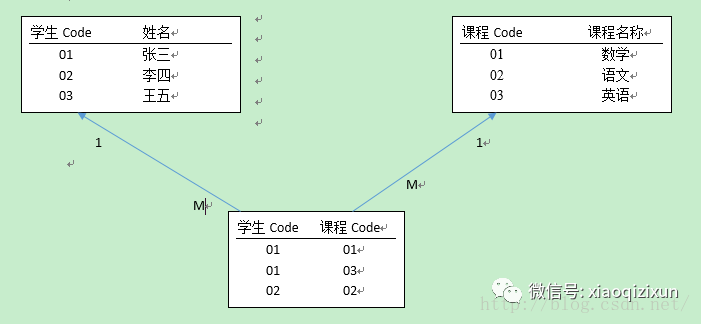
现在,添加一个约束条件 用于 校验。如:张三 上学期 学过 的课程,在排课的时候不应该再排这种课程。
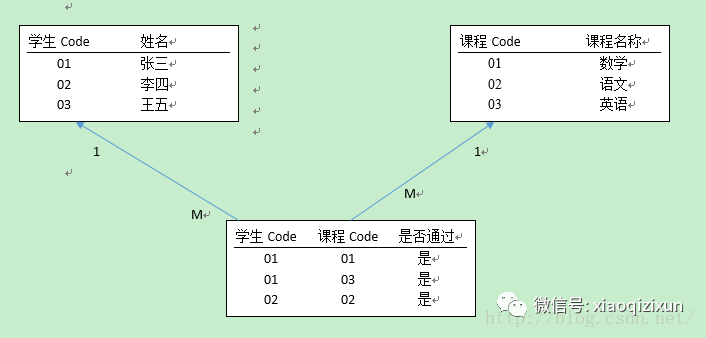
所以需要出现一个约束表(即:历史成绩表)。
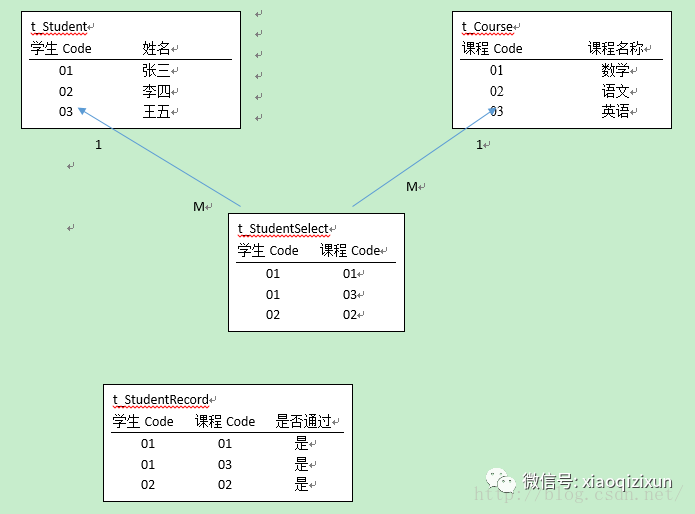
即:学生选课表,需要 学生成绩表作为约束。
处理方式对比
方案一:正常的处理方式:
当一个学生进行再次选课的时候。需要查询学生选课表看是否已经存在。
即有如下校验:
//查询 学生code和课程code分别为 A 和 B的数据是否存在//list集合中存放 学生选课记录全部的数据List ListStudentRecord=service.findAll();//查询数据,看是否已经存在StudentRecordEntity enSr=ListStudentRecord.find(s=>s.学生Code==A && s.课程Code==B);If(enSr==null){//学生没有选该课程//....}else{//学生已经选过该课程//....}
对于上面这种代码的写法,非常的简练。而且也非常易懂。
首先,假设有5000个学生,100门课程。那么对于学生选课的数据集中,数据量将是5000*100.数据量会是十万级别的数量级。
在十万条数据中,查询 学生=A 课程=B的 一条记录。执行的效率会很低。因为find方法的查询也就是where 查询,即通过遍历数据集合 来查找。
所以,使用上面的代码。在数据量逐渐增长的过程中,程序的执行效率会大幅度下降。
(ps:数据量增长,在该例子中并不太适合。例子可能不太恰当。总之,大概就是这个意思。)
方案二:使用内存进行优化效率:
这种做法,需要消耗内存。或者说把校验的工作向前做(数据的初始化,在部署系统的过程中进行)。即:在页面加载的时候数据只调用提供的public方法进行校验。
//学生Code 到 数组索引Private Dictionary _DicStudentCodeToArrayIndex;//课程Code 到 数据索引Private Dictionary _DicCourseCodeToArrayIndex;//所有学生List ListStudent=service.findAllStudent();//所有课程List ListCourse=service.findAllCourse();//所有 学生选课记录List ListStudentRecord=service.finAll();Private int[,] _ConnStudentRecord=new int[ListStudent.count,ListCourse.count];//构造 学生、课程的 数组 用于快速查找字典索引Private void GenerateDic(){For(int i=0;i_DicStudentCodeToArrayIndex.Add(ListStudent[i].code,i)}For(int i=0;i_DicCourseCodeToArrayIndex.Add(ListCourse[i].code,i)}}//构造学生选课 匹配的 二维数组。1表示 学生已选该课程Private void GenerateArray(){Foreach(StudentRecordEntity sre in ListStudentRecord){Int x=_DicStudentCodeToArrayIndex[sre.学生Code];Int y=DicCourseCodeToArrayIndex[sre.课程Code];ConnStudentRecord[x,y]=1;}}//对外公开的方法:根据学生Code 和课程Code 查询 选课记录是否存在/// 返回1 表示存在。返回0表示不存在Public void VerifyRecordByStudentCodeAndCourseCode(String pStudentCode,String pCourseCode){Int x=_DicStudentCodeToArrayIndex[pStudentCode];Int y=_DicCourseCodeToArrayIndex[pCourseCode];Return ConnStudentRecord[x,y];}
性能分析
分析一下第二种方案的表象。
1、方法很多。
2、使用的变量很多。
首先要说一下。该优化的目的,是提高 学生在选课的时候,所出现的卡顿现象(校验数据量大)。
分别对以上两种方案进行分析:
假设学生为N,课程为M
第一种方案:
时间复杂度很容易计算 第一种方案最小为O(NM)
第二种方案:
1、代码多。但是给用户提供的只有一个VerifyRecordByStudentCodeAndCourseCode方法。
2、变量多,因为该方案就是要使用内存提高效率的。
这个方法执行流程:1、在Dictionary中使用Code找Index 2、使用Index查询数组。
第一步中,Dictionary中查询是使用的Hash查找算法。时间复杂度为O(lgN) 时间比较快。第二步,时间复杂度为O(1),因为数组 是连续的 使用索引 会直接查找对应的地址。
所以,使用第二种方案进行校验,第二种方案时间复杂度为O(lgN+lgM)















 971
971











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









