






在用R进行CEL文件的RMA标准化时,突然遇到一个报错,如下:
Error in getCdfInfo(object) :
Could not obtain CDF environment, problems encountered:
Specified environment does not contain BovGene-1_0-v1
Library - package bovgene10v1cdf not installed
Bioconductor - bovgene10v1cdf not available这个问题卡了我好久,总算解决了,给大家分享一下,共同进步。(but,我又遇到了新的问题,小白太难了……)
方法一:
下载“RMAExpress”软件,操作简单,导入cel文件和cdf文件,输出即可
方法二:
使用R,先把cdf文件转化为包,(cdf文件是下载CEL文件时自带的,如果没有的话可以去平台文件找找)
make.cdf.package("BovGene-1_0-v1.cdf.gz", species = "Bos taurus", compress = TRUE)然后在Windows系统下运行cmd(win+R,弹出的框框输入cmd),使用R CMD INSTALL将上一步制作好的包导入R:
cd C:Program FilesRR-4.0.3bin #进入R的文件夹
R CMD INSTALL I:0GSEcelbovgene10v1cdf #导入刚建好的包ok。解决,这时候就可以进行RMA标准化了。顺便贴个代码
Data<-ReadAffy()
sampleNames(Data)
#用RMA预处理数据
eset.rma<-rma(Data)
#获取表达数据并输出到表格
exprs<-exprs(eset.rma)
probeid<-rownames(exprs)
exprs<-cbind(probeid,exprs)
write.table(exprs,file="expres.txt",sep='t',quote=F,row.names=F)这样就得到了标准化的矩阵,结果如下图二,两种方法的结果是一样的。
问题出现了,得到的矩阵第一列不是探针id,更不是基因id,不知道是什么……
而且矩阵的行数是GPL平台文件行数的8倍还多一点……………………
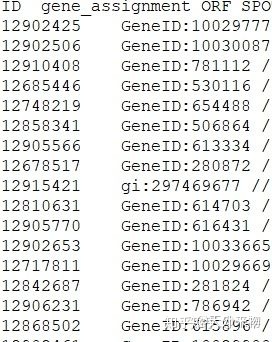
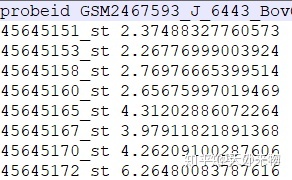
问题尚未解决,小白仍需努力。欢迎大佬莅临指导


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









