







堆的预备知识
堆是一个完全二叉树。
完全二叉树:二叉树除开最后一层,其他层结点数都达到最大,最后一层的所有结点都集中在左边(左边结点排列满的情况下,右边才能缺失结点)。
大顶堆:根结点为最大值,每个结点的值大于或等于其孩子结点的值。
小顶堆:根结点为最小值,每个结点的值小于或等于其孩子结点的值。
堆的存储:堆由数组来实现,相当于对二叉树做层序遍历。如下图:


对于结点 i ,其子结点为 2i+1 与 2i+2 。
堆排序算法

现在需要对如上二叉树做升序排序,总共分为三步:
将初始二叉树转化为大顶堆(heapify),此时根结点为最大值,将其与最后一个结点交换。
除开最后一个结点,将其余节点组成的新堆转化为大顶堆,此时根结点为次最大值,将其与最后一个结点交换。
重复步骤2,直到堆中元素个数为1(或其对应数组的长度为1),排序完成。
下面详细图解这个过程:
步骤1:
初始化大顶堆,首先选取最后一个非叶子结点(我们只需要调整父节点和孩子节点之间的大小关系,叶子结点之间的大小关系无需调整)。设数组为arr,则第一个非叶子结点的下标为:i = Math.floor(arr.length/2 - 1) = 1,也就是数字4,如图中虚线框,找到三个数字的最大值,与父节点交换。

然后,下标 i 依次减1(即从第一个非叶子结点开始,从右至左,从下至上遍历所有非叶子节点)。后面的每一次调整都是如此:找到父子结点中的最大值,做交换。
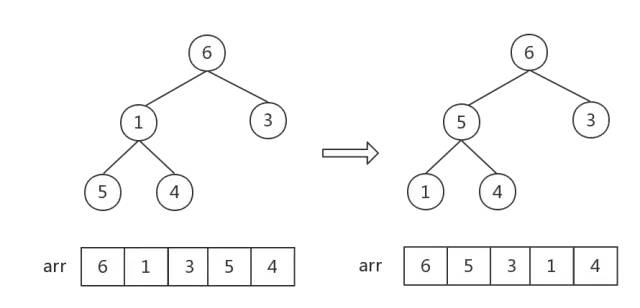
这一步中数字6、1交换后,数字[1,5,4]组成的堆顺序不对,需要执行一步调整。因此需要注意,每一次对一个非叶子结点做调整后,都要观察是否会影响子堆顺序!
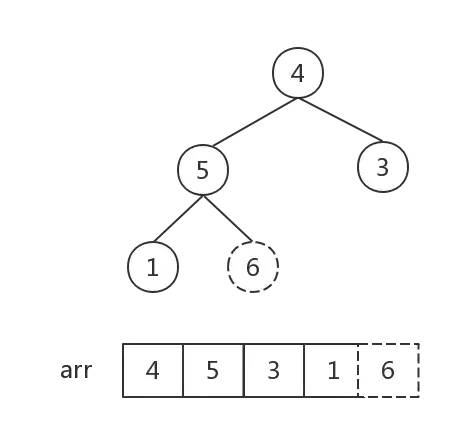
根节点与最后一个结点交换
这次调整后,根节点为最大值,形成了一个大顶堆,将根节点与最后一个结点交换。
步骤2:
除开当前最后一个结点6(即最大值),将其余结点[4,5,3,1]组成新堆转化为大顶堆(注意观察,此时根节点以外的其他结点,都满足大顶堆的特征,所以可以从根节点4开始调整,即找到4应该处于的位置即可)。


根节点与最后一个结点交换
步骤3:
接下来反复执行步骤2,直到堆中元素个数为1:

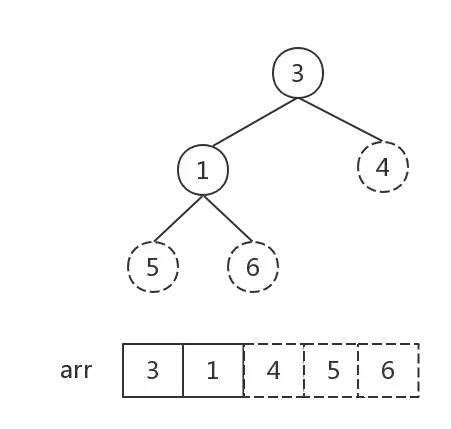
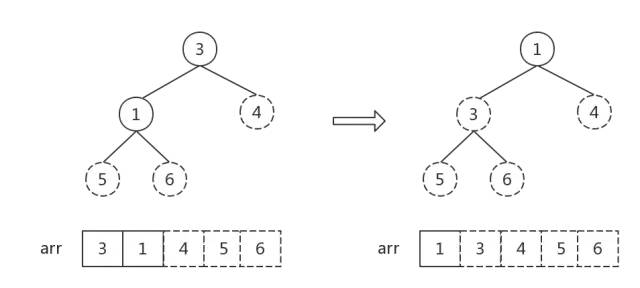
堆中元素个数为1, 排序完成。
JavaScript实现
// 交换两个节点function swap(A, i, j) { let temp = A[i]; A[i] = A[j]; A[j] = temp; }// 将 i 结点以下的堆整理为大顶堆,注意这一步实现的基础实际上是:// 假设 结点 i 以下的子堆已经是一个大顶堆,adjustheap 函数实现的// 功能是实际上是:找到 结点 i 在包括结点 i 的堆中的正确位置。后面// 将写一个 for 循环,从第一个非叶子结点开始,对每一个非叶子结点// 都执行 adjustheap 操作,所以就满足了结点 i 以下的子堆已经是一大//顶堆function adjustHeap(A, i, length) { let temp = A[i]; // 当前父节点// j for(let j = 2*i+1; j2*j+ temp = A[i]; // 将 A[i] 取出,整个过程相当于找到 A[i] 应处于的位置 if(j+1 < length && A[j] < A[j+1]) { j++; // 找到两个孩子中较大的一个,再与父节点比较 } if(temp < A[j]) { swap(A, i, j) // 如果父节点小于子节点:交换;否则跳出 i = j; // 交换后,temp 的下标变为 j } else { break; } }}// 堆排序function heapSort(A) { // 初始化大顶堆,从第一个非叶子结点开始 for(let i = Math.floor(A.length/2-1); i>=0; i--) { adjustHeap(A, i, A.length); } // 排序,每一次for循环找出一个当前最大值,数组长度减一 for(let i = Math.floor(A.length-1); i>0; i--) { swap(A, 0, i); // 根节点与最后一个节点交换 adjustHeap(A, 0, i); // 从根节点开始调整,并且最后一个结点已经为当 // 前最大值,不需要再参与比较,所以第三个参数 // 为 i,即比较到最后一个结点前一个即可 }}let Arr = [4, 6, 8, 5, 9, 1, 2, 5, 3, 2];heapSort(Arr);alert(Arr);程序注释:将 i 结点以下的堆整理为大顶堆,注意这一步实现的基础实际上是:假设 结点 i 以下的子堆已经是一个大顶堆,adjustHeap 函数实现的功能是实际上是:找到 结点 i 在包括结点 i 的堆中的正确位置。后面做第一次堆化时,heapSort 中写了一个 for 循环,从第一个非叶子结点开始,对每一个非叶子结点都执行 adjustHeap 操作,所以就满足了每一次 adjustHeap 中,结点 i 以下的子堆已经是一大顶堆。
复杂度分析:adjustHeap 函数中相当于堆的每一层只遍历一个结点,因为
具有n个结点的完全二叉树的深度为[log2n]+1,所以 adjustHeap 的复杂度为 O(logn),而外层循环共有 f(n) 次,所以最终的复杂度为 O(nlogn)。
堆的应用
堆主要是用来实现优先队列,下面是优先队列的应用示例:
操作系统动态选择优先级最高的任务执行。
静态问题中,在N个元素中选出前M名,使用排序的复杂度:O(NlogN),使用优先队列的复杂度: O(NlogM)。
而实现优先队列采用普通数组、顺序数组和堆的不同复杂度如下:
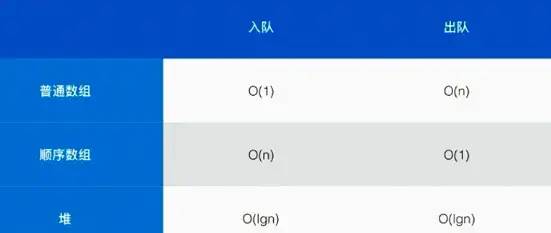
使用堆来实现优先队列,可以使入队和出队的复杂度都很低。
作者:Leondt
链接:https://www.jianshu.com/p/90bf2dcd6a7b
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









