






I am new to Python and OpenCV . I am currently working on OCR using Python and OpenCV without using Tesseract.Till now I have been successful in detecting the text (character and digit) but I am encountering a problem to detect space between words.
Eg-
If the image says "Hello John", then it detects hello john but cannot detect space between them, so my output is "HelloJohn" without any space between them.My code for extracting contour goes like this(I have imported all the required modules, this one is the main module extracting contour) :
imgGray = cv2.cvtColor(imgTrainingNumbers, cv2.COLOR_BGR2GRAY)
imgBlurred = cv2.GaussianBlur(imgGray, (5,5), 0)
imgThresh = cv2.adaptiveThreshold(imgBlurred,
255,
cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY_INV,
11,
2)
cv2.imshow("imgThresh", imgThresh)
imgThreshCopy = imgThresh.copy()
imgContours, npaContours, npaHierarchy = cv2.findContours(imgThreshCopy,
cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
After this I classify the extracted contours which are digits and character.
Please help me detecting space between them.
Thank You in advance,your reply would be really helpful.
解决方案
Since you did not give any example images, I just generated a simple image to test with:
h, w = 100, 600
img = np.zeros((h, w), dtype=np.uint8)
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img, 'OCR with OpenCV', (30, h-30), font, 2, 255, 2, cv2.LINE_AA)
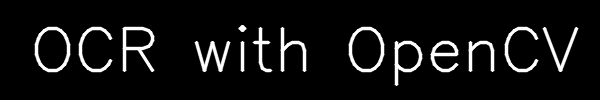
As I mentioned in the comments, if you simply dilate the image, then the white areas will expand. If you do this with a large enough kernel so that nearby letters merge, but small enough that separate words do not, then you'll be able to extract contours of each word and use that to mask one word at a time for OCR purposes.
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (15, 15))
dilated = cv2.dilate(img, kernel)

To get the mask of each word individually, just find the contours of these larger blobs. You can sort the contours too; vertically, horizontally, or both so that you get the words in proper order. Here since I just have a single line I'll sort just in the x direction:
contours = cv2.findContours(dilated, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)[1]
contours = sorted(contours, key=lambda c: min(min(c[:, :, 0])))
for i in range(len(contours)):
mask = np.zeros((h, w), dtype=np.uint8)
# i is the contour to draw, -1 means fill the contours
mask = cv2.drawContours(mask, contours, i, 255, -1)
masked_img = cv2.bitwise_and(img, img, mask=mask)
cv2.imshow('Masked single word', masked_img)
cv2.waitKey()
# do your OCR here on the masked image


















 508
508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









