






> 总结ES基本原理。
> 学习时长评估:3小时。
[TOC]
# 基本描述
NRT:Near Real Time,准实时,延迟1秒。
刷新间隔:refresh_interval,默认1秒。
分片:设置好了不能改,考虑到后期扩容,所以一般设置N < Shard < 2N。
副本:根据业务自行选择,一般2~3。
# 分页查询
from+size:默认限制不能大于1W。
[分页查询From&Size VS scroll](https://www.cnblogs.com/xing901022/p/5284902.html)
[深度分页scroll使用方式](https://www.jianshu.com/p/32f4d276d433)
**建议**:
预先在业务上探讨这么做的必要性,并告知会消耗大量资源,以及可能的查询速度变慢问题。
# 为什么ES查询比MySQL快
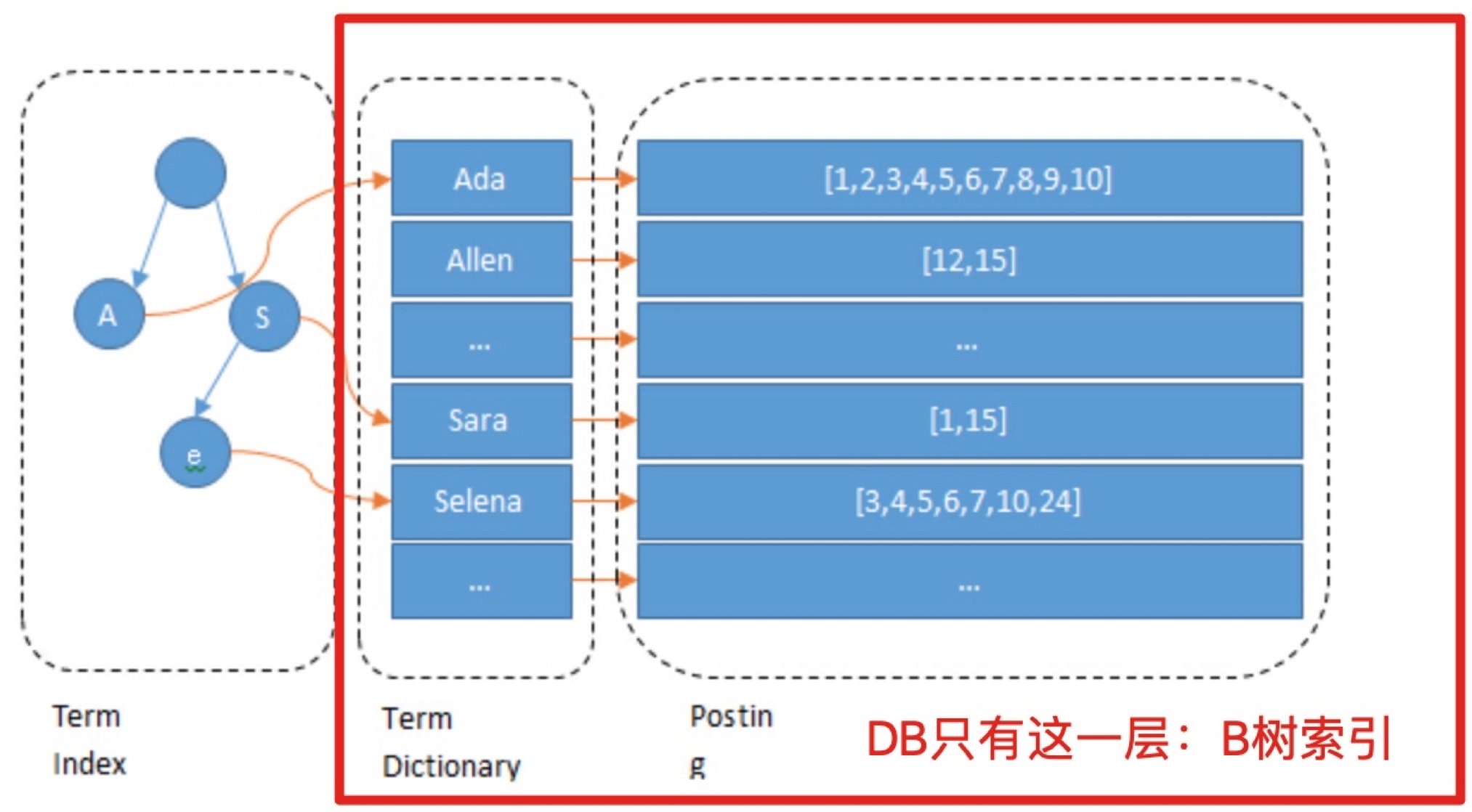
上图中的Term,翻译成词,是索引的最小单位,是经过词法分词和语言处理后的字符串。
上图中的Term Dictionary->Posting List,可以类比数据库的B树,而Term Index是一颗Trie树(字典树,单词查找树),是经过压缩放在内存中的,Term Dictionary如果太大,内存放不下,但是Term Index一定放得下。
**索引方面:**
数据库只有一层B+树索引(Term Dictionary),检索一个term需要若干次的磁盘检索操作;
倒排索引,有在Term Dictionary基础之上的,内存中的Term Index,Term内存检索完毕,直接就到数据所在硬盘块,磁盘访问少,自然快。
**多个维度检索的时候:**
数据库多数情况只能用一个索引,然后内存过滤其他条件;ES是同时利用多个Term Index,找到多个Posting List,然后利用Skip List或者bitset与出来。
**参考:**
[如何快速检索](https://www.infoq.cn/article/database-timestamp-02)
[索引原理分析](https://www.cnblogs.com/dreamroute/p/8484457.html)
[分布式架构及底层原理](https://segmentfault.com/a/1190000015256970)
# 存储底层原理
## 写入底层原理
data->translog(5秒或者一次写操作之后,fsync到硬盘)->commit到硬盘(30分钟或者translog过大)
data->buffer(1秒一次refresh)->os cache(可以被检索)->内存segment file(1秒一次)
tangslog的目的是确保操作记录不丢失,那么问题就来了,tangslog有多可靠?
默认情况下,translog会每隔5秒或者在一个写请求(index,delete,update,bulk)完成之后执行一次fsync操作,这个进程会在所有的主shard和副本shard上执行。 这个守护进程的操作在客户端是不会收到200 ok的请求。
**参考:**
[如何保证数据不丢失](https://blog.csdn.net/u010454030/article/details/79617468)
## 段
核心概念:refresh/flush/translog/merge.
写入磁盘的倒排索引是不可变的。
下一个需要解决的问题是如何在保持不可变好处的同时更新倒排索引。答案是,使用多个索引。
不是重写整个倒排索引,而是增加额外的索引反映最近的变化。每个倒排索引都可以按顺序查询,从最老的开始,最后把结果聚合。
Elasticsearch底层依赖的Lucene,引入了per-segment search的概念。一个段(segment)是有完整功能的倒排索引,但是现在Lucene中的索引指的是段的集合,再加上提交点(commit point,包括所有段的文件)。
## 段合并
通过每秒自动刷新创建新的段,用不了多久段的数量就爆炸了。
有太多的段是一个问题。每个段消费文件句柄,内存,cpu资源。
更重要的是,每次搜索请求都需要依次检查每个段。
段越多,查询越慢。
ES通过后台合并段解决这个问题。小段被合并成大段,再合并成更大的段。
这是旧的文档从文件系统删除的时候。旧的段不会再复制到更大的新段中。
这个过程你不必做什么。当你在索引和搜索时ES会自动处理。
**参考:**
[深入分片](https://juejin.im/post/5b7e2a2c51882543113d80cc)
## ES分片要求
ES一般要求一个集群最多到1万个分片,否则对master机器的内存和计算带来很大压力。
# 索引优化思考和总结
将磁盘里的东西尽量搬进内存,减少磁盘随机读取次数(同时也利用磁盘顺序读特性),结合各种奇技淫巧的压缩算法,用极其苛刻的态度使用内存。
**对于使用Elasticsearch进行索引时需要注意:**
不需要索引的字段,一定要明确定义出来,因为默认是自动建索引的
同样的道理,对于String类型的字段,不需要analysis的也需要明确定义出来,因为默认也是会analysis的
选择有规律的ID很重要,随机性太大的ID(比如java的UUID)不利于查询















 713
713











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









