







最近项目上用到了Kafka(作为数据源接入),这里将自己的实践分享出来,供大家参考或针砭。
从网上查阅资料发现,基本上有2中与Kafka对接的方式:
1.Spring-Kafka2.调用Kafka API自己实现ConsumerClient
Spring-Kafka的基本原理就是Spring自动轮询Poll数据,通过监听器MessageListener.onMessage()向用户自定义的消费入口(@KafkaListener)推送数据。因此对于用户来说,仅需要关注自己的业务实现即可,Kafka数据对于业务来说就是一个方法的入参而已。这种设计很有意思,因为Kafka是不支持主动Push的,但是Spring-Kafka自己实现了这种角色反转。Spring-Kafka本身就是一个很好的实现,而且上手相对简单,推荐大家使用这种方式。
温馨提示:Spring-Kafka和kafka-clients之间有版本的兼容性问题需特别注意,另外如果你使用SpringBoot开发的话也需要匹配特定的版本。


#Spring-Kafka KafkaConsumer消费模型(来源于网络)
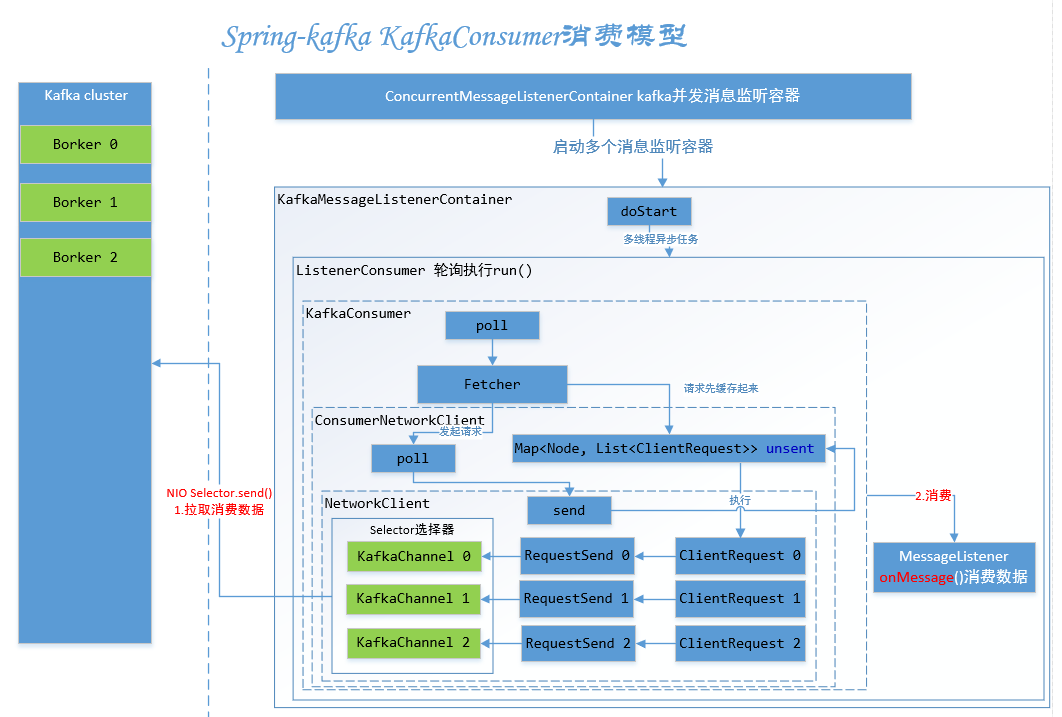
不过抱着学习研究的目的,本篇选择第2中实现方式,其实和Spring-Kafka殊途同归。
直奔主题,本篇就不阐述太多理论性的东西,仅介绍一些基本的Kafka API对象和概念:
1.KafkaConsumer,顾名思义就是Kafka的数据消费者,其主要作用是连接Kafka订阅(subscribe)相关主题(topic)并拉取(poll)数据并提交消费偏移(offset)。2.Con
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1701
1701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









