






1.列的离散性
你知道吗?即使你对数据库中你要查询的列添加了索引,它也有可能不会走索引。 这其实和一个叫 列的离散性 相关的问题。在数据库表中,MySQL 在查询时,会对表中查询的列进行离散性计算。计算出的离散性结果越大,说明这一列的离散型越好,选择性就越好。 列的离散性计算公式为:count(distinct col) : count(col)。
我们来计算一下下图三列的离散性:
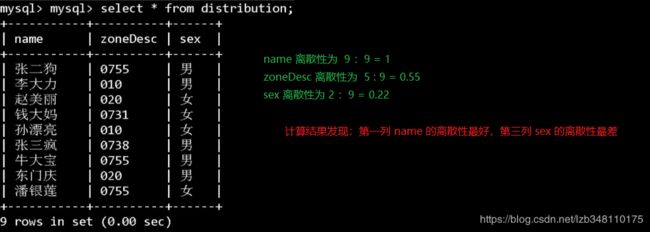
为什么说:离散性越好,选择性就越好呢?
我们将上图 sex 列进行 B+Tree 二叉树转换(男:0 女:1)。附:提供一个很好用的国外数据结构模拟网站:我是链接。转换后的二叉树如下图所示:
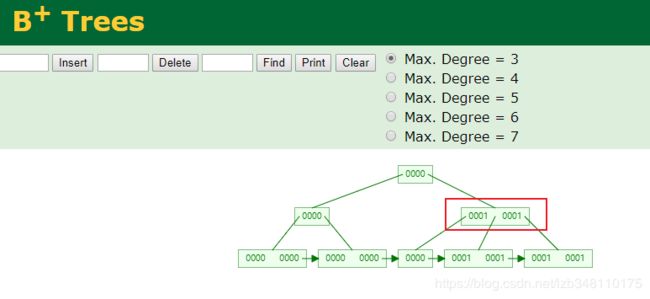
比如:现在我们要查询性别为女的用户。会取1进行层层比对。当做到上图中标红节点时,发现左中右哪一路都可以走,选择性更多了。MySQL 查询优化器会认为搜寻这么多的数据,离散性这么差,可选择性也很差,选择优化器认为还不如用全表扫描呢。
离散性越高,选择性就会越好,查询效率显然也会越高,索引的存在也就起到了作用。
记住这个值:【10%-15%】:
离散性在不超过全表的【10%-15%】的前提下索引才可以显示其所具有的价值。当离散度超过该值的情况下全表扫描可能反倒比索引扫描更有效。我们所追求的目标就是创建全表扫描所无法比拟的有效索引。
2.最左匹配原则
当我们在创建数据库时,会同步选择字符集、排序规则这些选项。

针对排序规则,此处你或许会有一个误区:并不是只有数字类型可以排序,字符串等也是可以排序的。比如说现在数据库表有一个 name 字段,并且我们对该字段创建了一个name索引。该字段存在这些数据:abc 、kut 、abg 、 oop,将这些数据转换为二叉树类似下图所示(MySQL使用的是B+Tree作为索引。此处为了演示,下图并未使用B+Tree)
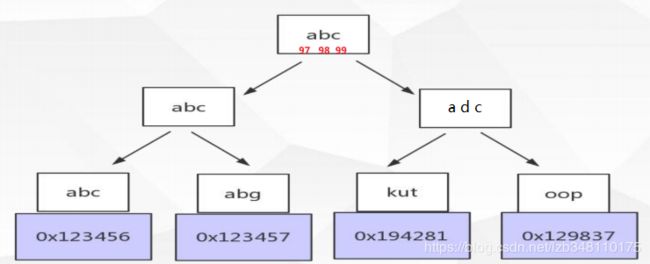
最左匹配原则,会对索引中的关键字进行计算(对比),一定是从左到右依次进行,且不可跳过。我们就以 adc这个名字为例查询。根据规则我们比如计算出 abc 的 ascii 码为 a=97,b=98,c=99;adc 的 ascii 码为 a=97,d=100,c=99;
根据最左匹配原则,搜索 adc时,会对关键字一个一个进行对比。第一个关键字发现 97 = 97;便会继续对第二个关键字比较,发现 100 > 98,则会去右节点进行查找。这就是所谓的最左匹配原则。
英文、字符串、中文 等,都是可以用来被对比的。具体如何对比,这就取决于你在创建数据库、创建表时,选择的是怎样的一个排序规则了。
3.联合索引
为了提高数据库效率,建索引是家常便饭;那么当查询条件为2个及以上时,此时我们就用到了联合索引的概念了。切记:联合索引 ≠ 两个索引,它也是一个索引
单列索引:
比如有一个 name 单列索引,即索引关键字只有一个 [name]
联合索引:
比如有一个 name、mobileNo 联合索引,那么索引关键字就是 [name,mobileNo]
你可以理解为:单列索引,是一个特殊的联合索引。
联合索引列选择原则:
经常用于查询的列优先;【最左匹配原则】
离散性高的列优先(选择性更高,效率更好);【离散性原则】
宽度小的列优先。【最少空间原则】
来个小测试:
有如下两条查询语句:
select * from user where name = xxx;
select * from user where name = xxx and mobileNo = xxx;
我们如果创建一个 name单列索引、再来一个name、mobileNo联合索引。虽然没有任何问题,但是通过最左匹配原则,我们就可以理解 name单列索引在此处其实是一个冗余的索引。
好文附上:什么时候走单列索引,什么时候走联合索引,以及它们的关联区别,请参考:多个单列索引和联合索引的区别详解
4.覆盖索引
联合索引的存在,就引出了覆盖索引的概念。
如果查询列可通过索引节点中的关键字直接返回,则该索引就称之为覆盖索引。覆盖索引的出现,可减少数据库的 I/O 操作,将随机 I/O 变为 顺序 I/O,从而提高查询性能。
示例:
现在有一个 [name,mobileNo] 联合索引,如果我们通过以下语句来查询:select name,mobileNo from user where name = xxx。它会直接命中索引,直接从索引的结构中将数据返回,而不再需要遍历到叶子节点去获取数据,从而大大提高查询效率。
select name,mobileNo from user where name = xxx and mobileNo =xxx;这种语句也可以直接命中覆盖索引,并直接返回数据。
select name,mobileNo from user where name = xxx and age=xx;这种语句就不会命中覆盖索引了。因为它即使命中了 name 字段的索引,但是并没有命中 age 字段的索引,所以他不会命中覆盖索引。
索引相关总结
索引列的数据长度能少则少;
索引一定不是越多越好,越全越好,一定是建合适的;
匹配列前缀可用到索引 like 9999%,like %9999%、like %9999用不到索引;
注意: like 9999% 并不会一定用到索引(离散型太差,就不会用到索引)
like %9999%、like %9999 是绝对不会用到索引的
Where 条件中 not in 和 <>操作无法使用索引;
匹配范围值,order by 也可用到索引;
多用指定列查询,只返回自己想到的数据列,少用select *;
联合索引中如果不是按照索引最左列开始查找,无法使用索引;
联合索引中精确匹配最左前列并范围匹配另外一列可以用到索引;
比如说:有个[name,phone]联合索引
where name=‘abc’ and phone>‘136xxxxxxxx’ 这种是可以用到索引的
联合索引中,如果查询中有某个列的范围查询,则其右边的所有列都无法使用索引;
比如说:有个[age,name]联合索引
where age>18 and name='abc’这是用不到索引的
它只会age使用索引,name不会使用索引。还是基于最左匹配原则
MySQL 同系列文章,请参考:
了解MySQL体系结构
一文带你看懂 MySQL 存储引擎
还不了解 MyISAM 和 InnoDB 的区别?看这里就够了
MySQL为什么没有走索引?是这些原因在搞鬼
一条SQL语句的坎坷之旅(MySQL底层执行流程分析)
不会MySQL调优?来来瞅瞅SQL的执行计划吧
InnoDB 事务与锁的前世今生
一文带你了解 InnoDB 中的 MVCC、Undo、Redo 机制
博主写作不易,加个关注呗
求关注、求点赞,加个关注不迷路 ヾ(◍°∇°◍)ノ゙
博主不能保证写的所有知识点都正确,但是能保证纯手敲,错误也请指出,望轻喷 Thanks♪(・ω・)ノ















 1250
1250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









