








有这样一个场景,我们用Flink来对数据进行简单的ETL,然后将清洗过的数据按照数据中的某一个字段写入指定的topic中,Flink官方给我们提供的有flink-connetor-kafka接口,但是官方提供的FlinkKafkaProducer构造的时候都需要指定数据要写入的kafka topic,也就是说这个topic是固定的,显然不满足我们的需求。
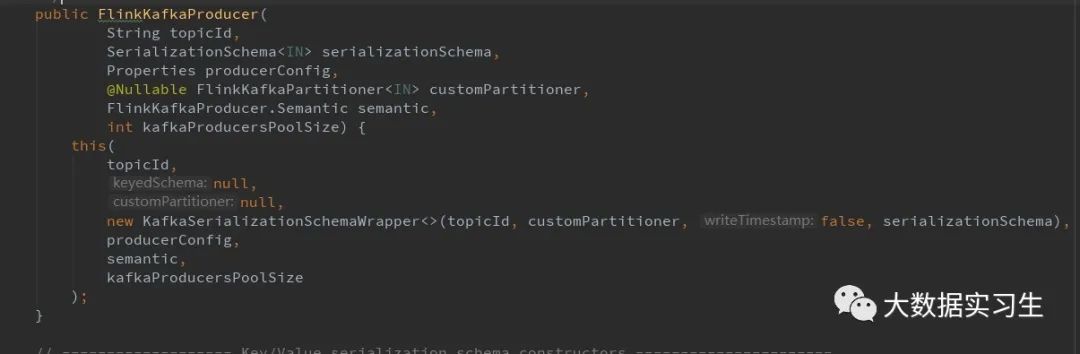
如图,FlinkKafkaProducer构造器之一:
这里有两种方法可以满足我们的需求:
自己写一个SinkFunction,然后写我们的逻辑
自定义KafkaSerializationSchema,并使用官方的connector
第一种方法比较简单直接,但是写代码麻烦,我们直接说第二种使用起来更简洁的方法:
我们注意到FlinkKafkaProducer有这样一个构造器,其中一个参数是KafkaSerializationSchema,这个参数定义了
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5943
5943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









