






阅读文本大概需要6分钟。
上篇分析的网站是国家级,没有真正编写代码爬取对应的数据,今天以“1药网”为例来爬一爬药品数据
https://www.111.com.cn/
1、分析网站
进入网站首页

2、点击一下“所有商品分类”,对应的网站地址如下
https://www.111.com.cn/categories/
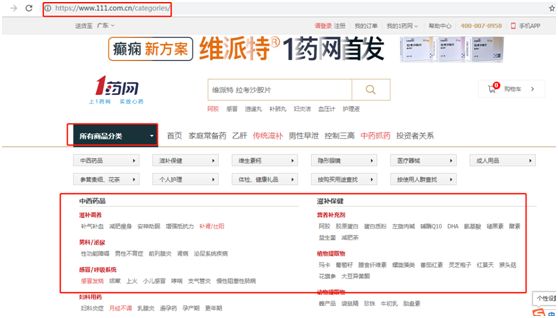
先爬取所有的“分类”,然后在根据“分类”获取分类下的所有商品。
发起Get请求的方法
public staticStringsendGet(String url){
String result =null;//CreatesCloseableHttpClient instance with default configuration.CloseableHttpClienthttpCilent = HttpClients.createDefault();HttpGethttpGet =newHttpGet(url);
try{
CloseableHttpResponse response =httpCilent.execute(httpGet);Stringresult = EntityUtils.toString(response.getEntity());System.out.println(result);}catch(IOException e) {
e.printStackTrace();}finally{try{
httpCilent.close();//释放资源}catch(IOException e) {
e.printStackTrace();}
}returnresult;}
获取“药品分类”的HTML页面
public staticStringgetCategories(){
String html = HttpUtils.sendGet("https://www.111.com.cn/categories/");
returnhtml;}
3、分析爬取到的药品分类的HTML,认真看图
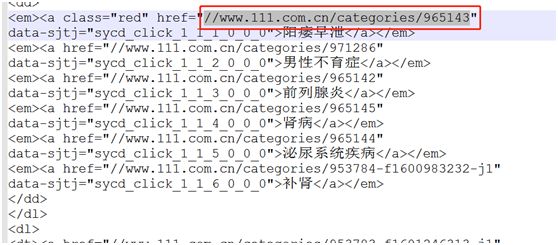
把界面上所有的分类链接解析出来
4、解析所有分类链接
5、public staticListprocessCategoriesHtml(String html){
List links =newArrayList();
if(html!=null&& !"".equals(html.trim())){try{
Parser parser =newParser(html);//定义一个Filter,过滤主题aNodeFilter afilter =newNodeClassFilter(LinkTag.class);//A过滤器NodeList nodeList = parser.extractAllNodesThatMatch(afilter);
for(inti=0;i
Node aNode = nodeList.elementAt(i);LinkTag aLinkTag = (LinkTag)aNode;
if(aLinkTag.getLink()!=null&& aLinkTag.getLink().contains("categories")){
links.add(aLinkTag.getLink());System.out.println(aLinkTag.getLink());}
}
}catch(Exception e){
e.printStackTrace();}
}returnlinks;}
6、下面来看看“杜蕾斯”的兄弟没到底有多少
在第五步爬出来的连接有如下
//www.111.com.cn/categories/965327-j1
一个连接,同样先爬取HTML页面
public staticStringgetDLS_Html(){
String html = HttpUtils.sendGet("https://www.111.com.cn/categories/965327-j1");
returnhtml;}
分析获取到HTML

每个“杜大哥”的连接都有product和class="product_pic pro_img"。用如下代码即可获取所有的“杜蕾斯”兄弟的商品链接
public staticListprocessDLSHtml(String html){
List links =newArrayList();
if(html!=null&& !"".equals(html.trim())){try{
Parser parser =newParser(html);//定义一个Filter,过滤主题emNodeFilter afilter =newNodeClassFilter(LinkTag.class);//A过滤器NodeList nodeList = parser.extractAllNodesThatMatch(afilter);
for(inti=0;i
Node aNode = nodeList.elementAt(i);LinkTag aLinkTag = (LinkTag)aNode;
if(aLinkTag.getLink()!=null&& aLinkTag.getLink().contains("product")){
links.add(aLinkTag.getLink());System.out.println(aLinkTag.getLink());}
}
}catch(Exception e){
e.printStackTrace();}
}returnlinks;}
7、接下来就可以获取所有的商品规格了,哪款卖的多都可以分析出来哦
同样先获取页面详情
public staticStringgetDLSDetail_Html(String url){
String html = HttpUtils.sendGet("https:"+url);
returnhtml;}
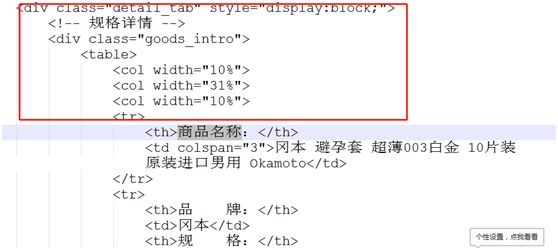
然后分析HTML可以知道只要分析下图这个div的信息就可以获取“杜大哥”的所有信息了。这个留给大家分析分析下看看怎获取。
关注我
每天进步一点点
很干!在看吗?
☟















 637
637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









