






https://www.xin3721.com/eschool/pythonxin3721/
ScrapydManage
GitHub地址:https://github.com/kanadeblisst/ScrapydManage
码云:https://gitee.com/kanadeblisst/ScrapydManage
scrapyd的Windows管理客户端,软件只是将scrapyd的api集成到exe文件中,软件是由aardio写的,GitHub有源码,可以自行编译,也可以下载GitHub中release已编译的exe文件。
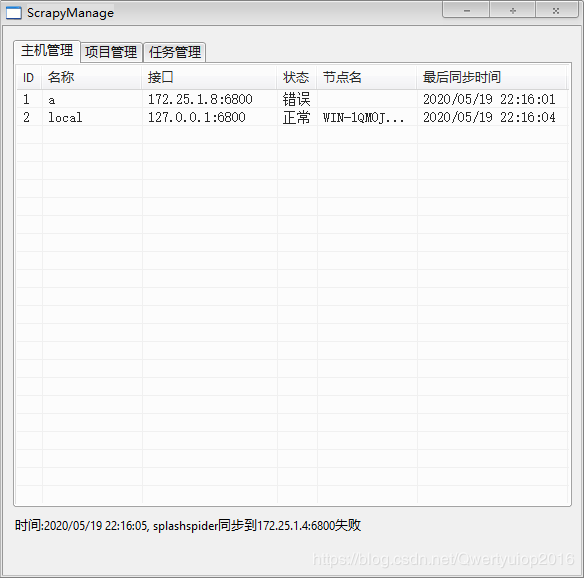
主机管理界面
右键菜单:

添加主机
添加主机顾名思义就是添加scrapyd的api地址,例如127.0.0.1:6800。不理解scrapyd怎么使用的可以参考官方文档:https://scrapyd.readthedocs.io/en/stable/index.html。其实很简单,pip install scrapyd,然后命令行输入scrapyd,或者先在当前目录创建scrapyd.conf,修改一些配置参数然后在输入scrapyd运行。
【参考配置】:
[scrapyd]
eggs_dir = D:/scrapyd/eggs
logs_dir = D:/scrapyd/logs
items_dir = D:/scrapyd/items
jobs_to_keep = 5
dbs_dir = D:/scrapyd/dbs
max_proc = 0
max_proc_per_cpu = 4
finished_to_keep = 100
poll_interval = 5.0
bind_address = 0.0.0.0
http_port = 6800
debug = off
runner = scrapyd.runner
application = scrapyd.app.application
launcher = scrapyd.launcher.Launcher
webroot = scrapyd.website.Root
node_name = localhost
[services]
schedule.json = scrapyd.webservice.Schedule
cancel.json = scrapyd.webservice.Cancel
addversion.json = scrapyd.webservice.AddVersion
listprojects.json = scrapyd.webservice.ListProjects
listversions.json = scrapyd.webservice.ListVersions
listspiders.json = scrapyd.webservice.ListSpiders
delproject.json = scrapyd.webservice.DeleteProject
delversion.json = scrapyd.webservice.DeleteVersion
listjobs.json = scrapyd.webservice.ListJobs
daemonstatus.json = scrapyd.webservice.DaemonStatus
其中注意修改三个目录eggs_dir 、logs_dir 、dbs_dir,其他的看情况自己修改。
刷新列表状态
只是向所有主机发起请求更新状态和节点名两栏,看第一张图应该很好理解
同步所有项目到所有主机
顾名思义、默认版本号(version)为当前时间戳
查看任务队列
listjobs这个接口,返回scrapyd服务端当前pending(待抓取)、running(正抓取)、finished(已抓取)的相关信息
删除主机
顾名思义
项目管理界面
项目管理主要是读取当前exe文件同级目录下projects目录内的文件夹,有点绕口大概就这意思吧。
右键有三个功能:刷新项目列表、同步所有项目到、同步到(需要右键某个项目)
创建任务界面
右键有两个功能:创建任务、取消任务
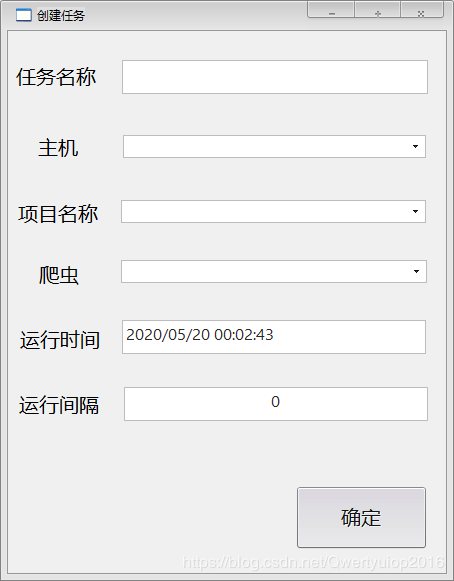
注意这里需要一级一级填写,软件步骤如下:
选择主机->软件请求服务端返回该主机下的所有项目->选择项目->软件请求服务端返回该项目下的所有爬虫
运行时间可以是如图的字符串格式,表示在指定时间运行;也可以是数字(单位秒),在指定秒数之后运行。时间间隔表示是否重复运行爬虫,重复时间间隔,只支持数字(单位秒),比如一天运行一次就填86400。
因为需要等服务器返回数据,即使用多线程也要等返回值,所以选择主机或者项目后会有卡顿,卡顿时间看返回延迟,本地的话很快。
如果需要什么其他功能的话可以自行开发,源码已经有了,二次开发应该不难,aardio语法和其他语言类似,我也了解没多久很简单就能用。














 2377
2377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









