







本文全面讲解urllib库基本使用、高级应用、异常处理,建议收藏!!!
一、urllib库基本使用
语法:urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
- 注意:data参数,当给这个参数赋值时,HTTP的请求就使用POST方法,如果data=None或者不写,则使用get方法。
1.1、url库他是python内置的HTTP请求库
他主要包含4个模块
- request: 最基本的HTTP请求模块,可以用来模拟发送请求。只需要传入URL和额外参数,就可以模拟实现这个过程
import urllib.request
url="https://me.csdn.net/column/weixin_41685388"
response = urllib.request.urlopen(url)
print(response.read().decode('utf-8'))
# read()获取响应体的内容,内容是bytes字节流,需要转换成字符串
- error:异常处理模块。
- parse:一个工具模块提供了很多URL的处理方法,如:拆分、解析、合并、格式转换等。
- robotparser:主要用于识别网站的robots.txt文件,判断哪些链接可以爬。很少使用。
1.2、第一个简单的get请求
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib.request
url="https://me.csdn.net/column/weixin_41685388"
response = urllib.request.urlopen(url)
print(type(response)) #输出:
# 一个HTTPResponse类型的对象,
# 主要包含read()、readinto()、getheader(name)、getheaders()、fileno()等方法,
# 以及msg、version、status、reason、debuglevel、closed等属性。
# 常用status属性得到返回结果的状态码
print(response.status) #返回200 表示正常请求
# getheaders()返回头部信息
print(response.getheaders())
# 返回头部信息中'Server'的值,服务器的搭建相关信息
print(response.getheader('Server'))
# 常用.read().decode('utf-8')返回网页内容,read()获取响应体的内容,内容是bytes字节流,需要转换成字符串
print(response.read().decode('utf-8')) #网页内容
1.3、判断是get请求和post请求
问题来了,如何判断是get请求和post请求,谷歌浏览器为例:打开网页-->右击,检查(N)-->Network-->F5刷新,找到我们需要的Name,Method的值一看就知道了,注意往往第一次使用的时候检查功能的时候默认没有打开Method,需手动勾选一下。
get请求,如:https://blog.csdn.net/weixin_41685388/category_9426224.html链接
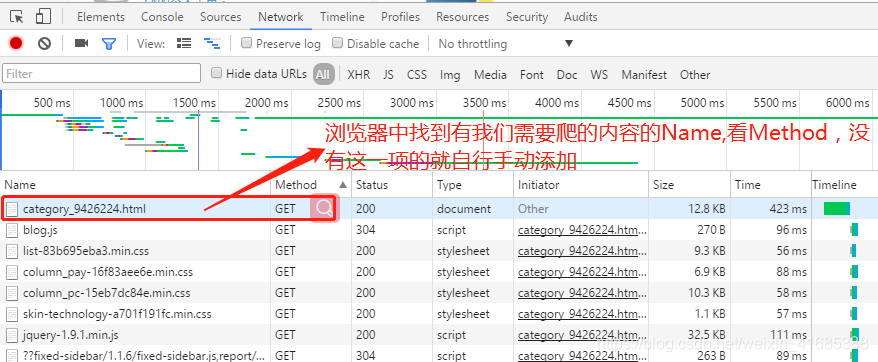
如何查看是否是我们需要的Name?
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 672
672











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









