







 代码如下from bs4 import BeautifulSoup #网页解析,获取数据import sys #正则表达式,进行文字匹配import reimport urllib.request,urllib.error #指定url,获取网页数据import xlwt #使用表格import sqlite3import lxml以上是引用的库,引用库的方法很简单,直接上图:上面第一步算有了,下...
代码如下from bs4 import BeautifulSoup #网页解析,获取数据import sys #正则表达式,进行文字匹配import reimport urllib.request,urllib.error #指定url,获取网页数据import xlwt #使用表格import sqlite3import lxml以上是引用的库,引用库的方法很简单,直接上图:上面第一步算有了,下...
代码如下
from bs4 import BeautifulSoup #网页解析,获取数据
import sys #正则表达式,进行文字匹配
import re
import urllib.request,urllib.error #指定url,获取网页数据
import xlwt #使用表格
import sqlite3
import lxml
以上是引用的库,引用库的方法很简单,直接上图:
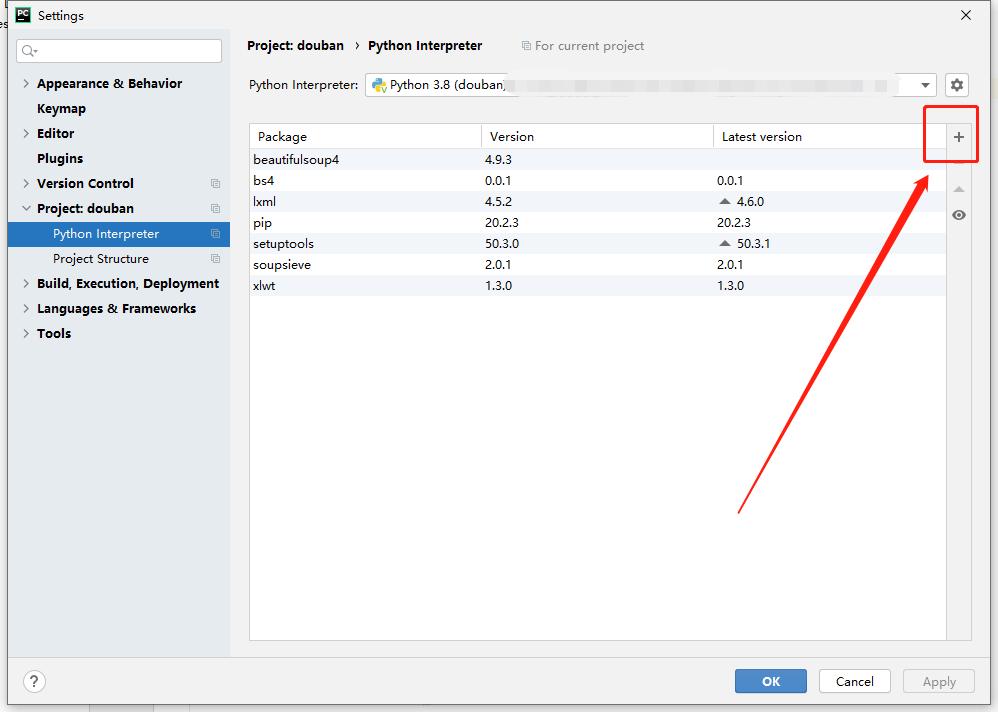

上面第一步算有了,下面分模块来,步骤算第二步来:
这个放在开头
def main():
baseurl ="https://movie.douban.com/top250?start="
datalist = getData(baseurl)
savepath=('douban.xls')
saveData(datalist,savepath)
这个放在末尾
if __name__ == '__main__':
main()
不难看出这是主函数,里面的话是对子函数的调用,下面是第三个步骤:子函数的代码
对网页正则表达提取(放在主函数的后面就可以)
爬数据核心函数
def getData(baseurl):
datalist=[]
for i in range(0,10):#调用获取页面的函数10次
url = baseurl + str(i*25)
html = askURl(url)
#逐一解析
soup = BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"):
#print(item)
data=[]
item = str(item)
link = re.findall(findLink,item)[0] #re库用来
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 889
889











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









