






 本文介绍了作者设计和实现的一个单机版MapReduce日志分析器,满足了快速、简单和资源节省的需求。系统分为JobManager、RuleEngine和JobWorker三个角色,用于日志切割、规则引擎配置和日志分析。文章讨论了报表配置、日志切割、JobWorker实现以及报表生成过程,并与传统MapReduce进行了比较和改进。
本文介绍了作者设计和实现的一个单机版MapReduce日志分析器,满足了快速、简单和资源节省的需求。系统分为JobManager、RuleEngine和JobWorker三个角色,用于日志切割、规则引擎配置和日志分析。文章讨论了报表配置、日志切割、JobWorker实现以及报表生成过程,并与传统MapReduce进行了比较和改进。
Author:放翁(文初)
闲话:(如果图片看不清楚可以看另一个blog,因为图片在家,这里上传就只能转贴了)
为什么又叫做什么…的点滴,首先现在写程序就是练手,不论自己经历了多少,如果想成为一个好的P,那么就要持续的去学习,去写,当写出来的东西总是一个样子,那就要去学习一下,当觉得整天飘飘然的和同行在胡侃,那么就要静下心来写点东西。因此我的分享总是这个点滴那个点滴的,其实大家写程序都大同小异,最宝贵的不是一个系统如何成功,而是在设计和实现这个系统的过程中,有哪些闪光点,这些闪光点日积月累就会让你写出来的东西给人一种“踏实”的感觉,同时不断的多想一步,会让你总是比别人做得更加精彩。
起因:
现在手头工作太忙,所以分享的东西很多,但是没有时间写,因此这个MapReduce “单机版”说说是练手,但其实和当前TOP的业务也很有关系。过去在开放平台中有重要的一部分内容就是日志分析和报表的功能,由于开放平台的API请求里量很大,因此过去首先采用异步日志结合MySql分表模式来做日志分析,后来演化成为了异步日志结合Hadoop的分析模式。
TOP当前对于日志系统的需求是:
1.满足不稳定的需求统计分析(性能监控调优,业务趋势分析,ISV行为统计等),快速出结果。(框架灵活度要高)
2.分析系统配置使用简单。(部署简单,维护简单,使用简单)
3.硬件资源节省。(资源投入少,长期有规划上有规模化的集群分析计算)
4.短期内上线。(开发成本低)
5.处理速度可接受。
根据以上几点当前的需求,起码现阶段的TOP需要的分析器不需要用Hadoop,同时采用Hadoop在业务上不能满足灵活的需求(发布要走流程),使用也过于复杂,硬件资源投入起码两到三台PC,开发流程上由于业务的需求变动比较大,这样如果采用比较硬的编码方式,则很难短期上线。对于当前TOP的日志量用Hadoop的速度优势暂时还不明显。
就上面这些因素,考虑化几天时间做一个单机版的MapReduce的日志分析器,满足现有需求。
设计:
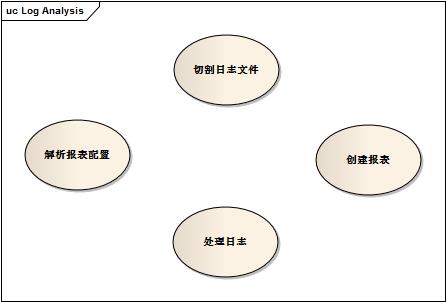
图1 Simple MapReduce Log Analysis UseCase

图2基本流程定义
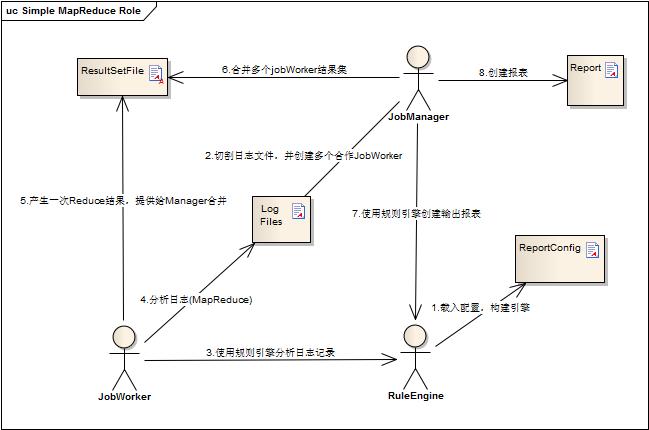
图3角色工作图
系统简化来看就分成三个角色:
1.JobManager:负责读取系统配置,和初始化分析规则引擎,切割文件,创建Worker,协同Worker并行分析,合并分析结果,输出报表。
2.RuleEngine:根据配置载入和构建日志解析规则(可定制化Map和Reduce实现),中间结果合并规则,报表创建规则,附带发送邮件等功能配置。
3.JobWorker:根据规则引擎配置,逐行分析日志,每行分析出所有配置需要的结果,作一次简单的MapReduce操作,输出中间结果给Manager。
实现:
一.报表配置及规则引擎
a.两个层次。在Hadoop的MapReduce的计算结果是Key&Value,这通常并不是我们很多分析系统希望要的最终结果,分析系统希望是得到类似于SQL查询到的一组结果,反过来看,对于一组结果其实就是一堆Key&Value的组合:
例如:
Select name,address,count(*) form t得到的结果就是以name&address组合成为key,然后累加次数产生的value。
Select name,address,average(age) form t得到的结果就是以name&address组合成为key,然后平均年龄得到的value。
而这两个结果由于都是以相同的两个字段作为索引,因此归类在一起就会形成我们通常希望看到的一个报表。因此产生了定义的报表配置的两个层次:
1.ReportEntry就是一个key&value产生的规则定义。
2.Report就是单个报表创建的定义。
b.五种基本统计函数,对于统计来说大多都是对数字的处理,抽象起来公用的主要有五种:min,max,sum,count,average。同时为了能够提供显示主键的功能,提供一个直接显示内容的plain函数,这样基本涵盖了70%的统计需求。
c.两种表达式创建Value。对于value的创建可以设置表达式,比如说每一条记录的第三列减去第四列的最大值可以配置为value=”$3$ - $4$”,用$符号分割表示对列的引用。也可以定义某一统计结果是其他列统计结果的计算结果,例如成功率可以使成功数量/总量,配置为value=”entry(成功数列号)/entry(总量列号)”,此类结果将在报表创建时候才被计算生成,属于lazy分析。
下图是具体的类定义图

具体配置参见附录说明。
二.切割日志文件
单台服务器单日最大的日志有1G多的日志,对于这么大的日志需要考虑切分一下交由多个Jobworker来并行处理提高效率。因此就涉及到了切割文件的工作。切割文件就需要做到高效,数据完整性。
高效:一般切割是对一个目录下所有文件切割,因此起一个线程池并行切割,提高效率。同时对于单个文件的切割,采用FileChannel的方式(MapFile),简单按照配置大小切割成子文件。
数据完整性:由于TOP的日志文件是以回车换行作为记录分割符,因此从第二个文件开始,每一个文件读取第一句有回车换行的内容到上一个文件,这样就可以保证数据的完整性(简单补偿方案),需要注意的就是边界情况,当最后一个文件就一句话内容,那么这句内容一旦被提前,需要删除这个子文件。
遇到的问题:
1.直接根据设置的文件块来拷贝,导致多线程并行处理时,native方法消耗内存溢出(这个其实在很多第三方的开源包中处理不好都会有这样的问题),由于Jdk提供了内存映像文件,提高速度的同时,也为这类内存申请使用带来了内存溢出的隐患(这类内存的回收和普通的GC回收不同,回收的时机也不一样),因此当机器速度越快的时候,可能溢出的情况越容易发生。于是将inChannel.transferTo(beg,blocksize, outChannel)改成了一段一段的复制。
2.单机磁盘IO瓶颈在某种程度上决定了多线程并行未必会提高多少处理效率。
3.有同学和我说你其实不用切割,直接用RandomAccessFile来读取分析就可以了,节省时间。感觉很有道理,前期陷入了思维定势,但是对于单机来说磁盘IO及文件锁使得虚拟切割的效率还不如单线程处理。(作了一下测试)
三.JobWorker实现
对于通过数据库来做统计的情况,通常会需要Select几次才会得到一个报表的几项结果,但对于逐行扫描处理的情况来说,不论配置多少Entry,在一次日志读取以后就能根据规则来计算出这个Entry的结果,因此对于海量数据的分析,在一次数据遍历以后就可以得到所有的结果。这点也是去年我和开放平台同学review他的hadoop MapReduce的时候提出的建议,如果就做一次MapReduce就需要分析一次数据,那么肯定会效率很低,通常就是需要定义一个Map就能够作很多规则的分析,这就需要对于在传统MapReduce中作较好的层次级别规划,一次数据分析能够被多个分析共享。而在这里设计JobWorker来说,本身逐行解析就可以实现这点,这也使得报表不论定义多少,分析的时间复杂度几乎没有增加。

IReportManager作用就是管理整个分析流程,初始化资源(载入配置,初始化规则引擎,切割文件),创建协调工作者,合并结果集,出报表。

定义了Worker两个实现,一个是真实文件处理的Worker,一个是虚拟文件处理的Worker。(所谓的虚拟文件,就是上面提到的虚拟切割后生成的虚拟文件)在JobWorker处理中,可以根据规则引擎中定义的单个Entry处理模式和定制化Map或者Reduce实现来替换框架已有的Map和Reduce满足不同的业务需求。具体的Map和Reduce参看下面的类图。
IReportMap就一个接口generateKeyReportEntry(ReportEntry entry,Sting[] contents),也就是每一个Map都可以得到当前处理的数据内容以及当前Entry的数据定义。IReportMap和下面的IReportReduce都是可以通过运行期配置的方式替换现有框架中的业务逻辑。

Worker具体流程图如下:

在流程中允许用自定义的Map和Reduce实现类替换默认的处理类,满足用户个性化需求,同时降低对于基础框架的依赖。
问题:
1.多线程池(Executor等)必须控制好线程数量,防止内存溢出。
2.瓶颈在IO,因此效率提高有限。
3.自定义协议解析替换了J2se 6的js engine。JS引擎很强大,但是效率不高,在大规模数据处理的时候耗时严重,成为最大的瓶颈,因此采用简单的算法来替换。
四.报表生成
最终报表的输出类型,选择了csv,首先由于csv结果排版简单,其次,可以借助excel的强大图形功能将数字结果转换成为更加直观的图形结果。
比较和改进
传统的MapReduce步骤如下:导入数据到分布式文件系统(切割文件,文件传输到dataNode,同时做好容灾准备),JobNode在JobTracker的协调下开始分析,并在本地作一次reduce(减少数据传输),再汇总作Reduce,最后生成结果。
单机版MapReduce,只是将多机协作变成了多线程协作。
1.省略数据传输不用让数据靠近计算。
2.通过配置文件的方式定制报表,可以灵活的将报表系统变成随时可以根据需求变动的动态分析系统。(每次配置文件可以从远端读取,这样就可以不发布而立刻获得不同的报表)。
3.使用便利,通过一个系统配置文件设定系统运行参数,然后直接执行jar,即可运行,不需要配置多机环境。
4.对于几十个G的数据处理正合适(效率)
5.开发调试周期短,基本上5个人日开发+测试就搞定了。
但其实缺陷还是很一目了然的,就是我们为什么要用MapReduce的多机配置的初衷,单机最终在CPU,IO上都成为瓶颈,垂直扩容和水平扩容已经没有什么好争议的了,因此采用多机合作在规模化的处理上是必然趋势。对于这个单机版作适当的调整,成为简化型日志分析专用型多机版MapReduce还是蛮有必要的。那么切入点其实就是以下几点:
1.分析数据将会散布到多机,分别切割处理。(可以不考虑容灾)
2.多机多线程分析并在本机Reduce一次,然后通过配置找到内部的Master,交由Master来最终作Reduce。(workernode之间无需知道对方的存在)
3.Master由原来内存结果合并,转变为传输过来的结果反序列化或者遵照私有消息格式来合并结果,最终创建出报表。
因此简单来说就是数据分布及中间结果的传递和合并的工作处理一下,单机版就变成了多机版。最后就在附录中详细说明一下配置及运行后的效果。
附录:
配置实例说明:
下面写一个具体的实际配置来展示如何配置一个简单的报表:(其中衍生出一些需求增强的内容)
配置文件是xml格式的,配置如下:
//定义需要给多个报表复用的Entry
//id是这个entry唯一的标识(后面被引用到报表的依据),name将会作为报表的列名,key表示会以日志记录的第几项内容作为索引,可以通过逗号分割(组合索引),value表示创建的值是按照什么规则来创建,count函数不需要有内部表达式,average,min,max,plain都需要有表达式,表达式内部$16$代表日志记录第几位作为参数传入运算,entry(16)代表对第16的entry结果作引用计算(具体参见下面配置)。这句话表示用第六位这个api名称字段作为索引,计算各个api的总调用量。
mapClass="com.taobao.top.analysis.map.APIErrorCodeMap" mapParams="key=6&errorCode=0"/>//这个配置和上面不同的就在于mapClass可以自定义实现,其实也就是实现了对于Key产生的规则实现,也就是MapReduce模型中的Map函数实现,这里可以用默认的(即简单的列组合),也可以采用复杂的方式过滤和合并key,只需要实现Map接口即可,这后面详细描述。这个配置表示产生key的过程中过滤掉不成功的请求,只统计成功请求
mapClass="com.taobao.top.analysis.map.APIErrorCodeMap" mapParams="key=6&errorCode=1"/>//统计错误请求
//统计服务平均相应时间,由于在服务处理前后有时间打点,因此简单的相减即可
//最小时间消耗
//最大时间消耗
……
//具体的报表定义
//不需要复用的entry可以直接定义在报表内部,这个定义表示直接显示第六列即API的名称
//可以计算比例,通过对entry1和entry2的结果相除,不过这个就不是在逐行分析过程中实现,而是在结果合并时处理,属于lazy后处理

















 5455
5455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









