






这里提出l 一种估计模糊核的网络 MANet,MANet 使用一种 MAConv 操作,在不增大感受野的前提下同时通过增强通道之间的建模来提升模型的表达能力,底层任务超详细解读:盲图像超分辨率中空间变体核估计的互仿射网络
盲图像超分辨率中空间变体核估计的互仿射网络
论文名称:Mutual Affine Network for Spatially Variant Kernel Estimation in Blind Image Super-Resolution (ICCV 2021)
论文地址: http://arxiv.org/pdf/2108.05302.pdf
盲超分任务介绍
作为基本的 low-level 视觉问题,单图像超分辨率 (SISR) 越来越受到人们的关注。SISR 的目标是从其低分辨率观测中重建高分辨率图像。目前已经提出了基于深度学习的方法的多种网络架构和超分网络的训练策略来改善 SISR 的性能。顾名思义,SISR 任务需要两张图片,一张高分辨率的 HR 图和一张低分辨率的 LR 图。超分模型的目的是根据后者生成前者,而退化模型的目的是根据前者生成后者。经典超分任务 SISR 认为:低分辨率的 LR 图是由高分辨率的 HR 图经过某种退化作用得到的,这种退化核预设为一个双三次下采样的模糊核 (downsampling blur kernel)。 也就是说,这个下采样的模糊核是预先定义好的。但是,在实际应用中,这种退化作用十分复杂,不但表达式未知,而且难以简单建模。双三次下采样的训练样本和真实图像之间存在一个域差。以双三次下采样为模糊核训练得到的网络在实际应用时,这种域差距将导致比较糟糕的性能。这种退化核未知的超分任务我们称之为盲超分任务 (Blind Super Resolution)。

模糊核应该建模为空间变化的
许多盲超分方法假设模糊核是空间不变的 (spatially invariant),并且它们对于一张图片只估计一个模糊核,这会带来两个次生问题:
其一,一些环境因素 (譬如真实世界中物体的运动和深度的差异,或者失焦和相机抖动造成的成像效果不理想) 导致一张图片不同位置的模糊核往往是不同的。
其二,为一整张估计出一个模糊核会受到图片中一些平滑区域 (flat patches) 带来的不利影响。对于一张自然图像,有些 patch 包含了边缘或棱角,它们对核的估计起了很大作用,比如下图1中的柱子。但是另外一些 patch 比如下图1中的,内容相对平坦,对核的估计作用较小,因为它们对应于各种不可区分但正确的模糊核。

图1:MANet 方法在 Urban100 数据集 img017 图片不同位置的核估计结果 (展示的是 SR 图,原来的 HR 图被右上角绿色框的模糊核模糊化)
本文作者认为一张图片的不同位置应该对应不同的模糊核。也就是模糊核在与 HR 图片做卷积时应该是空间变化的,不同位置本质上应该是不同的模糊核。即,同一个模糊核 a (比如21×21大小) 可能仅仅对图片中21×21大小的片区 A 有影响。另外,如果另一个片区 B (对应模糊核 b) 的图片内容来估计片区 A 的模糊核 a,还可能是有害的。因此,理想的核估计模型应该只根据待估计的核影响的局部图像片区的信息。
所以作者认为问题的关键是模糊核估计的深度神经网络不能具有太大的感受野,若感受野太大,则在估计模糊核 a 时很有可能使用到了另一个片区 B 的信息。
互仿射网络
本文提出了一种互仿射模型 (Mutual Affine Network, MANet),用来估计模糊核,如下图2所示。它的特点是感受野大小适中 (比如22×22),包含了特征提取模块和模糊核重建模块。
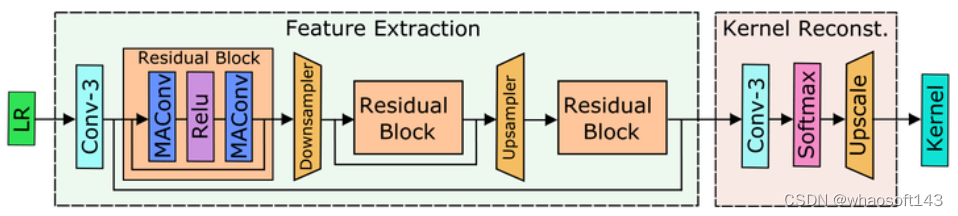
图2:互仿射模型架构,包含了特征提取模块和模糊核重建模块
特征提取模块包含一个卷积层,残差块,下采样层和上采样层。LR 图片首先通过3×3卷积提取图像特征,再依次通过三个残差块。每个残差块包含2个互仿射卷积 (MAConv) 和一个激活函数,相邻的残差块之间分别连接了下采样层和上采样层。此外,作者在特征提取模块中增加了两个 skip-connection,以利用不同级别的特征并提高模型的表达能力。
特征提取模块之后是模糊核重建模块。模糊核重建模块由一个3×3卷积操作,softmax 层,和最近邻插值得到模糊核。
通过以上这种精心设计的 MANet 架构,MANet 在 LR 图像输入上具有22×22的不大的感受野,这确保了它在估计某个像素对应位置的模糊核的时候不会受到其他距离大于11像素的图像块的干扰。同时,MANet 还提出了互仿射卷积操作,确保模型有足够的能力来预测卷积核。
互仿射卷积
一般来讲,更小的感受野意味着更浅的网络模型,学习模糊核的表征能力就更弱。要解决这个问题,一种直观的方法是增加网络的通道数。但是,它带来了呈二次方增加的参数量和计算量,所以本文提出一种新的相互仿射卷积(MAConv) 层来解决这个问题,如下图3所示。

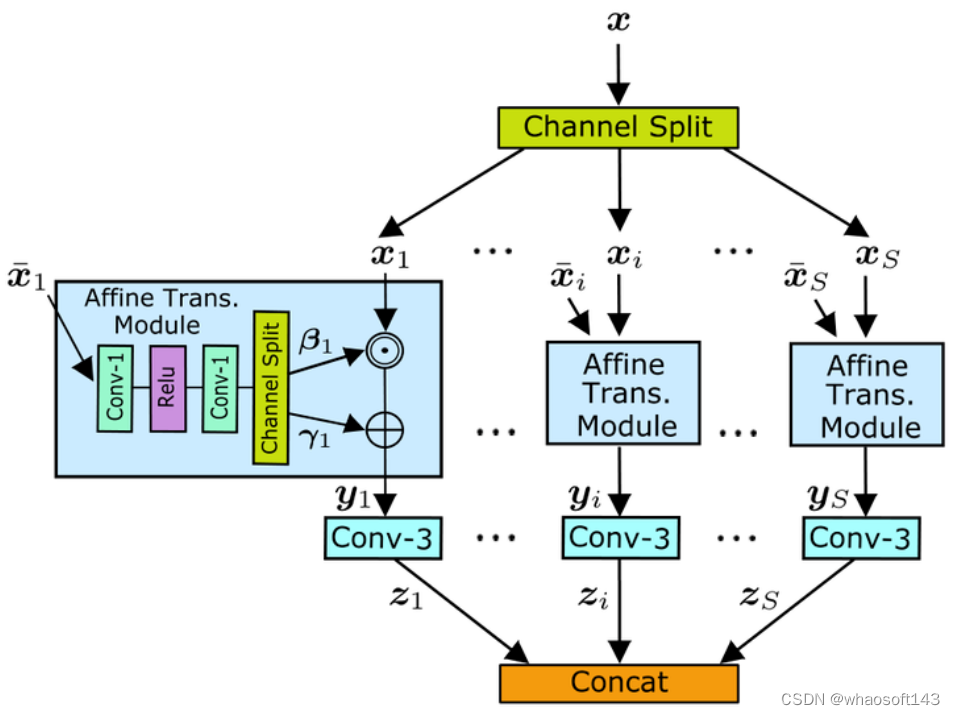
图3:互仿射卷积
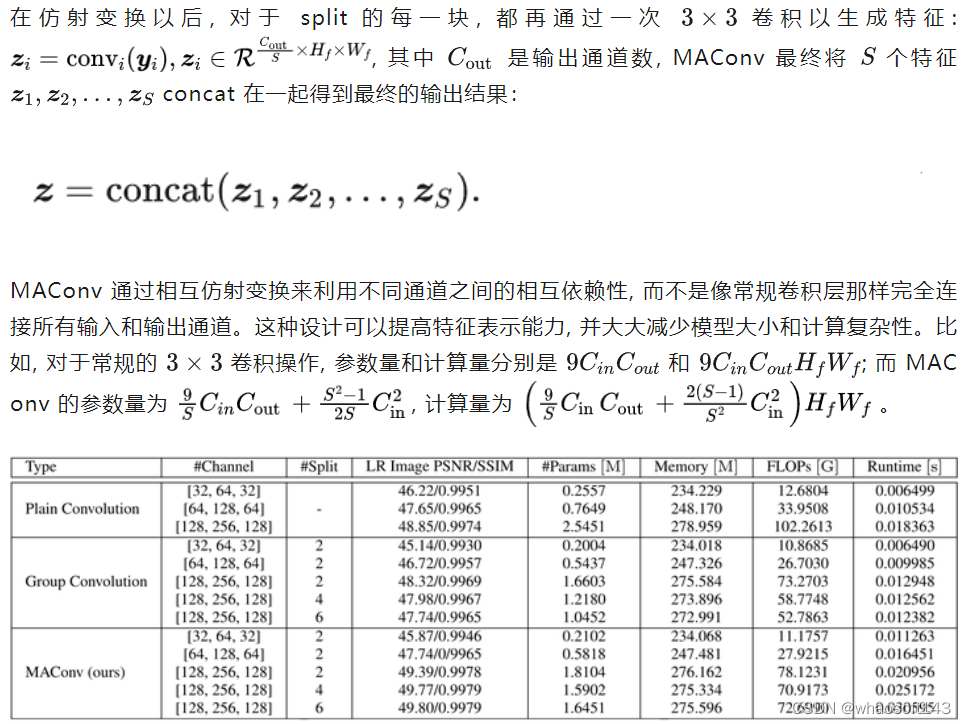
图4:几种不同卷积的比较,在256×256大小的 LR 图片上测试得到
值得注意的是,MAConv 的感受野仍然与单个3×3卷积层相同,因为仿射变换不增加感受野。
损失函数使用 MAE:

超分模型 RRDB-SFT
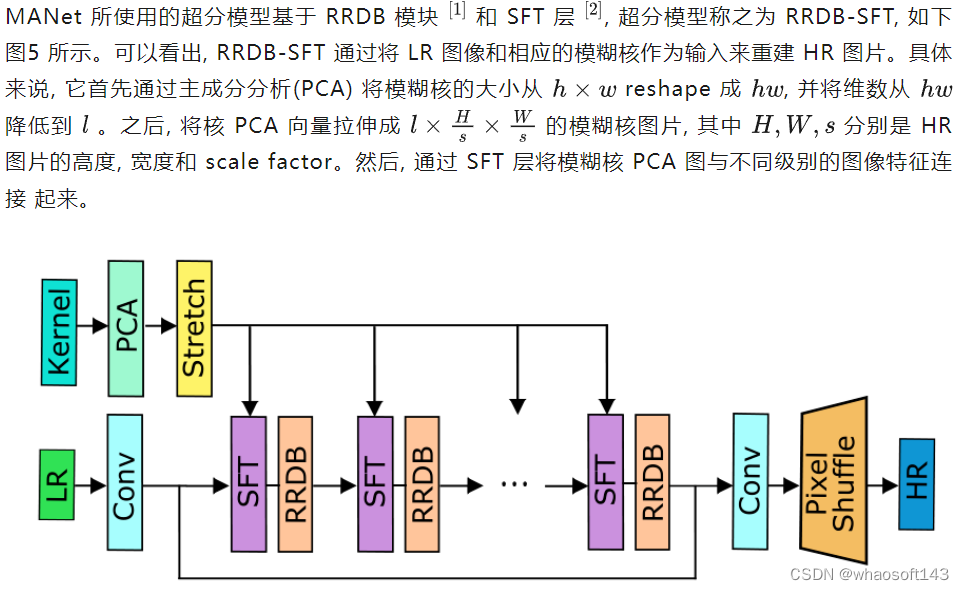
图5:MANet 超分模型

MANet 训练方法

MANet 对比实验结果
如上图4所示,作者对比了常规卷积,分组卷积和 MAConv 的参数量,计算量,运行时间以及最终性能的区别,并观察得到以下结论:
首先,MAConv 在 LR 图像 PSNR/SSIM 上实现了最佳性能,表明 MANet 估计得到的模糊核与其它竞争对手相比可以更好地保持数据真实性。MAConv 相比常规卷积具有更少的参数量和计算量。但是 MAConv 的运行时间比普通卷积稍长,因为实现代码没有针对不同拆分的并行计算进行优化。
第二,随着通道数的增加,MAConv 的模糊核估计性能得到改善。
第三,MAConv 的模糊核估计性能随着 split 次数的增加而增加。这意味着更大数量的 split 可以更好地利用通道的相互依赖性并增加特征表示能力。为了平衡准确性和运行时间,作者将通道数和分割数分别设置为 [128, 256, 128] 和 2。
MAConv 层数的影响
作者将残差块中的 MAConv 层数从2增加到4,以研究其对核估计的影响。相应地,MANet 的感受野从22×22增加到38×38。如下图6所示,结果显示,具有两个 MAConv 层的 MANet 可以准确地估计不同 patch 的核,但是当 MAConv 层数为4时,模糊核的估计就不够准确了。
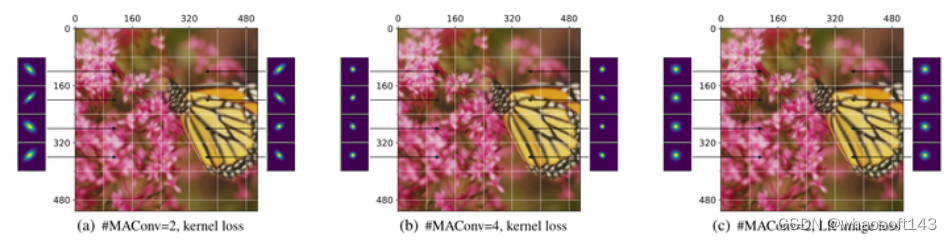
图6:当比例因子为4时,残差块中不同数量的 MAConv 层和不同训练损失的比较
Kernel Loss 和 LR Image Loss
除了上文6式所使用的 Kernel Loss 之外,另一种损失函数是 LR Image Loss,即:度量 LR 图片与根据模糊核退化后得到的 LR 图之间的 mean absolute error (MAE)。LR Image Loss 相比于 Kernel Loss 并没有对预估的模糊核有过于严格的要求,只是希望预估的模糊核能够得到比较真实的退化后的图片。如上图5对比了这两种损失函数得到的模糊核的估计结果,我们可以看出,MANet 在使用 Kernel Loss 的情况下成功地估计了模糊核。但是当使用 LR Image Loss 时,MANet 不能成功地区分不同种类的图像 patch,并且总是预测一个固定的模糊核,该模糊核可能是所有可能的模糊核的平均值。
即使 MANet 在训练的时候是一张图片对应一个 GT 模糊核,但是 MANet 在实际估计模糊核的时候也能够学会从不同的 non-flat patch 中精确地估计对应的模糊核,并为 flat patch 生成固定的模糊核。
MANet 模糊核估计实验结果
对于一张测试图片,作者作出了不同位置的模糊核估计结果,如上图1所示。可以看到对于那些不平滑的块 (non-flat patch,比如图中的 "柱子"),MANet 能够比较精确地估计出模糊核;对于那些平滑的块 (flat patch,比如图中的 "天空"),MANet 倾向于估计得到固定的模糊核。
如下图7所示右侧是一张 HR 图片,左侧是它的退化图片 (经过绿色框的模糊核退化作用)。HR图片中有一些长度不一的黑色的线 (1×1, 3×3, 5×5, 7×7, 9×9, 11×11, 21×21, 41×41, 61×61),左侧是它们对应的模糊核的估计结果。可以看出 MANet 可以根据最小9×9大小的图像块估计模糊核,当图像块更大时,估计效果更加准确。对于没有角和边的平坦的片区,MANet 将估计一个固定的类似各向同性的核。
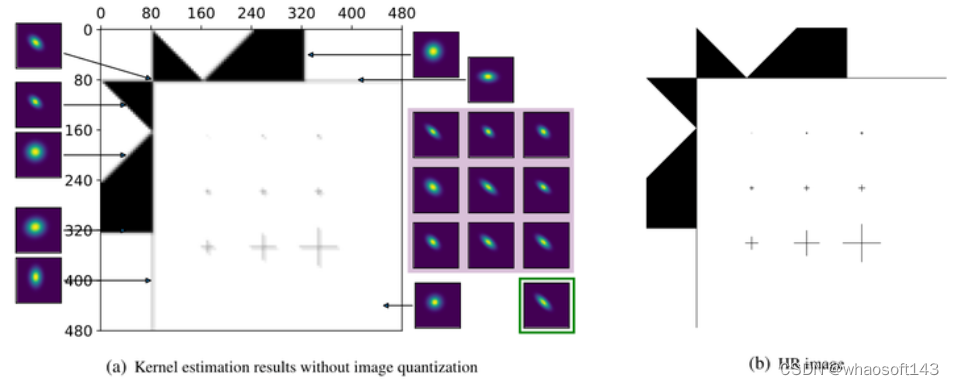
图7:MANet 对于一张合成图片的模糊核估计结果,右侧是 HR 图片,左侧是退化后的图片 (经过绿色框的模糊核退化作用)
超分任务实验结果
空间变化的模糊核实验
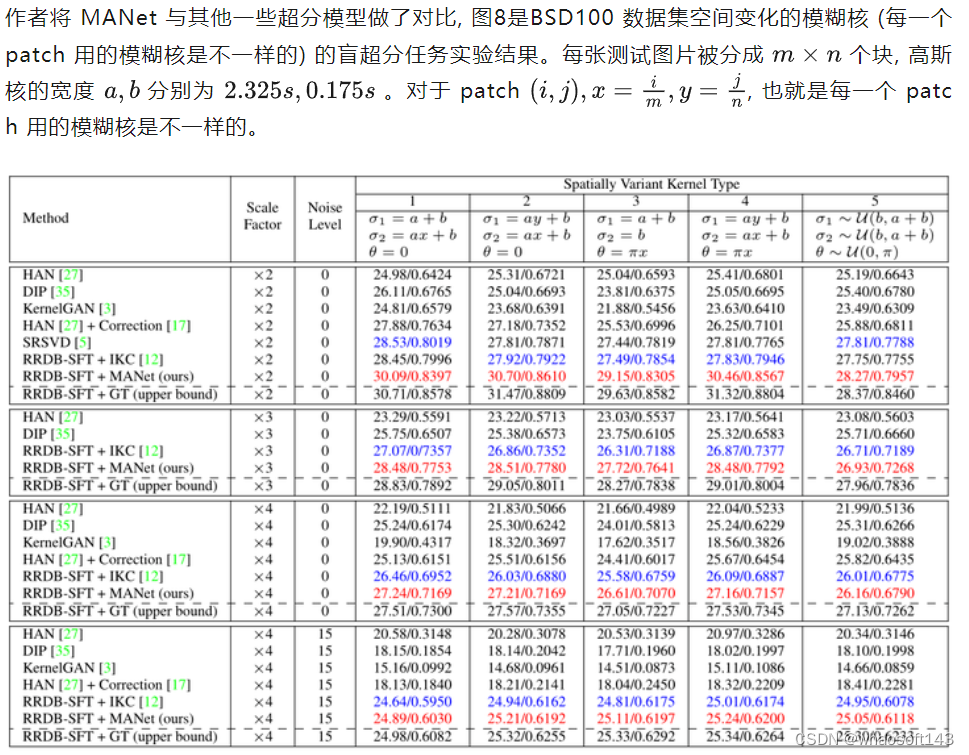
图8:BSD100 数据集空间不变的模糊核的盲超分任务实验结果
从实验结果可以看出,对于不同的空间变化的模糊核类型,MANet 都能得到最佳的性能。相比之下,本文提出的 MANet 估计图像上每个位置的核。因此,它可以处理空间变化的退化模糊作用,并基于相同的非盲模型大幅超过 IKC。即使在有图像噪声的情况下,MANet 仍然取得了优于其他模型的性能。
下图9比较了不同方法的视觉结果。虽然已知 GAN 损失可以提高视觉质量,但是为了简单和公平的比较,作者仅用 L1 像素损失来训练所有这些模型。可以看到,当内核不匹配时,HAN 倾向于生成模糊的结果,而 DIP 生成的图像带有一些类似噪声的伪像。KernelGAN 和 IKC 的核估计要么太平滑,要么太尖锐,导致最终 SR 图像上出现环状或模糊的伪影。相比之下,本文提出的 MANet 能够处理空间变化的退化,并产生最佳的视觉效果。

图9:BSD100 数据集空间不变的模糊核的盲超分任务实验视觉效果
空间不变的模糊核实验
作者进一步测试了当模糊核是空间不变时的各个模型的性能对比。如图10所示为不同数据集空间不变的模糊核的盲超分任务实验结果。MANet 通过为不同的图像块估计不同的模糊核,使得其性能依然超过了已有的方法如 HAN,DIP,SRSVD,IKC 等等。
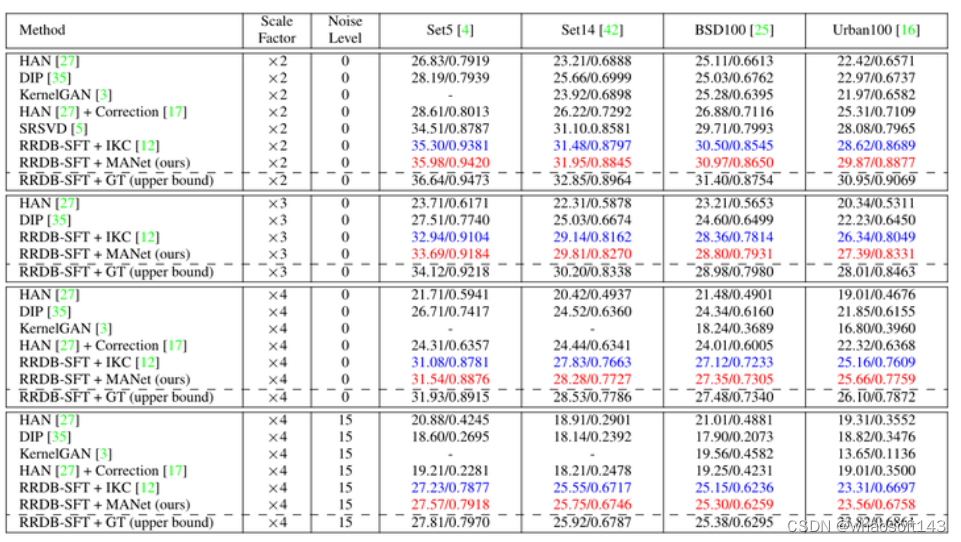
图10:不同数据集空间不变的模糊核的盲超分任务实验结果
真实世界图片盲超分视觉效果
作者进一步对比了不同的模型在真实世界图片盲超分视觉效果。真实世界图片没有 GT 的 HR 图,结果如上图9中的最后一行所示。HAN 的结果比较模糊,DIP 和 KernelGAN 有人工伪影,IKC 过度锐化了图像,并且在边缘上有明显的伪像,可能是因为它只为不同的区域估计一个模糊核。本文提出的 MANet 效果更佳。MANet 为不同位置估计了不同的模糊核,自适应地将高频细节添加到边缘,将低频信息添加到平坦区域,因此复原的图像具有较少的伪像和更加自然的边缘。
总结
本文提出的 MANet 是一种估计模糊核的网络,它的特点是具有大小适中的感受野,因为作者认为真实世界中的退化作用是空间变化的,因此不同位置应该建模成不同的退化作用,因此模糊核估计网络的感受野不宜过大。具体而言,MANet 使用一种 MAConv 操作,在不增大感受野的前提下同时通过增强通道之间的建模来提升模型的表达能力。空间变化的模糊核实验,空间不变的模糊核实验和真实世界盲超分实验都证明了模型的有效性。















 1627
1627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









