







@[TOC]前言
记录每日计划与总结以及实验的方法与结果。
提示:以下是本篇文章正文内容,下面案例可供参考
一、每日记录
| 日期 | 上午计划 | 下午计划 | 总结 |
|---|---|---|---|
| 2021-12-08 | 阅读论文《Towards Open-Set Semantic Segmentation of Aerial Images》 | 影像数据分析 | 选取论文应该更加慎重,减少不必要的时间浪费 |
| 2021-12-10 | 服务器环境配置 | 影像数据分析 | 数据挖掘可以使我们事半功倍 |
| 2021-12-13 | 阅读论文《Panoptic Segmentation of Satellite Image Time Series with Convolutional Temporal Attention Networks(ICCV)》 | 读论文 | 时序的语义分割 |
| 2021-12-14 | 数据标注 | 数据标注 | 无 |
| 2021-12-15 | 数据标注 | 数据标注 | 无 |
| 2021-12-16 | 阅读论文《Lightweight Temporal Self-Attention for Classifying Satellite Images Time Series》 | 读论文 | 以输入向量代替需要学习的Value可以提高效率 |
| 2021-12-17 | 生成训练集 | ResUNet | 无 |
| 2021-12-20 | NDWI作为比较 | DeepLabV3+ | 无 |
| 2021-12-21 | UNet++ | UNet++ | 无 |
二、论文汇总
- Towards Open-Set Semantic Segmentation of Aerial Images Caio C.V.da Silva. CVPR,2020(PDF)(Citations 6)
- 开放场景分类,结果包含着Unknown Class,但实验结果精度并没有很大的提升。
- Panoptic Segmentation of Satellite Image Time Series with Convolutional Temporal Attention Networks Vivien Sainte Fare Garnot. ICCV,2021(PDF)(Citations 1)
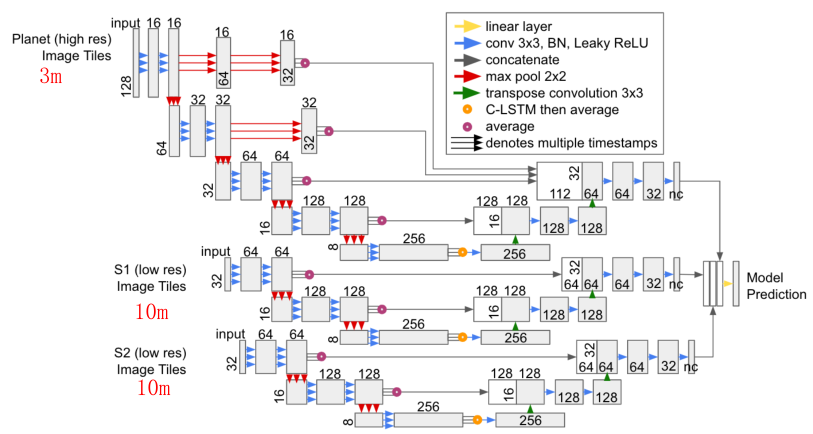
- 可以将一整年的遥感影像(T×B×C×H×W)放入网络中,不用去掉云覆盖,在最低分辨率处加入时间Attenrion模块(Lightweight Temporal Self-Attention),下采样中采用GroupNorm而不是BatchNorm,用以解决时序长度不相同的问题,最后提高了农田分割的精度。
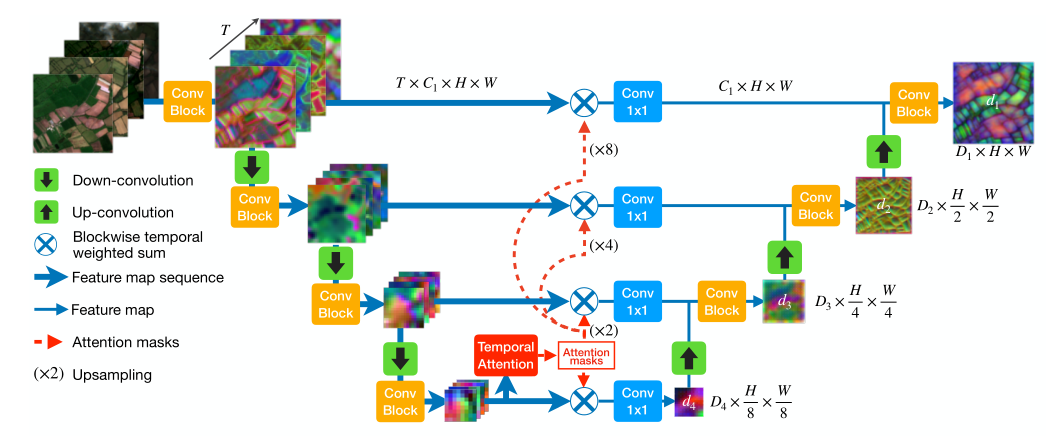
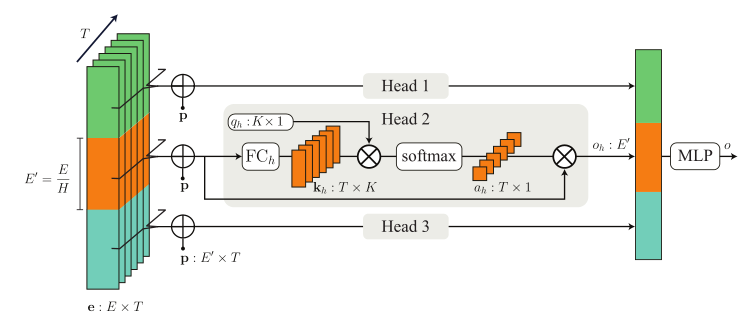
- Lightweight Temporal Self-Attention for Classifying Satellite Images Time Series Vivien Sainte Fare Garnot and Loic Landrieu. Advanced Analytics and Learning on Temporal Data,2020(PDF)(Citations 10)
- L-TAE采用了信道分组策略,下图中H为头的个数,用输入向量取代Value
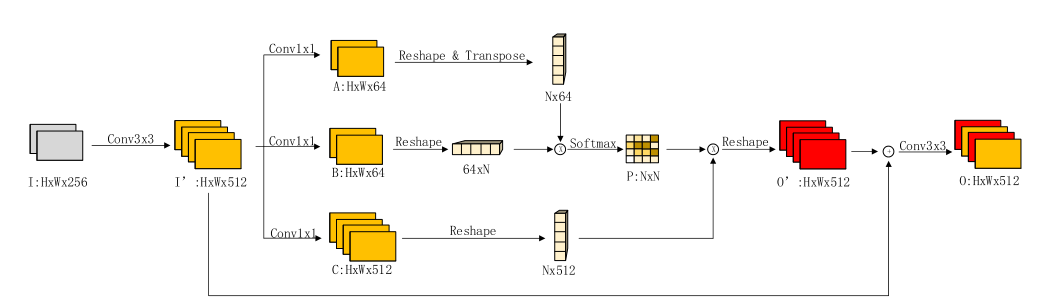
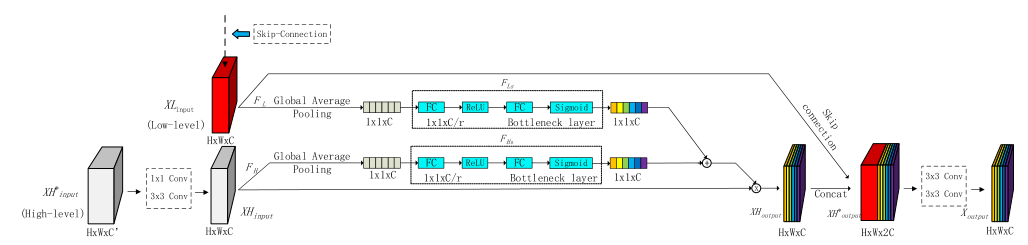
- MA-Net: A Multi-Scale Attention Network for Liver and Tumor Segmentation Tongle Fan.GuangLei Wang.IEEE Access, 2020 (PDF)(Citations 21)
- 设计了两个注意力模块:基于空间的注意块(PAB)和多尺度(不同特征通道数)融合注意块(MFAB)。
- Semantic Segmentation of Crop Type in Africa: A Novel Dataset and Analysis of Deep Learning Methods Rose Rustowicz, Robin Cheong, Lijing Wang.CVPR,2019 (Citations 34)
- 不同分辨率遥感数据在语义分割当中的应用,最后的标签是低分辨率的10m
- 在得到不同分辨率的分割结果后的融合
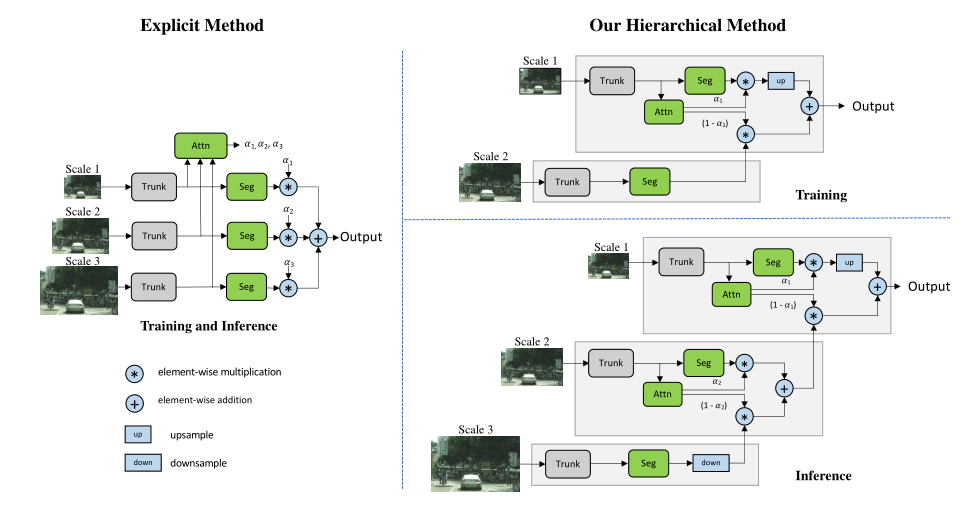
- Hierarchical Multi-Scale Attention for Semantic Segmentation Andrew Tao,Karan Sapra,Bryan Catanzaro.CVPR,2020 (Citations 171)
- 一种基于注意力机制的多尺度预测结果结合
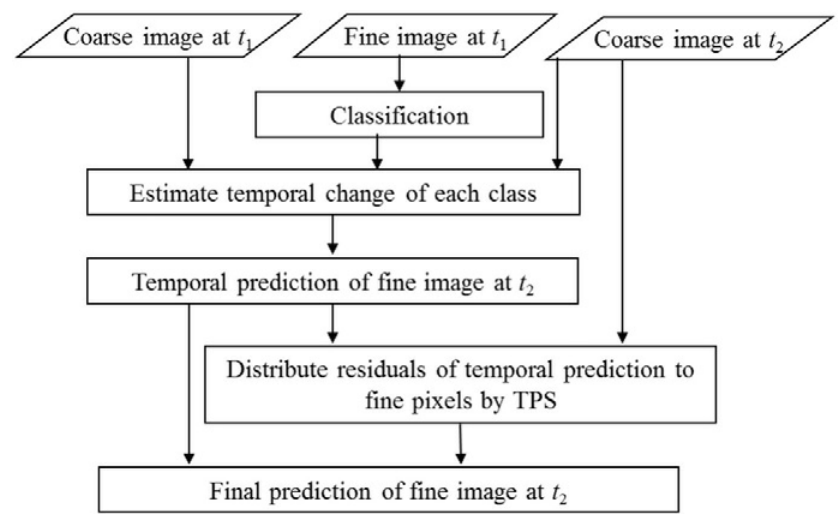
- Aflexible spatiotemporal method for fusing satellite images with different resolutions Xiaolin Zhu,Eileen H. Helmer.Remote Sensing of Environment,2016 (Citations 307)
- 高分辨率影像与高采集率(低分辨率)影像的融合方法,FSDAF
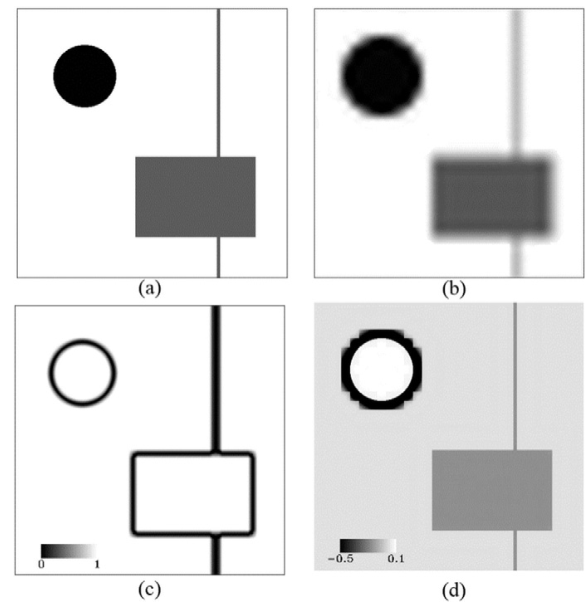
- 选择纯像素,最小二乘法得到ΔF,得到(a)图。地物覆盖变化没能Get到。
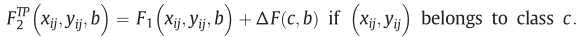
- 直接用t2粗分辨率,TPS插值得到(b)图,Get到了地物覆盖变化,但是边界模糊。
- 根据(b)图,得到新的残差分布r,得到最后的ΔF,即(d)图
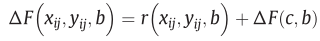
- 理论上直接相加(a)、(b)即可,但因为是逐像素的,存在不确定性和块效应(d图),因此使用额外的邻域信息来减少最终预测的不确定性,同时减轻块效应

三、数据集创建
在原始影像上裁剪3张5000×5000的影像:
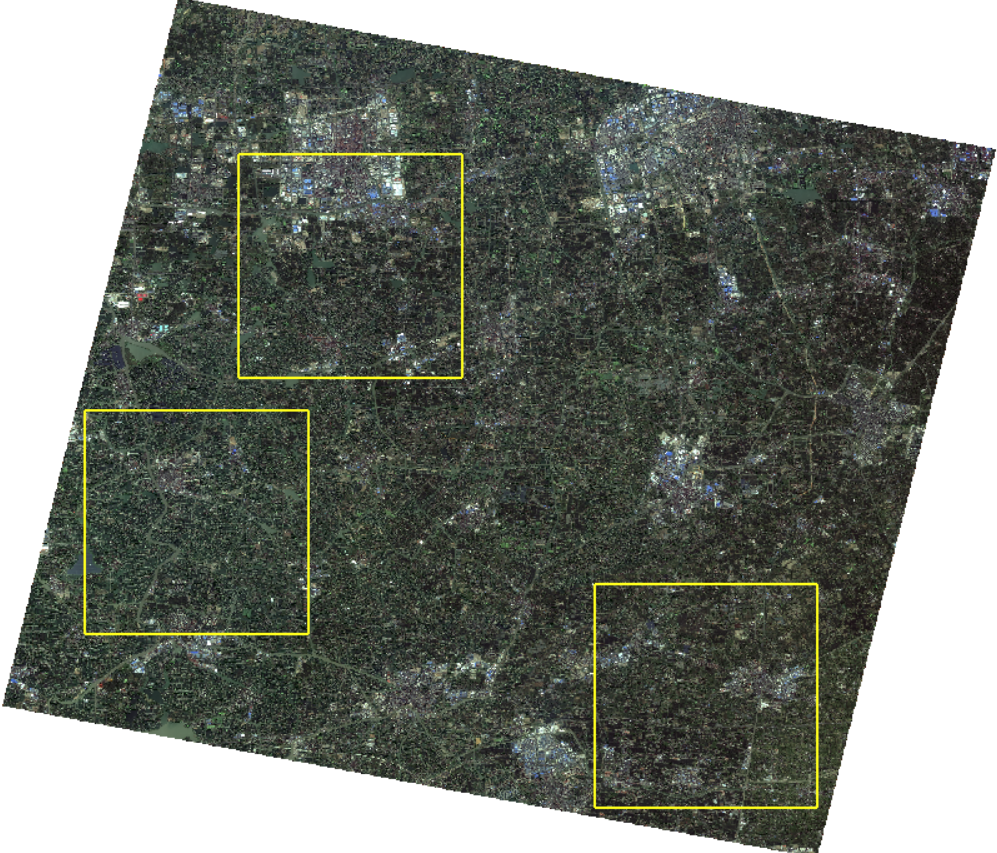

| 水体占比 | |
|---|---|
| Waterset0 | 4.12% |
| Waterset1 | 21.26% |
| Waterset2 | 42.87% |
四、结果记录
| 交叉验证 | ndwi > 0.2 | Ex0:Resnet34+UNet(33min) | Ex1:Deeplabv3+(35min) | Ex2:UNet++(57min) | Ex3:MANet(52min) |
|---|---|---|---|---|---|
| Water0 | 95.00% | 99.05% | 98.87% | 99.03% | 99.01% |
| Water1 | 87.17% | 97.74% | 97.42% | 97.75% | 97.76% |
| Water2 | 88.13% | 96.10% | 95.22% | 96.07% | 95.98% |
总结
测试数据的分布与训练数据不同时,精度下降很大,原因应该是训练数据分布过于特殊。

















 800
800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









