






索引实验
实验目的:了解索引对于全列匹配,最左前缀匹配、范围查询的影响。实验所用数据库见文章最底部连接。
实验软件版本:5.7.19-0ubuntu0.16.04.1-log (Ubuntu)
实验存储引擎:InnoDB
show index from `employees`.`titles`

实验一、全列匹配
explain select * from `employees`.`titles` where `emp_no`='10001' and title='Senior Engineer' and `from_date`='1986-06-26';

很明显,当按照索引中所有列进行精确匹配(这里精确匹配指“=”或“IN”匹配)时,索引可以被用到。这里有一点需要注意,理论上索引对顺序是敏感的,但是由于MySQL的查询优化器会自动调整where子句的条件顺序以使用适合的索引。
explain select * from `employees`.`titles` where `from_date`='1986-06-26' and `emp_no`='10001' and title='Senior Engineer';

实验二、最左前缀匹配
explain select * from `employees`.`titles` where `emp_no`='10001';

当查询条件精确匹配索引的左边连续一个或几个列时,如或,所以可以被用到,但是只能用到一部分,即条件所组成的最左前缀。上面的查询从分析结果看用到了PRIMARY索引,但是key_len为4,说明只用到了索引的第一列前缀。
实验三、查询条件用到了索引中列的精确匹配,但是中间某个条件未提供
explain select * from `employees`.`titles` where `emp_no`='10001' and `from_date` = '1986-06-26' ;

此时索引使用情况和实验二相同,因为title未提供,所以查询只用到了索引的第一列,而后面的from_date虽然也在索引中,但是由于title不存在而无法和左前缀连接,因此需要对结果进行扫描过滤from_date(这里由于emp_no唯一,所以不存在扫描)。
如果想让from_date也使用索引而不是where过滤,可以增加一个辅助索引,此时上面的查询会使用这个索引。除此之外,还可以使用一种称之为“隔离列”的优化方法,将emp_no与from_date之间的“坑”填上。
看下title一共有几种不同的值。
select distinct(title) from `employees`.`titles`;
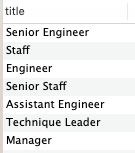
只有7种。在这种成为“坑”的列值比较少的情况下,可以考虑用“IN”来填补这个“坑”从而形成最左前缀:
explain select * from `employees`.`titles`
where `emp_no` = '10001'
and `title` IN ('Senior Engineer', 'Staff', 'Engineer', 'Senior Staff', 'Assistant Engineer', 'Technique Leader', 'Manager')
and `from_date` = '1986-06-26';

这次key_len为59,说明索引被用全了,但是从type和rows看出IN实际上执行了一个range查询,这里检查了7个key。看下两种查询的性能比较:
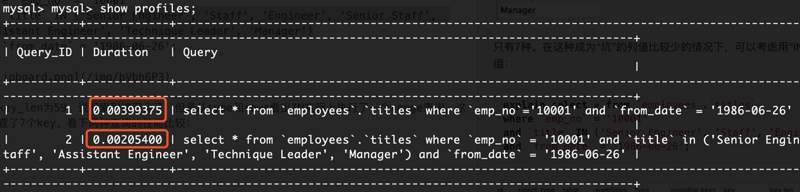
“填坑”后性能提升了一点。如果经过emp_no筛选后余下很多数据,则后者性能优势会更加明显。当然,如果title的值很多,用填坑就不合适了,必须建立辅助索引。
实验四:查询条件没有指定索引第一列
explain select * from `employees`.`titles` where `from_date` = '1986-06-26';

由于不是最左前缀,索引这样的查询显然用不到索引。
实验五:匹配某列的前缀字符串
explain select * from `employees`.`titles`where `emp_no` = '10001' and `title` like 'Senior%';

此时可以用到索引。如果配符%不出现在开头,则可以用到索引,但根据具体情况不同可能只会用其中一个前缀。
实验六:范围查询
explain select * from `employees`.`titles` where `emp_no` < '10010' and `title` = 'Senior Engineer';

范围列可以用到索引(必须是最左前缀),但是范围列后面的列无法用到索引。同时,索引最多用于一个范围列,因此如果查询条件中有两个范围列则无法全用到索引。
explain select * from `employees`.`titles`
where `emp_no` < '10010'
and `title` = 'Senior Engineer'
and `from_date` between '1986-01-01' and '1986-12-11';

可以看到索引对第二个范围索引无能为力。这里特别要说明MySQL一个有意思的地方,那就是仅用explain可能无法区分范围索引和多值匹配,因为在type中这两者都显示为range。同时,用了“between”并不意味着就是范围查询,例如下面的查询:
explain select * from `employees`.`titles`
where `emp_no` between '10001' and '10010'
and `title` = 'Senior Enginee'
and `from_date` between '1986-01-01' and '1986-12-31';

看起来是用了两个范围查询,但作用于emp_no上的“BETWEEN”实际上相当于“IN”,也就是说emp_no实际是多值精确匹配。可以看到这个查询用到了索引全部三个列。因此在MySQL中要谨慎地区分多值匹配和范围匹配,否则会对MySQL的行为产生困惑。
实验七:查询条件中含有函数或表达式
如果查询条件中含有函数或表达式,则MySQL不会为这列使用索引(虽然某些在数学意义上可以使用)。例如:
explain select * from `employees`.`titles` where `emp_no` = '10001' and left(`title`, 6) = 'Senior';

虽然这个查询和实验五中功能相同,但是由于使用了函数left,则无法为title列应用索引,而实验五中用LIKE则可以。再如:
explain select * from `employees`.`titles` where `emp_no` - 1 = '10000';

显然这个查询等价于查询emp_no为10001的函数,但是由于查询条件是一个表达式,MySQL无法为其使用索引。因此在写查询语句时尽量避免表达式出现在查询中,而是先手工私下代数运算,转换为无表达式的查询语句。
索引选择性与前缀索引
索引选择性
所谓索引的选择性(Selectivity),是指不重复的索引值(也叫基数,Cardinality)与表记录数(#T)的比值:
Index Selectivity = Cardinality / #T
显然选择性的取值范围为(0, 1],选择性越高的索引价值越大,这是由B+Tree的性质决定的。例如,上文用到的employees.titles表,如果title字段经常被单独查询,是否需要建索引,我们看一下它的选择性:
select count(distinct(title))/count(*) as selectivity from `employees`.`titles`;
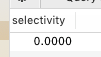
title的选择性不足0.0001(精确值为0.00001579),所以实在没有什么必要为其单独建索引。
前缀索引
有一种与索引选择性有关的索引优化策略叫做前缀索引,就是用列的前缀代替整个列作为索引key,当前缀长度合适时,可以做到既使得前缀索引的选择性接近全列索引,同时因为索引key变短而减少了索引文件的大小和维护开销。
explain select * from `employees`.`employees` where `first_name` = 'Eric' and `last_name` = 'Anido';
因为employees表只有一个索引,那么如果我们想按名字搜索一个人,就只能全表扫描了:

如果频繁按名字搜索员工,这样显然效率很低,因此我们可以考虑建索引。有两种选择,建或,看下两个索引的选择性:
select count(distinct(first_name))/count(*) as selectivity from `employees`.`employees`;
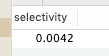
select count(distinct(concat(first_name, last_name)))/count(*) as selectivity from `employees`.`employees`;
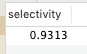
显然选择性太低,选择性很好,但是first_name和last_name加起来长度为30,有没有兼顾长度和选择性的办法?可以考虑用first_name和last_name的前几个字符建立索引,例如,看看其选择性:
select count(distinct(concat(first_name, left(last_name, 4))))/count(*) as selectivity from `employees`.`employees`;
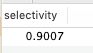
加索引
ALTER TABLE employees.employees
ADD INDEX `first_name_last_name4` (first_name, last_name(4));
前缀索引兼顾索引大小和查询速度,但是其缺点是不能用于ORDER BY和GROUP BY操作,也不能用于Covering index(即当索引本身包含查询所需全部数据时,不再访问数据文件本身)。
MySQL事务隔离层级实验
实验目的:了解MySQL中事务隔离级别以及什么是脏读,幻读,不可重复读。
实验一:脏读
定义:在两个事务中,一个事务读到了另一个事务未提交的数据。因为数据可能被回滚,不符合隔离性的定义。
1.新建数据库连接执行一下操作
set global transaction isolation level read uncommitted;
set autocommit = 0;
begin;
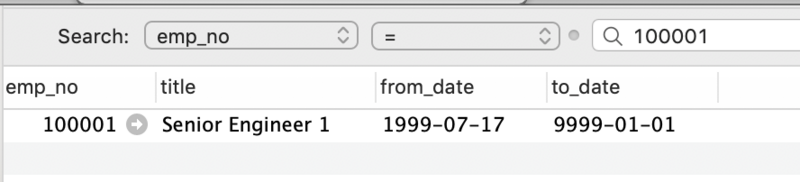
update `employees`.`titles` set `title` = 'Senior Engineer 1' where `emp_no` = 100001;
注意还没有执行 commit
2.然后新建一个连接 可以看到读到了另一个事物还未被commit的数据,这就是所谓的脏读。
实验二:幻读
定义:一个事务批量读取了一批数据时,另一个事务提交了新的数据,当之前的事务再次读取时,会产生幻影行。
如丙存款100元未提交,这时银行做报表统计account表中所有用户的总额为500元,然后丙提交了,这时银行再统计发现帐户为600元了,造成虚读同样会使银行不知所措,到底以哪个为准。
1.设置事物隔离级别。
set global transaction isolation level read committed;
begin;
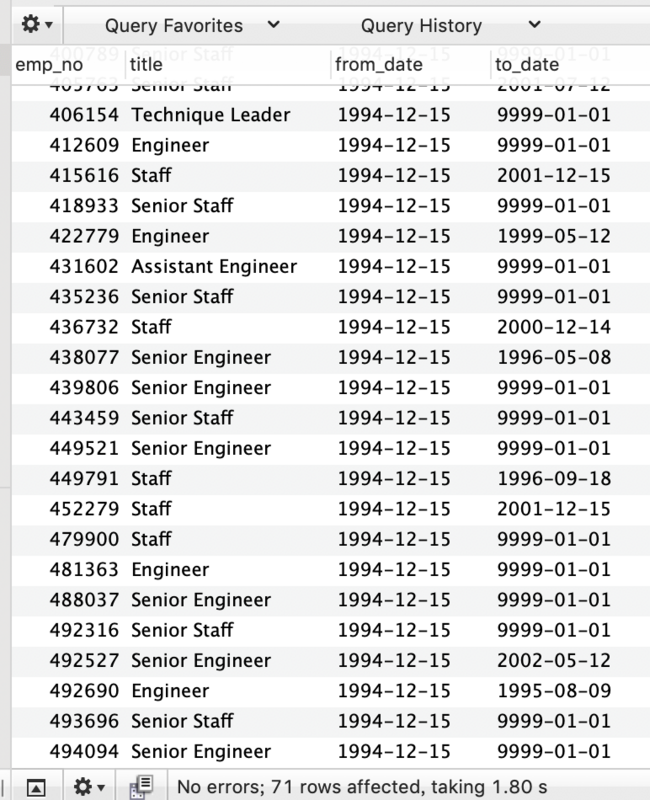
select * from `employees`.`titles` where `titles`.`from_date` = '1994-12-15';
2.新开一个连接
begin;
insert into `titles` values (499999, 'Engineer', '1994-12-15', '1994-12-15');
commit;
3.回到第一步的窗口,查询数据。
select * from `employees`.`titles` where `titles`.`from_date` = '1994-12-15';
commit;
实验三:不可重复读
定义:不可重复读指在一个事务内读取表中的某一行数据,多次读取结果不同。
例如银行想查询A帐户余额,第一次查询A帐户为200元,此时A向帐户内存了100元并提交了,银行接着又进行了一次查询,此时A帐户为300元了。银行两次查询不一致,可能就会很困惑,不知道哪次查询是准的。
不可重复读和脏读的区别是,脏读是读取前一事务未提交的脏数据,不可重复读是重新读取了前一事务已提交的数据。
很多人认为这种情况就对了,无须困惑,当然是后面的为准。我们可以考虑这样一种情况,比如银行程序需要将查询结果分别输出到电脑屏幕和写到文件中,结果在一个事务中针对输出的目的地,进行的两次查询不一致,导致文件和屏幕中的结果不一致,银行工作人员就不知道以哪个为准了。
开启连接查询值。
begin;
select * from `employees`.`titles` where `emp_no` = 100001;
select * from `employees`.`titles` where `emp_no` = 100001;

2.新开一个连接修改emp_no为100001的title的值。
begin;
update `employees`.`titles` set `title` = 'Senior Engineer 1' where `emp_no` = 100001;
commit;
3.回到第一步的连接再次查询
select * from `employees`.`titles` where `emp_no` = 100001;

MySQL事务隔离级别
未提交读:第一个事务还未提交,另一个事务就可以读取,导致脏读。
提交读(不可重复读):一个事务未提交对其他事务不可见,但是会产生幻读和不可重复读。
可重复读(mysql默认隔离级别):保证同一个事务下多次读取的结果一致,但是会产生幻读。
可串行化:严格的串行阻塞,并发能力不好。
隔离级别
脏读
不可重复读
幻读
Read Uncommitted
✅
✅
✅
Read Committed
❌
✅
✅
Repeatable Read (默认)
❌
❌
✅
Serializable
❌
❌
❌
参考资料














 1199
1199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









