







在昨晚23点的best paper典礼上我惊了,这篇看似标题党的论文获得了今年ACL2020 best paper荣誉提名!PS:今年一共只有2篇最佳论文提名,完整获奖名单戳这里。
我的这篇专栏文章完成于6月22日,没想到居然获得最佳论文提名了(意外~)!回想当初写这篇文章的初衷,大概是这个paper比较轻松、直抒胸臆吧~,同时在做医疗NLP任务的时候,发现BERT在自己的大量医疗语料中继续预训练,效果提升还是很明显的(惊喜~)!
这篇获奖paper有啥亮点呢?让我们一探究竟:
乘风破浪、披荆斩棘的各种预训练语言模型[2],都备受我们NLPer的关注。而你是否思考过:
- 直接拿BERT对目标任务进行finetune就够了吗?是否仍有提升空间?
- BERT直接finetune效果还不行,咋办?
这篇获得ACL2020最佳论文提名奖的、来自Allen AI 的《Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks》[1]告诉我们:不要停止预训练!在目标领域和任务上要继续进行预训练,效果还会有明显提升(意外惊喜~)。
为了更好地理解这篇paper,我们需要牢记两个重要的专有名词:
- DAPT:领域自适应预训练(Domain-Adaptive Pretraining),就是在所属的领域(如医疗)数据上继续预训练~
- TAPT:任务自适应预训练(Task-Adaptive Pretraining),就是在具体任务数据上继续预训练~
废话不说,我们快速播报一下这篇获得最佳论文提名奖的paper的重要结论:
- 在目标领域的数据集上继续预训练(DAPT)可以提升效果;目标领域的语料与RoBERTa的原始预训练语料越不相关,DAPT效果则提升更明显。
- 在具体任务的数据集上继续预训练(TAPT)可以十分“廉价”地提升效果。
- 结合二者(先进行DAPT,再进行TAPT)可以进一步提升效果。
- 如果能获取更多的、任务相关的无标注数据继续预训练(Curated-TAPT),效果则最佳。
- 如果无法获取更多的、任务相关的无标注数据,采取一种十分轻量化的简单数据选择策略,效果也会提升。
笔者这里给出一个重要的实验结果:RoBERTa直接对生物医学领域的某个分类任务(低资源设置)进行finetune时,f1只有79.3,而采取DAPT+Curated-TAPT后,指标提升至83.8!提升居然有4.5个percent!效果也是杠杠的~
也就是说:当我们所执行任务的标注数据较少,所属的领域与初始预训练语料越不相关,而又能获取到充分的、任务相关的无标注数据时,那就不要停止领域预训练和任务预训练!
下面对这篇paper做详细的介绍,本文的组织结构为:
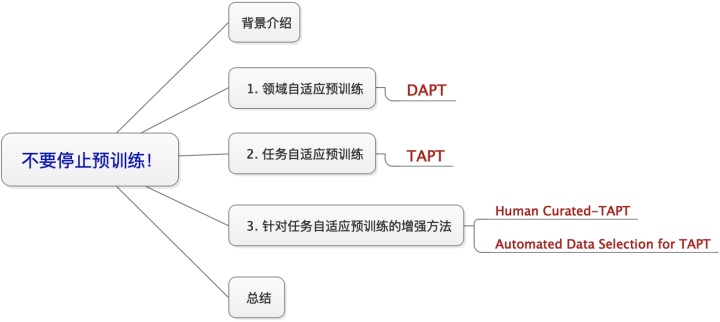
背景介绍
大多数语言模型都在诸如Wikipedia的通用语料中预训练,而在领域化的特定场景会受到限制。因此很多研究致力于发掘:对目标领域的数据继续进行预训练是否可行?如基于生物医学文本的BioBERT[3],基于科学文本的SciBERT[4],基于临床文本的Clinical-BERT[5]。我们通常称这种范式为domain-pretrain或者post-pretrain。此外,一些工作对具体任务,将语言模型做为辅助目标进行训练,如GPT1.0 [8]。
上述各种领域BERT虽然表明继续进行领域预训练的优势,但这些研究一次仅考虑单个领域,而且BERT原始预训练的语料库相比于后来居上的语言模型仍然较小、多样性也不足。更重要的是,我们尚不清楚一些问题,例如:
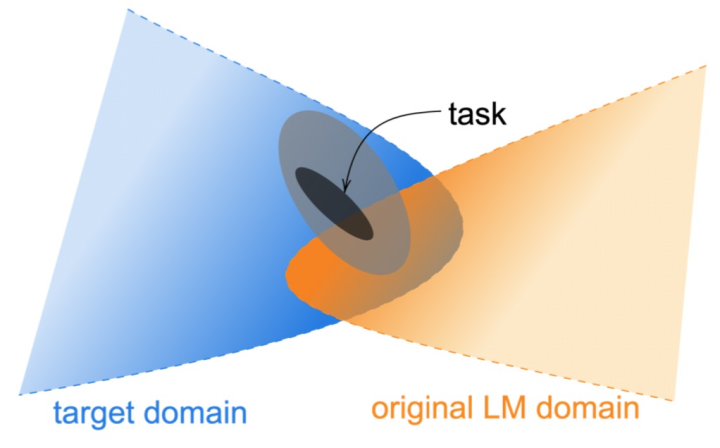
- 持续预训练的优势是否和下游任务的标注数量有关?
- 持续预训练的优势是否和目标领域与原始预训练语料库的接近程度有关?(如图1所示)
1、领域自适应预训练
领域自适应预训练(Domain-Adaptive Pretraining,DAPT),即在领域相关的大规模无标注语料继续进行预训练,然后再对特定任务进行finetune。
论文选取了4个领域语料库,分别为生物医学(BioMed)领域、计算机科学(CS)领域、新闻(NEWs)领域、评论(Reviews)领域,如图2所示。我们采取RoBERTa作为基准的预训练语言模型,其预训练语料库相比于BERT数量更大、更具多样性。

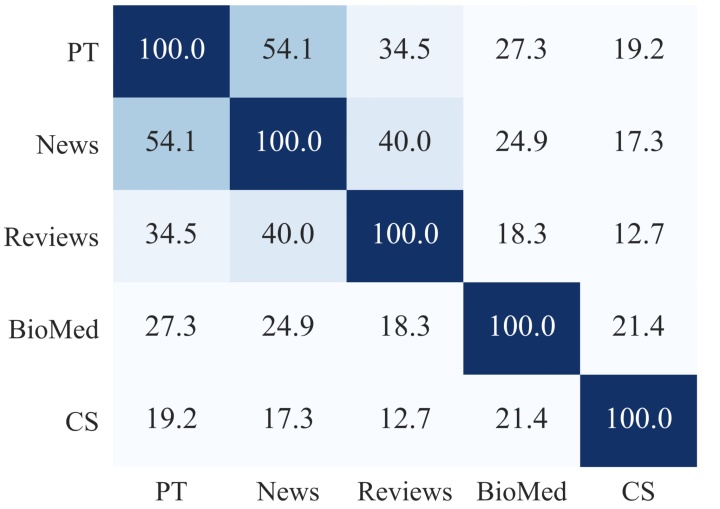
图3展示了不同领域间的词汇重叠度(选取每个领域TOP 10K个高频词,计算词汇重复度),可以发现RoBERTa语料与NEWs和Reviews领域相似度高,而与BioMed和CS领域相似度较低。我们可以预测:与RoBERTa的领域越不相似,领域自适应预训练的受益程度越高。
论文对每个领域选取2个特定分类任务进行实验,并进行了高资源和低资源(训练集标注量小于等于5000)配置,如图4所示:其中CHEMPROT、ACL-ARC、SCIREC、HYP为低资源设置。
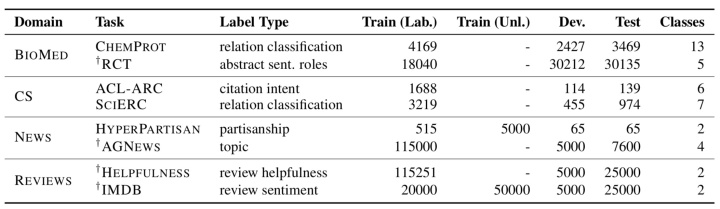
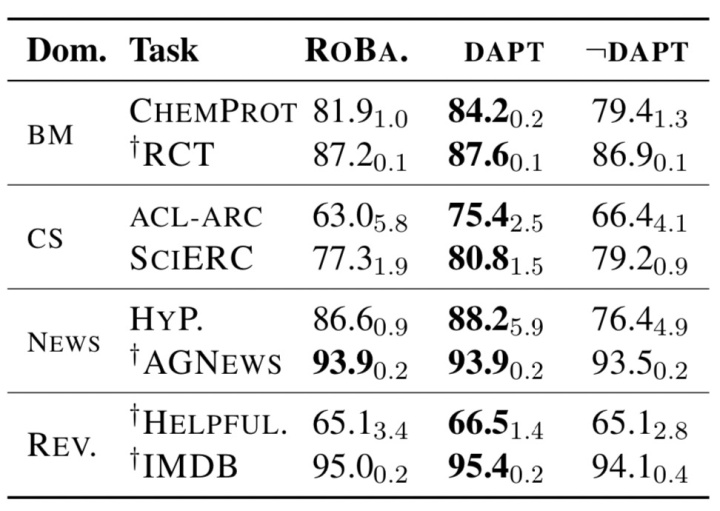
由图5可以看出无论高资源还是低资源条件,采用领域自适应预训练在4个领域对应的8个Task上性能均有增加(相较于RoBERTa直接对特定Task进行finetune),而低资源条件下增幅更具明显:尤其是BM、CS这两个领域,它们与RoBERTa的原领域相差较大,提升会更明显。
到这里,我们是否会存在这样一个疑问:是否只要在额外的语料库上持续进行LM预训练,性能就会提升呢?也就是说只要暴露更多的数据,就可以改进RoBERTa性能吗?
为检验上述猜想,论文继续进行了实验:将LM预训练继续应用于领域外(out domain)的语料库,记这一过程为¬DAPT。一个具体做法是:我们可以根据图3展示的领域间的重叠程度,选取与NEWs最不相关的CS领域的语料库继续进行预训练,然后在验证其在NEWs领域下的两个特定Task上finetune的效果。其余领域做法类似。
图5可以看出除了SCIERC和ACL-ARG任务外,域外¬DAPT下的性能相较于RoBERTa下降。因此,在大多数情况下,不考虑领域相关性而直接暴露于更多数据的持续预训练对最终任务性能是有害的;而在某些特例下(极少数情况),直接在额外数据下持续预训练也是有用的,文献[6] 中也有类似的观点。
2、任务自适应预训练
任务数据集可以看作相关领域中的一个子集,我们相信:对任务数据集本身或者与任务相关的数据继续预训练,对下游特定任务可能会有帮助。
任务自适应预训练(Task-Adaptive Pretraining ,TAPT),即在任务相关的无标注语料继续进行预训练,然后再对特定任务进行finetune。需要说明的是,与领域适应的预训练DAPT相比TAPT实质上进行了一种权衡:使用的预训练语料要少得多,但与特定任务相关的语料要多得多(假设训练集很好地代表了任务的各个方面),这是一种“廉价”的做法。

如图6所示,在8个特定任务上继续预训练(直接使用相应任务的标注数据当作无标注语料),TAPT都提高了相应的RoBERTa基准;特别是在NEWs领域的2个任务上(新闻领域也是RoBERT预训练语料库的一部分),TAPT也比RoBERTa有所提升。
从上述介绍可以得知,TAPT和DAPT之间有着明显的差异,DAPT具有更多的资源优势,但TAPT可以在某些任务(特别是在HYPERPARTISAN和HELPFULNESS)中超过了DAPT。可以看出,TAPT在某些任务上既“便宜”又有效!
图6也给出结合DAPT和TAPT的性能表现(在DAPT后,紧接着进行TAPT),除HYPERPARTISAN任务外,DAPT+TAPT都超过了单独使用DAPT或TAPT。我们猜测,如果是在TAPT后再进行DAPT,可能会对任务相关的语料存在灾难性遗忘问题;当然,也许对DAPT和TAPT进行更复杂的组合方式,效果会更佳。

图7给出了跨任务迁移的Transfer-TAPT实验:即在同一领域内,对某一任务进行TAPT预训练,然后在另一个任务上进行finetune。例如,在BioMed领域,进一步使用RCT未标注数据进行LM预训练,然后使用CHEMPROT标记的数据对其进行finetune并观察效果。我们可以看出Transfer-TAPT的性能均有下降,这表明:由于同一领域内、不同任务数据的分布不同,TAPT并不适合跨任务迁移,这也说明仅仅进行领域自适应的预训练DAPT是不够的,以及在DAPT之后再进行TAPT为什么是有效的。
3、针对任务自适应预训练的增强方法
上述分析表明,任务自适应预训练(TAPT)是一种廉价但有效的提升方法。但上述TAPT直接将标注数据当作无标注数据进行预训练,毕竟数据量还是较小的。而我们如果能够拥有更多的、任务相关的无标注数据,继续进行TAPT,效果又会如何呢?
下面分别介绍两种构造更多的、任务相关的无标注数据的增强方式:1)人工构造;2)自动数据选择。
3.1 Human Curated-TAPT
任务数据集的创建通常会通过人工方式从已知来源收集,其中通过下采样选取部分数据进行人工标注构建标注数据集,而剩下的未标注数据有时也是可用的。对人工构造的、可用的、任务相关的未标注数据进行任务自适应预训练,这一过程就是Curated-TAPT。
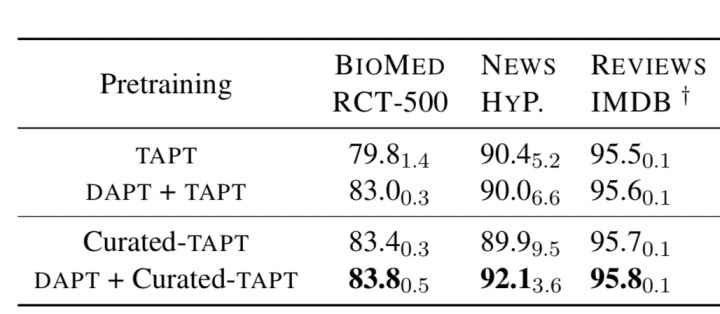
图8给出了Curated-TAPT的实验结果。其中RCT-500是保留原始标注集的500条标注数据,基于剩余的标注数据作为无标注数据进行Curated-TAPT;HYP和IMDB就是图4中直接给出的任务相关的无标注数据。
我们可以发现:除了HYP任务外,Curated-TAPT相较于TAPT均有提升,而Curated-TAPT也超过了DAPT+TAPT,可见如果我们能获取更多的、任务相关的无标注数据进行TAPT,效果不但提升明显,而且更为“廉价”、消耗资源低(后续图10会详细介绍这一点);而结合DAPT+Curated-TAPT在上述3个任务上效果均提升,特别是HYP任务更为明显,从90提升至92.1.
可想而知,如果我们在设计相关任务时,能够释放大量的、任务相关的无标注数据集,并继续进行预训练(TAPT),对于最终任务是极其有利的。
3.2 Automated Data Selection for TAPT
本小节考虑一个资源短缺的情况,当我们任务设计者没有释放更多的、任务相关的无标注数据时,我们怎么能够通过TAPT受益?

论文采取的方法也很简单,即设计一种简单的、轻量化的自动数据选择方法。具体地,如图9所示,例如对于BioMed领域的ChemProt任务,采取VAMPIRE [7](一种轻量化的词袋语言模型)对1百万的领域数据进行预训练,然后将ChemProt任务中无标注的句子嵌入到VAMPIRE向量空间。通过kNN最近邻方法,选取k个最相似的、BioMed领域内的句子作为任务相关的无标注数据,然后进行TAPT(这里表述为kNN-TAPT)。
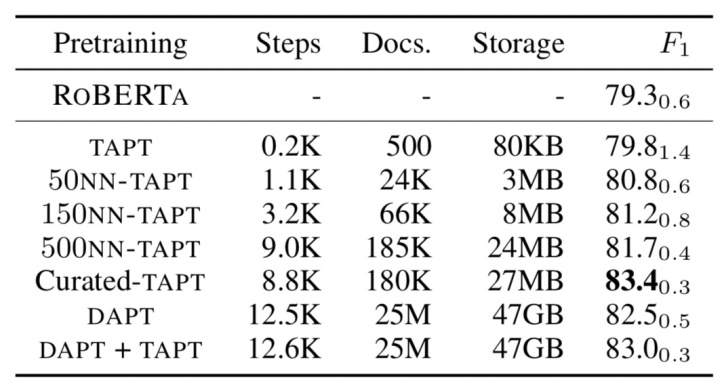
图10给出了不同TAPT方式的实验结果。通过自动选择方法进行的kNN-TAPT相比于TAPT效果提升明显;各种TAPT会比DAPT更为廉价:TAPT训练会比DAPT快60倍。Curated-TAPT表现最佳,但需要考虑在大型领域内人工构造任务相关的无标注数据的成本,不过这样的成本相比较于标注成本也是微不足道了。所以,我们最好在设计任务时能够释放更多的、任务相关的无标注数据,以便于进一步进行TAPT预训练。
总结
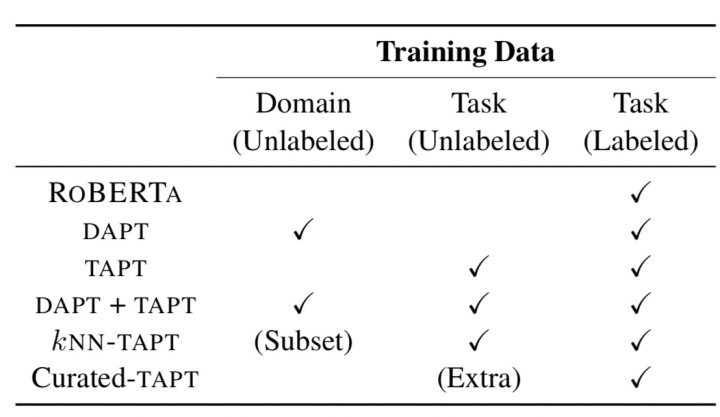
图11很清晰地给出了不同阶段的预训练策略,例如,kNN-TAPT要在领域内选取与任务相关的数据,这是领域数据集的一个子集,然后进行TAPT和finetune;Curated-TAPT要额外构造任务相关的无标注数据集,然后进行finetune。
本篇论文的相关实验表明:即使是具有数亿个参数的语言模型也难以编码单个文本域的复杂性,更不用说所有语言了。继续在目标领域和任务进行预训练可以带来明显的受益。
论文也给出未来的研究方向:如何采取一个更有效的数据选择方法,来构建更多的、任务相关的无标注数据,有效地将大型预训练语言模型重构到更远的domain,并且获得一个可重用的语言模型。
最后,笔者还是要重申一个不成熟的小建议:当我们所执行任务的标注数据较少,所属的领域与初始预训练语料越不相关,而又能获取到充分的、任务相关的无标注数据时,那就不要停止领域预训练和任务预训练!
看了这篇对获得ACL2020最佳论文提名奖的paper的解读,你有何感想呢~欢迎下方留言,我们一起讨论吧~
Reference
[1] Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks
[2] PTMs:NLP预训练模型的全面总结( https:// zhuanlan.zhihu.com/p/11 5014536 )
[3]BioBERT: a pre-trained biomedical language representation model for biomedical text mining.
[4]SciBERT: A pre-trained language model for scientific text
[5] ClinicalBERT: Modeling clinical notes and predicting hospital readmission.
[6] Cloze-driven pretraining of self-attention networks.
[7] Variational pretraining for semi-supervised text classification.
[8] GPT:Improving Language Understanding by Generative Pre-Training














 3518
3518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









