






本文提出了一种建模动作预测问题的全新范式:掩码动作补全。只需要一个loss、训练一个阶段就可以实现预测,|人体动作预测新范式
主页: https://lhchen.top/Human-MAC
论文:https://arxiv.org/pdf/2302.03665.pdf
代码:https://github.com/LinghaoChan/HumanMAC
人体动作预测是计算机视觉和图形学中的一个经典问题,旨在提升预测结果的多样性、准确性,并在自动驾驶、动画制作等多领域有非常多具体的应用。本研究梳理了今年来大家对于该问题的建模方式,认为以往的大多数工作对于动作预测任务都是使用一种encoding-decoding的范式。这类范式大多是将观测帧编码进隐空间,然后从隐空间解码出预测帧。我们认为这种方式存在三个缺点:
- 大多数SOTA的方法需要多个loss作为目标约束,需要精细化地调节多个loss之间的权重,需要极其繁重的调参工程。
- 大多数SOTA的方法需要多阶段训练,特别是需要预训练encoder和decoder,这使得预测结果非常依赖于预训练的质量。
- 对于这些方法来说,很难实现不同类别运动的切换,例如从“WalkDog”到“Sitting”的切换,这对于结果多样性至关重要。出现这个现象的原因是这些方法所使用的训练数据包括很少这样的切换。
为克服上述问题,我们提出了一种建模动作预测问题的全新范式:掩码动作补全。如图1(b)所示,我们认为预测问题就是一种特殊的补全问题,可以借助diffusion model的补全能力解决上述挑战。如果使用这种范式,我们是需要一个loss、训练一个阶段就可以实现预测,可以说是“大道至简”。并且由于我们建模了全局的动作,模型很容易学习到平滑性,就能自动实现动作的切换。
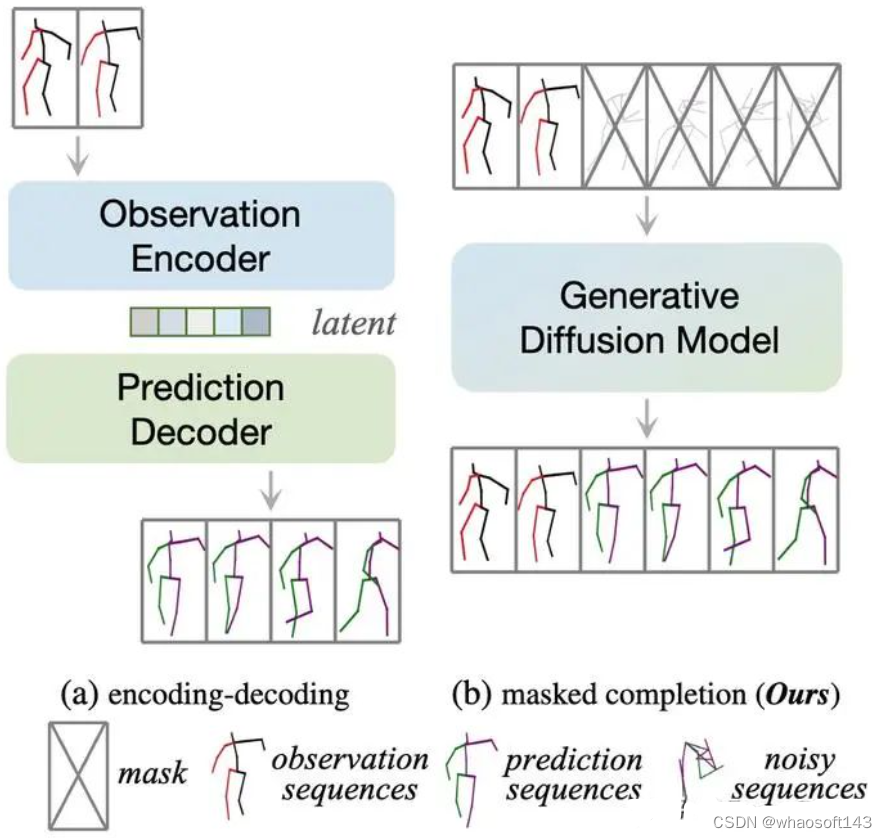
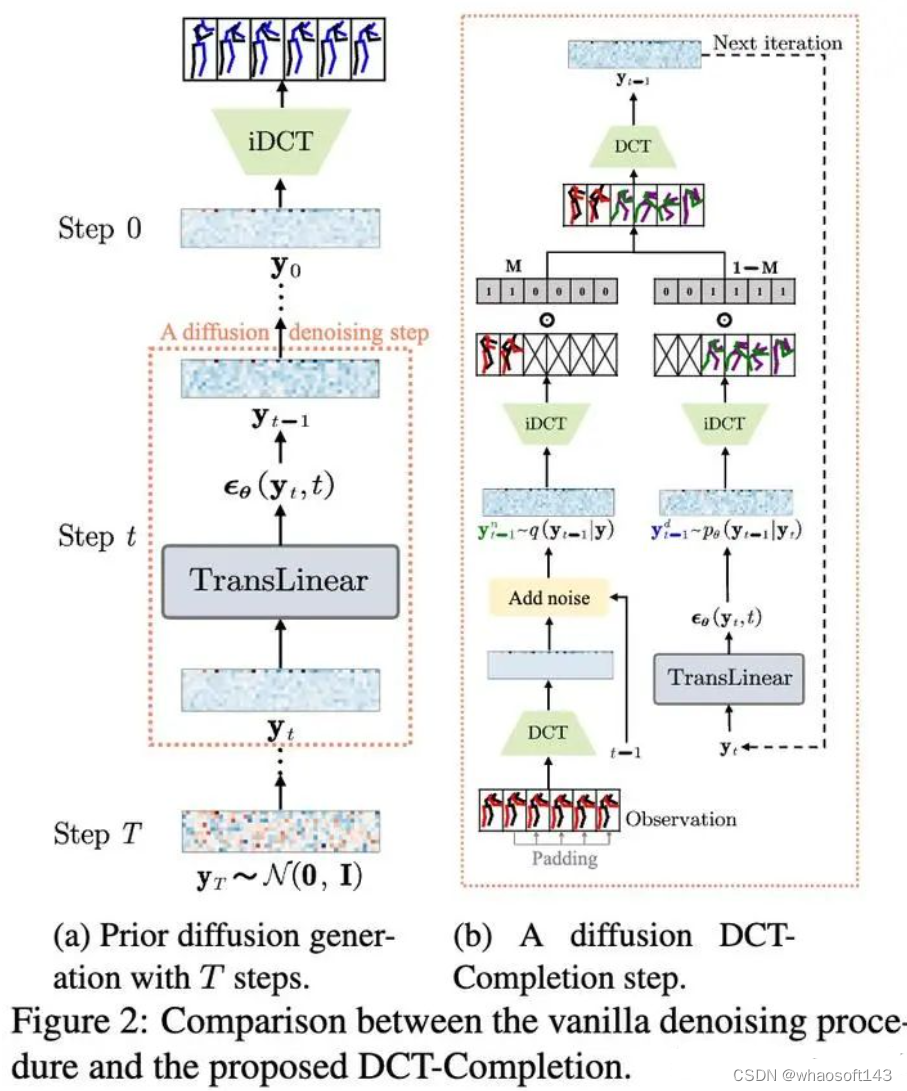
encoding-decoding方式与掩码运动补全的比较。(a)encoding-decoding的方法将观测帧显式地编码到隐空间,然后将隐空间变量解码为预测结果。(b)HumanMAC在训练阶段由噪声生成运动。在推理阶段完成补全动作的任务。为了解决动作抖动等问题,我们借鉴了以往工作在频域建模的思路[5][6],通过DCT变换,对数据在频域进行训练。也就是说,我们的diffusion model是动作频谱的生成模型,在输出结果的时候只需要做iDCT变换即可复原动作。为此,我们设计了一个补全算法:DCT-Completion。算法流程和示意图如下。

由于动作预测的问题只是一个特殊的掩码补全问题,我们可以灵活地使用mask实现各种“花式”可控动作补全:
- 动作切换
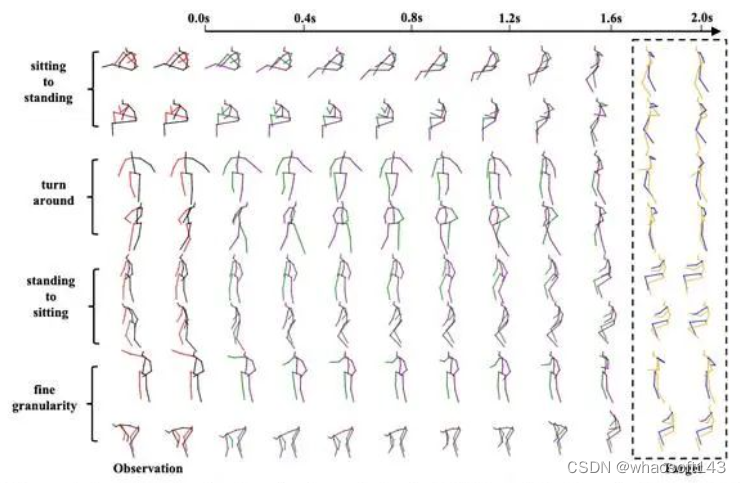
- 动作切换
- 特定躯体可控动作编辑
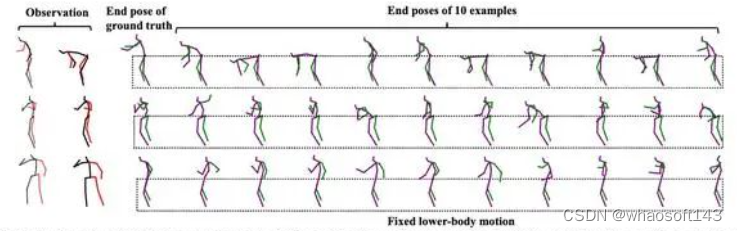
- 特定躯体可控动作编辑
在量化指标上我们仅仅通过一个loss、一阶段训练就可以和以往的工作不相上下了(我们还比较了最新的arxiv算法)。多样性的指标逊色于baseline方法的原因,主要来自于baseline方法生成的“多样”结果存在大量的failure cases,详情可以见论文和demo中的可视化结果比较。
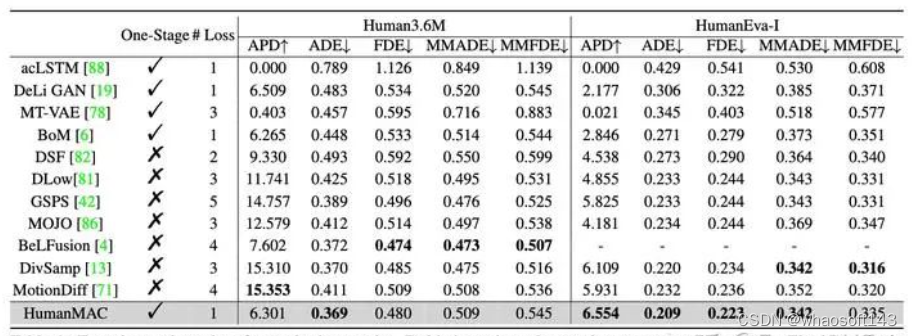
主实验结果
在正文中,我们对网络结构、DCT设计、频谱频段选择、网络结构、采样步数、噪声建模等进行了精细的消融验证。同时,由于以往研究的codebase计算效率太低,我们重新优化了评估代码并开源(加速上千倍),为后续研究者提供便利。
为了探究模型的泛化性能,我们还做了在H3.6M数据训练,在AMASS上做zero-shot预测实验的研究,效果也特别好。
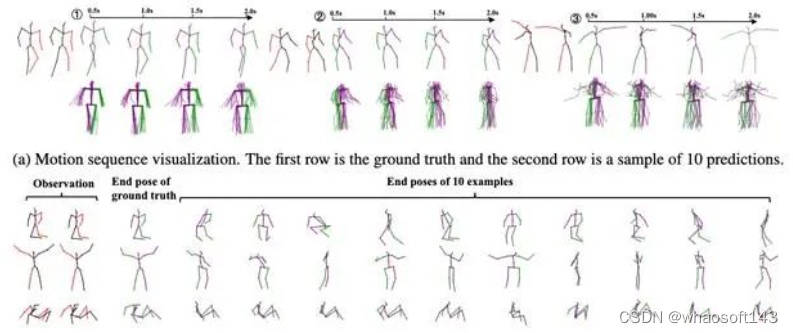
AMASS上的zero-shot预测实验
https://github.com/LinghaoChan/HumanMAC
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









