






在了解HDFS之前,我们先来简单介绍一下Hadoop:Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。从中我们可以看出Hadoop其实可以大致分为两个方面:大数据和大计算。Hadoop的框架最核心的设计就是:HDFS、MapReduce和Yarn。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算,Yarn则是提供资源调度。
一、HDFS概述
HDFS是为海量的数据提供了存储的分布式文件系统。它是大数据系统的基础,它提供了基本的存储功能,由于底层数据的分布式存储,上层任务也可以利用数据的本地性进行分布式计算。hdfs思想上很简单,就是NameNode负责数据存储位置的记录,DataNode负责数据的存储。
读数据的时候:使用者Client会先访问NameNode询问数据存在哪,然后去DataNode存储;
写数据也基本类似:会先在NameNode上询问写到哪,然后把数据存储到对应的DataNode上。所以NameNode作为整个系统的灵魂,一旦它挂掉了,整个系统也就无法使用了。在运维中,针对NameNode的高可用变得十分关键,关于NameNode的高可用本文后面我们会讲到。
二、文件命名空间
HDFS支持传统的继承式的文件组织结构。一个用户或一个程序可以创建目录,存储文件到很多目录之中。文件系统的名字空间层次和其他的文件系统相似。可以创建、移动文件,将文件从一个目录移动到另外一个,或重命名。HDFS还没有实现用户的配额和访问控制。HDFS还不支持硬链接和软链接。然而,HDFS结构不排斥在将来实现这些功能。
三、HDFS组件介绍
HDFS采用的是master-slave架构,这种架构是典型的主从结构模型,在HDFS中,扮演master角色的是NameNode,扮演slave角色的是DataNode。
先来看看NameNode和DataNode各自的职责以及Block数据块
Namenode 的职责
1. 存放文件系统树及所有文件、目录的元数据,
2. 维护文件系统的命名空间,任何文件命名空间的改变和属性都被NameNode记录。
3. 应用程序可以指定文件的副本数,NameNode负责管理副本策略(默认是3个副本)
4. 处理客户端的读写请求
DataNode 的职责
1. DataNode负责存储和读取Block,读写请求可能来自NameNode,也可能直接来自客户端。
2. DataNode周期性会向NameNode汇报自己节点上所存储的Block相关信息和自身运行的状态。
3. 在集群启动的时候,DataNode向NameNode提供Block数据块列表信息。
Block数据块
Block数据块是HDFS最小的存储单元,写入HDFS的文件会被切分成一个个固定大小的块(block),hdfs2.0之后每个块的大小默认是128MB(2.0之前默认是64MB),然后将每个数据块依次发送到 DataNode 中,集群运行时数据块的存储位置等信息由 NameNode 记录在元数据中。
为了提高系统的容错性,保证数据有足够多的副本,每个块又会被复制到多个DataNode上存储。具体复制副本是在数据存储的时候,服务器会进行一个异步的操作,将这个块再进行复制操作,随机存储到一个 DataNode 中(这里随机存储是为了保证服务器的负载均衡,避免多个客户端对同一个文件进行访问,这个文件和其副本都存储在同一个 DataNode 节点上的情况)。
这里需要注意的是:1.如果存储的文件小于一个Block数据块的设置大小,则不会占用整个块的空间(假如存储10MB的文件,存储的时候不会再被切分,占用的磁盘空间是10MB,而不会占用整个块的128MB)
四、架构详解
首先了解一下NameNode中的两种元数据文件:
fsimage:文件系统元数据检查点镜像文件(合并edits的一个同步点),保存了文件系统中所有的目录和文件信息,如:一个目录下有那些子目录、子文件、文件名、文件副本数、文件由哪些数据块组成
edits:编辑日志,客户端对目录和文件的写操作,先被记录到edits日志文件中,如:创建文件,创建文件夹、删除文件等
NameNode内存中保存的一份最新的镜像文件 = fsimage + edits
NameNode定期将内存中的新增的edits于fsimage合并保存在磁盘中
4.1 一个HDFS集群是由一个Namenode和一定数目的Datanodes组成,在HDFS中,为了实现高可用,通常会启用两个NameNode,一个是Active NameNode,一个是Standby NameNode。
在HDFS集群正常工作时,只有Active NameNode时处理读写请求的,Standby NameNode只是负责周期性的同步Active NameNode 的edits编辑日志,并且定期会合并fsimage和edits到本地磁盘,以保证Active NameNode挂掉后,Standby NameNode可以接替Active NameNode保证集群可以正常的对外提供服务,保证集群的高可用。(关于高可用我们后面会详细介绍)
4.2 HDFS文件系统和Linux文件系统相似,也是通过文件和目录来管理的,所有的文件和目录的层级关系可以看作是一个文件树。
其中NameNode维护着文件系统树,及整颗树内所有的目录和文件,这些信息以命名空间镜像文件fsimage 和 编辑日志文件edits ,永久保存在本地,但是为了快速访问,在集群运行的时候,会把这些命名空间信息加载到内存当中。
fsimage 并不存储Block块和DataNode的映射关系,NameNode是通过DataNode周期性的汇报心跳信息里得知每个DataNode储存的Block块列表信息,然后进行构建数据块和DataNode的这样也能够保证NameNode可以获得最新的数据块Block的信息。
4.3 NameNode会根据DataNode汇报的信息去了解DataNode的运行状态,如果某个DataNode挂掉了,或者是一段时间内,DataNode由于其他原因没有向NameNode汇报心跳(即心跳超时),那么NameNode就会认为这个DataNode不可用了,然后就把这个DataNode标记为死亡,并且不会向这个DataNode转发任何客户端的读写请求。
与此同时,一旦某个DataNode不可用了,那么存储在这个DataNode上的Block块信息也就不可用了,那么NameNode就会检测Block副本数是否低于正常水平,如果是,NameNode就会复制新的副本向其他正常的DataNode上,以保证副本数恢复正常。
4.4 在处理客户端的读写请求的时候,客户端并不直接和DataNode通信,先通过NameNode获取到元数据信息,ram就客户端再和DataNode进行通信,进行对数据块的读写操作.
五、了解一下HDFS的操作
HDFS的操作类似于linux命令,只不过在前面加上了 “hadoop fs -”的固定写法
举例1:查看根目录下的文件列表
hadoop fs -ls /
举例2:查看hsfs中test.txt文件内容:
hadoop fs -cat /test.txt
这里只是举例说明,大家可以自己多使用操作一下其他操作命令。
六、HDFS 不适合存储小文件
6.1 元数据信息都存储在NameNode中,由于内存大小是有限的,所以在NameNode中存储的Block元数据的数目是有限的
举个例子说明下:
1个Block的元数据信息需要在占用大约150byte的内存。
存储1亿个Block的元数据就需要占用大约20GB的内存。
如果1个文件大小为10KB,那么1亿个这样的文件所占用的内存为1TB,尔NameNode却需要20GB的内存来存储元数据信息。
6.2 存取大量的小文件也会消耗大量的磁盘寻道时间。
七、HDFS高可用实现原理
在HDFS中,NameNode保存了整个HDFS中的元数据信息,一旦NameNode挂掉了,那么整合HDFS集群就无法访问了。同时在Hadoop生态中所有依赖于HDFS的组件比如说MapReduce,Hive,HBase就都无法正常工作了,如果集群运行了很长时间,那么此时HDFS存储的数据量就非常大,当重启NameNode时,需要从DataNode获取回报信息进行数据恢复,由于数据量大,数据恢复时候也是非常耗时的。
由于这个缺点的存在,也极大的限制了Hadoop的使用场景,使得Hadoop之前在很长的时间内只能用作离线存储和离线计算,无法应用于对可用性和数据一致性要求比较高的在线应用场景中。
在Hadoop2.0之后,引入了基于QJM共享存储系统,实现了基于QJM的高可用机制
前面我们就介绍过,在HDFS中,为了实现高可用,通常会启用两个NameNode,一个是Active NameNode,一个是Standby NameNode。
在HDFS集群正常工作时,只有Active NameNode时处理读写请求的,Standby NameNode只是负责周期性的从QJM共享存储系统中同步Active NameNode 的edits编辑日志,并且定期会合并fsimage和edits到本地磁盘,以保证数据的一致性,当Active NameNode挂掉后,Standby NameNode可以接替Active NameNode保证集群可以正常的对外提供服务,保证集群的高可用。
先了解一下QJM(Quorum Journal Manager) 共享存储系统:
QJM (Quorum Journal Manager)共享存储系统:我们在搭建HDFS集群的时候(一般是奇数台,最少3台),在每台服务器上启动一个JournalNode,组成一个QJM共享存储系统,这个系统非常轻量级,一般不会出现问题。
我们一般在两台NameNode的机器上各启动一个JournalNode,然后在第三台机器上再启动一个JournalNode,这样就由三个节点成了QJM 共享存储系统,在QJM中主要存储edit log编辑日志。
Active NameNode在接收客户端的写请求(创建文件、移除文件等)的时候,会首先将这些操作记录edit log 编辑日志中,同时也会同步阻塞并行的向JournalNode集群中的每一个JournalNode发送写请求,如果大多数JournalNode节点能够写成功,就说明JournalNode集群写入edit 成功了,最后修改内存中的元数据
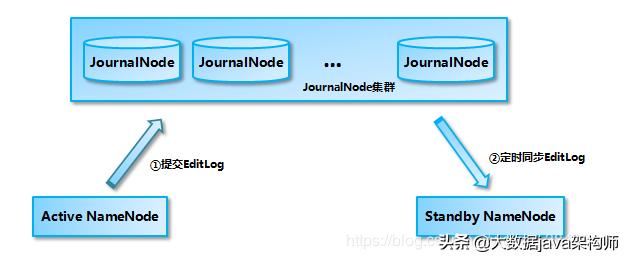
Active NameNode会定期对文件系统命名空间创建检查点,并在磁盘当中生成fsimage这个镜像文件,进行持久化存储
Standby NameNode 从JournalNode集群中定期的同步编辑日志edit,然后把同步过来的编辑日志会放在自己的内存当中,Standby NameNode 也会定期的创建检查点,生成fsimage,进行持久化存储。
这样说来,Active NameNode和Standby NameNode 通过共享QJM共享存储系统来实现元数据的同步。
那么接下来说一下NameNode是怎么进行主备切换的?先看张图如下:

NameNode主备切换主要是由主备切换控制器ZKFC(ZKFailoverController)控制的,当我们在启动NameNode的时候,也会在该节点上启动一个ZKFC守护进程,这个进程是作为主备切换控制器。
在ZKFC启动的时候,ZKFC会创建两个内部的组件 HealthMonitor 和 ActiveStandbyElector 。
HealthMonitor:它主要负责循环检测NameNode的健康状态
ActiveStandbyElector:它主要负责使用Zookeeper来完成主备选举
每个NameNode在启动ActiveStandbyElector的时候们都会向Zookeeper来竞争的创建临时锁节点(利用zookeeper的写一致性),哪个ActiveStandbyElector创建成功了,哪个ActiveStandbyElector锁对应的NameNode就会被选为Active NameNode。
这里需要注意的是,无论ActiveStandbyElector有没有创建成功临时锁节点,ActiveStandbyElector都会向Zookeeper注册监听事件,来监听这个临时锁节点的删除事件。
a. 如果Active NameNode节点对应的HealthMonitor检测到状态异常,那么对应的ZKFC就会删除之前在Zookeeper中创建的临时锁节点,那么此时Standby NameNode对用的ActiveStandbyElector就会收到这个删除事件,然后马上进入创建临时锁节点的流程,创建成功之后,那么本来处于Standby状态的NameNode就被选举为Active,并切换状态为Active
b. 如果Active NameNode挂掉了,那么对应的临时锁节点也会自动删除,从而自动进行主备切换。
小结
关于HDFS的讲解就结束了,希望大家仔细看过会有所收获,















 279
279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









