







概述
本文从简化概念、帮助理解作为出发点,对SQL性能优化的概念做一些总结,目的是让读者知道SQL性能优化大概是什么样的一个过程。
为了简化篇幅,减少信息量,一些优化工具、方法也不作展开说明,仅作简单的介绍;性能问题的示例也尽可能从简(我们遇到的SQL性能问题,实际上比本文示例的情况复杂得多)。
在本文中,“SQL性能优化”都特指针对Oracle数据库中的SQL性能优化。
概念结构
关于SQL性能优化,基本就以下几个关键点:
1.SQL优化的本质
2.理解SQL性能问题
3.收集SQL性能问题信息
4.分析问题
5.优化思路&手段
优化本质
SQL查询时,主要的动作是:扫描数据、处理数据(筛选、汇总、去重等)、返回数据(到客户端)。
其中,扫描数据主要是IO操作,其他操作基本都是CPU操作,如果整个SQL查询耗时过长,除去网络因素,IO(这也是当前计算机硬件部分的瓶颈)是占用时间最多的原因(SQL语句中嵌入了PL/SQL代码这种特殊情况除外)。
所以SQL性能优化的本质就是:尽可能减少SQL查询过程中不必要的IO操作。
瞄准这个目标,我们应该就知道SQL性能优化的学习方向是:如何减少SQL查询不必要的IO操作。
理解SQL性能问题
SQL性能问题的本质就是: 查询目标数据所需要扫描的数据块(IO操作)过多。 在一篇写得很好的SQL优化指引手册的指引下,我们是可以做到在未掌握甚至未接触过SQL性能优化的情况下解决一些SQL性能问题。 但如果想真正掌握SQL性能优化,我们还是先得理解问题本质,即当我们说一段SQL存在性能问题时,其问题本质是什么。那么问题来了:
什么是数据块?
SQL查询跟数据块有何关系?
为什么会扫描到过多数据块?

为了便于理解,这里用“快递员取件”打个简单的比方。
在某个时刻,某个快递员需要在他所负责的片区收取100个大小不同的包裹,这100个包裹分散在10个不同的地点。他规划好路线之后,先后开车到这10个地点取到了包裹。
在本例中:
1.数据块
10个取件地点就相当于数据块,快递员要取到包裹,需要抵达取件地点,SQL要查询到目标数据,需要扫描数据块(实际上SQL查询时,从数据块中读取到的数据可能还需要经过筛选条件过滤);2.目标数据
100个包裹就相当于SQL查询的目标数据;3.需要扫描的数据块
从出发到取完所有的包裹,期间的油耗就相当于扫描过的数据块。
问题:
1.路程长短
不难理解,如果路线规划得不好,显然会绕路,走过的路程就会越长,油耗就会越高;
2.取货顺序
如果快递员抵达的第一个收件点有91个又重又大的包裹,剩余的9个收件地点都只有一个又轻又小的包裹,那么就算他规划的路线再优,走过的路程是最短的,也不见得是一个最佳的结果,因为托着那么多的包裹走这么一段路,油耗反而可能变高了。
所以,SQL性能优化,就类似本例中“如何达到最低的油耗”的规划,不仅仅要考虑路程长短,还得根据包裹的分布情况考虑取货顺序。 上述例子只是为了帮助读者对SQL性能问题有个感性的认识,可能并不那么贴切,SQL性能问题要复杂得多。要真正理解SQL性能问题,我们至少需要掌握以下几个知识点:1.数据(表、索引)存储结构(表、索引是如何存储的)
2.SQL执行原理(一段SQL在执行期间,究竟干了什么事情)
3.执行计划(告诉SQL查询程序从哪张表开始扫描,然后按什么顺序以什么关联方式关联下一张表,每张表是走索引还是走全表扫描,走索引的时候该怎么走,数据是否需要去重/汇总等等)
4.优化器(生成多个执行计划,并从中选择优化器认为成本最低的执行计划)
表、索引的逻辑存储结构
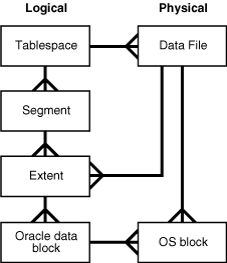

当某张表中新增数据时,会发生什么事情:
1.数据根据数据内容的大小,申请若干逻辑上连序的数据块用于存储数据,这部分连序的数据块就是“区”(Extent,逻辑上连序数据块)
2.数据最终以数据块(Data block)的形式存储到磁盘上(数据块是最小的存储单位)
3.表新增数据时,对应的索引也会新增数据,表和索引都各自以“段”(Segment)为逻辑单位进行存储(不考虑分区的情况,一张表为一个段,一个索引也为一个段),申请新的区用于存储新数据时,这些区也是分别隶属于表段和索引段中。
4.段只能隶属于一个表空间(Tablespace),但表和索引可以存储在不同的表空间中,随着表空间内容的增长,表空间的内容会存储到新的数据文件中。
结合上面两张图,我们不难想象,表、索引中包含的成千上万的数据,最终都以数据块(类似小方格)的形式存储在磁盘上。
由于每张表字段的数量、内容都不尽相同,同样的行数,在不同的表中会对应不同数量的数据块;但数据块相同,数据量(以磁盘空间大小为计量单位)的大小基本就是相同的。
所以在了解到这些知识之后,我们在分析SQL性能问题(执行计划)时,应该对这两个重要的指标有一个感性的认识:数据块和行数。
详细信息可参考官方文档:
Logical Storage Structures(逻辑存储结 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2336
2336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









